SWE‑프로테제: 소형 언어 모델을 전문가와 협업시켜 소프트웨어 엔지니어링 에이전트로 만든다
소형 언어 모델(Qwen2.5‑Coder‑7B)을 전문가 모델(Claude Sonnet)과 선택적으로 협업하도록 학습시켜, 장기 소프트웨어 수리 작업인 SWE‑bench Verified에서 Pass@1 42.4%를 달성하였다. 루프 방지와 전문가 호출을 최소화하는 보상 설계가 핵심이며, 평균 4회·전체 토큰 11% 수준의 저비용 전문가 활용을 구현한다.
저자: Patrick Tser Jern Kon, Archana Pradeep, Ang Chen
본 논문은 소형 언어 모델(SLM)이 비용·지연·적응성 측면에서 큰 장점을 가지고 있음에도 불구하고, 복잡하고 장기적인 소프트웨어 엔지니어링 작업, 특히 SWE‑bench와 같은 코드 수리·디버깅 벤치마크에서는 행동 루프와 낮은 해결률이라는 심각한 한계를 보인다는 점을 출발점으로 삼는다. 기존의 데이터‑스케일링 기반 사후 학습(SWE‑smith 등)은 대형 모델에 비해 충분히 효과적이지 못했으며, 오히려 스케일을 늘릴수록 성능이 퇴보하는 현상이 관찰되었다. 이러한 문제를 해결하기 위해 저자들은 “전문가‑프로테제” 협업 패러다임을 제안한다. 여기서 SLM은 **주된 의사결정자**로 남으며, 필요할 때만 강력한 전문가 모델(Claude Sonnet)에게 질의를 보내고, 전문가의 피드백을 인식·추적·실행한다.
### 프레임워크 설계
SWE‑Protégé는 두 단계의 사후 학습 파이프라인으로 구성된다.
1. **Phase I – Supervised Fine‑Tuning (SFT)**: 강력한 전문가 모델을 이용해 전문가 호출이 포함된 합성 궤적을 생성한다. 이때 전문가 모델은 실제 정답을 알고 있지만, 정답을 직접 노출하지 않도록 프롬프트가 설계된다. 생성된 궤적은 약 5 K개이며, 전문가 호출은 자연스럽게 희소하게 삽입된다. SLM은 이 데이터를 통해 **전문가 호출 메커니즘**(툴 호출 형식, 질문 구성, 컨텍스트 제공)을 모방한다. 이 단계에서는 “언제” 전문가를 호출할지는 학습되지 않는다.
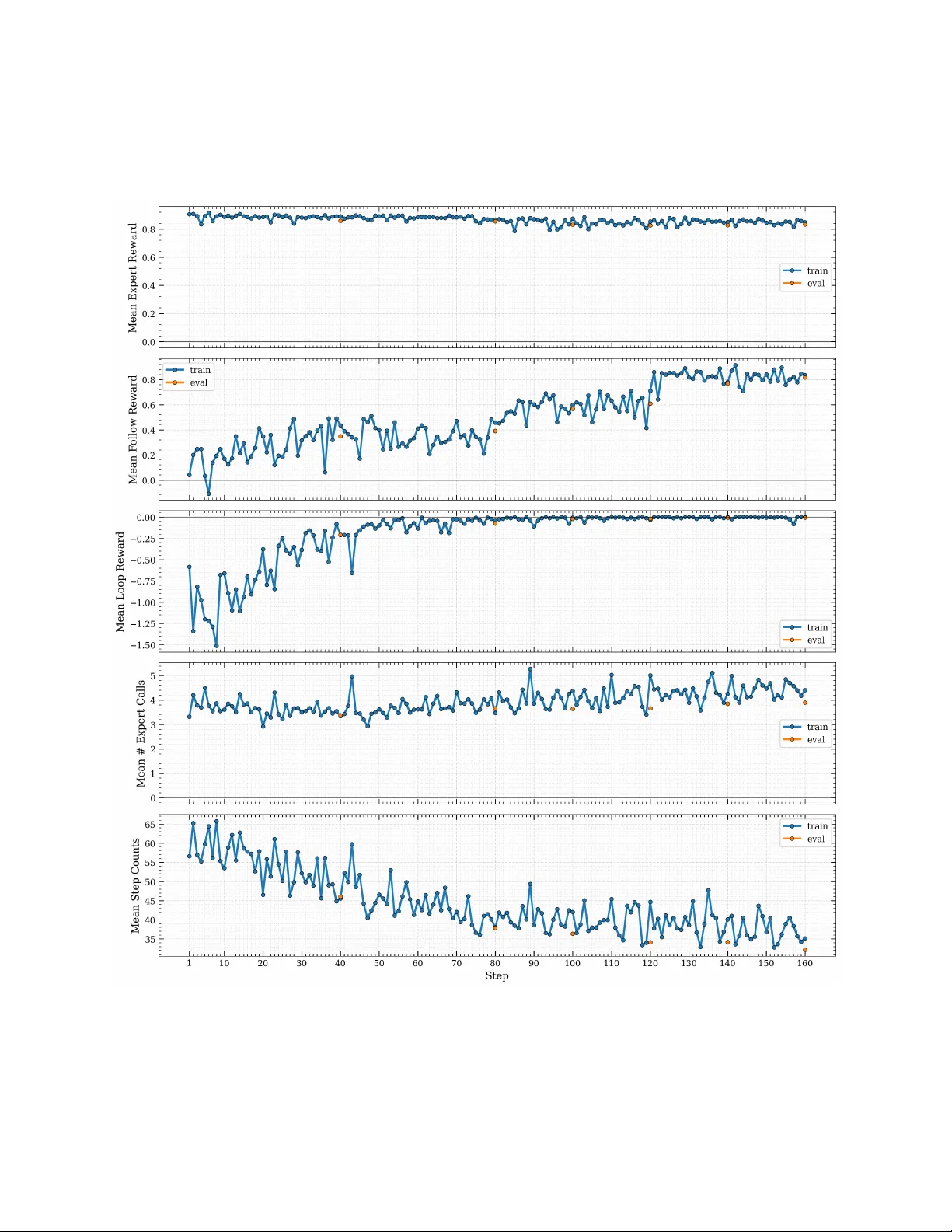
