낙관적 프라임‑듀얼로 안전한 LLM 정렬의 마지막 반복 수렴을 보장한다
본 논문은 인간 피드백을 활용한 대형 언어 모델(LLM) 정렬을 제약 최적화 문제로 모델링하고, 기존 프라임‑듀얼 방법이 마지막 반복에서 발산하거나 진동하는 한계를 극복하기 위해 낙관적(Optimistic) 프라임‑듀얼(OPD) 알고리즘을 제안한다. OPD는 프라임과 듀얼 변수 모두에 예측 업데이트를 도입해 회전형 동역학을 억제하고, 분포 공간에서는 정확한 마지막 반복 수렴을, 파라미터화된 정책 공간에서는 근사 오차와 편향에 비례하는 근방 수…
저자: Yining Li, Peizhong Ju, Ness Shroff
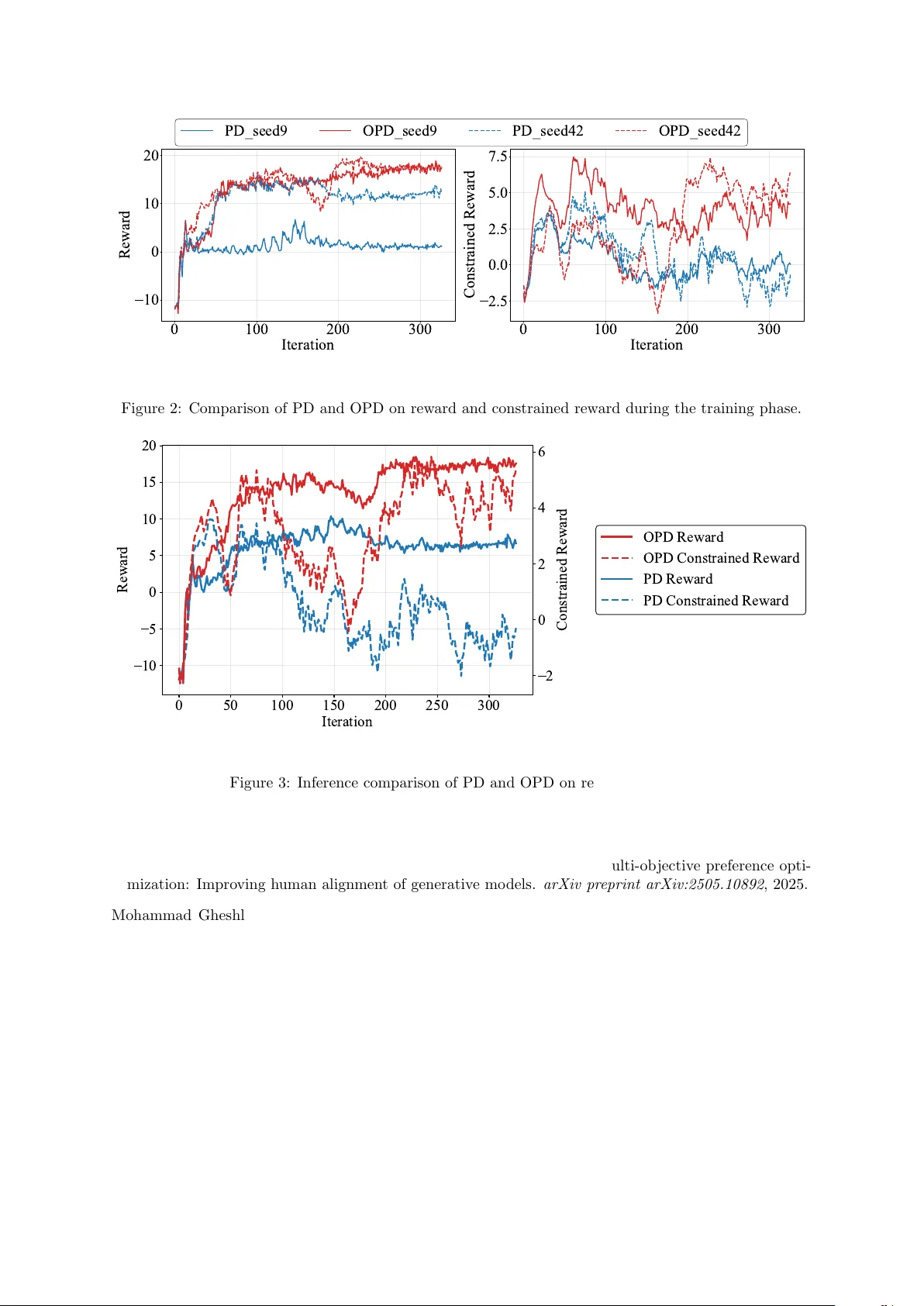
본 논문은 대형 언어 모델(LLM)의 안전 정렬을 위해 ‘제약 강화학습(RLHF)’을 수학적으로 정형화하고, 기존 프라임‑듀얼 방법이 갖는 마지막 반복 수렴 부재 문제를 해결하고자 한다.
1. **문제 정의 및 배경**
- LLM은 유용성은 높지만, 허위·유해·프라이버시 침해 등 위험성을 내포한다. 인간 선호는 다중 속성(도움, 간결성, 사실성, 무해성)으로 구성되며, 이들 속성은 종종 상충한다. 따라서 단일 보상 최적화가 아닌, ‘주요 목표(예: 도움)’를 최대화하면서 ‘제약(예: 안전)’을 만족시키는 다목적 RLHF가 필요하다.
- 기존 RLHF는 인간 비교 데이터를 Bradley‑Terry 모델로 학습한 보상 함수를 이용해 정책을 강화학습한다. 제약을 포함하면 라그랑주 형태의 saddle‑point 문제로 변환된다.
2. **보편적 라그랑주 정렬 프레임워크**
- 논문은 모든 기존 제약 RLHF 알고리즘을 ‘프라임‑듀얼’ 구조로 통합한다. 프라임 단계는 현재 듀얼 λ에 대해 Lagrangian L(π,λ)를 최대화하는 정책 업데이트(PrimalOracle)이며, 듀얼 단계는 제약 위반을 기반으로 λ를 투사 경사 하강(GradEst)한다.
- 프라임 Oracle은 (i) 한정된 SGD 스텝, (ii) 다중‑샷 내부 루프, (iii) 분포 공간에서의 닫힌 형태 해 등 다양한 구현이 가능하다. 이 프레임워크는 기존 ‘one‑shot dualization’, ‘multi‑shot inner‑outer loop’, ‘finite‑step primal‑dual’ 방식을 모두 포함한다.
3. **표준 프라임‑듀얼의 한계**
- 라그랑주가 π에 대해 강볼록(Strongly Convex)·λ에 대해 선형이지만, 실제 파라미터화된 정책에서는 비볼록성이 도입된다. 특히, 동시 업데이트는 bilinear 예시와 같이 회전형 고유값을 갖는 선형 시스템으로 변환돼 마지막 반복이 수렴하지 않는다. 평균 수렴만 보장되며, 실제 배포 모델은 마지막 반복을 사용하므로 이는 실용적 문제다.
4. **낙관적 프라임‑듀얼(OPD) 알고리즘**
- OPD는 현재 (πₜ, λₜ)에서 다음 단계의 기울기를 예측하고, 예측값을 이용해 임시 변수 (π̂ₜ, λ̂ₜ)를 만든다. 실제 업데이트는 이 임시 변수와 현재 변수 사이에 KL·거리(π)와 L2·거리(λ) 정규화를 추가해 보정한다. 구체적 식은 (4)–(7)에 제시된다.
- 이 ‘예측‑보정’ 메커니즘은 기존 경사 상승/하강이 만든 회전 흐름을 감소시켜, 고유값의 실수부를 음수 영역으로 이동시킨다. 따라서 선형 수렴이 가능해진다.
5. **이론적 결과**
- **분포 공간**: 라그랑주가 π에 대해 β‑KL 정규화로 강볼록성을 갖는다고 가정하고, Slater 조건을 만족하면 OPD는 고유한 saddle‑point (π*, λ*)에 마지막 반복까지 선형 수렴한다.
- **파라미터화된 정책**: 실제 정책 π_θ는 비볼록이므로, 최적화 오차 ε_opt와 통계적 추정 오차 ε_stat, 모델 편향 ε_bias를 포함한 근방 수렴을 보인다. 즉, ‖π̂_T−π*‖ ≤ C·(ε_opt+ε_stat+ε_bias) 형태의 상한을 제공한다.
- 또한, 듀얼 변수에 대한 투사 연산과 KL·정규화 파라미터 η_θ, η_λ가 적절히 선택될 경우 수렴 속도는 O((1−c)ᵗ) 형태의 선형 감쇠를 보인다.
6. **실용적 의미와 한계**
- OPD는 ‘one‑shot’ 방식이 요구하는 닫힌 형태 해가 없으며, ‘multi‑shot’ 내부 루프를 완전하게 수행할 필요도 없다. 따라서 계산 비용이 크게 감소한다.
- 그러나 논문은 실제 LLM 실험(예: GPT‑4 기반 모델)이나 베이스라인과의 정량적 비교를 제공하지 않는다. 또한, β, η, 학습률 스케줄링 등에 대한 실전 가이드라인이 부족하다. 이러한 점은 향후 연구에서 보완될 필요가 있다.
7. **결론**
- 저자는 안전 RLHF를 위한 보편적 프라임‑듀얼 프레임워크를 제시하고, 낙관적 업데이트를 통해 마지막 반복 수렴을 이론적으로 보장하는 OPD 알고리즘을 개발했다. 이는 제약식 LLM 정렬에서 발생하는 진동·발산 문제를 근본적으로 해결할 수 있는 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기