2. **Phase II – Agentic Reinforcement Learning (RL)**: SFT 체크포인트를 시작점으로, 루프 방지와 협업 품질을 명시적으로 보상하는 강화학습을 수행한다. 보상 구조는 복합적이다. `R_loop`는 동일 명령 반복을 음성화해 루프를 억제하고, `R_expert`는 전문가 호출이 정당했는지(`u_i`)를 점수화한다. `R_follow`는 전문가가 제공한 조언을 실제 행동(`Δ_i`)에 반영했는지(`f_i`)를 평가한다. 추가로 `R_correct`와 `R_sim`은 최종 패치 정확도와 기존 솔루션과의 유사성을 보상한다. 두 단계의 보상 셰이핑(첫 단계는 루프 억제, 두 번째 단계는 루프+팔로우 억제)으로 모델은 “정체 감지 → 전문가 호출 → 다턴 추적·보고” 흐름을 점진적으로 학습한다.
### 전문가 호출 메커니즘
행동 공간에 `ask_expert` 토큰을 추가하고, 호출 시 최근 5턴(요약된 `~s`)만을 전문가에게 제공한다. 이는 토큰 비용을 최소화하고, 전문가가 불필요한 전체 히스토리를 보지 않게 함으로써 효율성을 높인다. 또한, 규칙 기반 트리거(키워드)도 옵션으로 제공해 실험적 ablation에 활용한다.
### 실험 설정 및 결과
- **베이스 모델**: Qwen‑2.5‑Coder‑7B‑Instruct (≈7 B 파라미터)
- **전문가 모델**: Claude Sonnet 3.7, 4.5, Opus 4.1 (API 호출당 비용이 높음)
- **데이터**: SWE‑smith과 동일한 5 K SFT 궤적, RL 단계는 100개의 작업에 대해 160 스텝 롤아웃(단일 노드 8 × A100/H100)
- **평가**: SWE‑bench Verified (500 인스턴스, 인간 검증)에서 Pass@1 42.4% 달성. 기존 SLM 최고치 17% 대비 +25.4%p. 평균 4회·전체 토큰 11% 수준의 전문가 호출로, 전문가 전용 에이전트 대비 8.2배 비용 절감.
### 주요 기여
1. **전문가‑프로테제 협업 프레임워크**: SLM이 스스로 정체를 감지하고, 필요 시 전문가에게 질의하며, 다턴에 걸쳐 피드백을 실행·보고하도록 학습시킨 최초 시도.
2. **복합 보상 설계**: 루프 억제와 협업 품질을 동시에 최적화하는 보상 함수와 두 단계 셰이핑 스케줄을 제시.
3. **저비용 고성능**: 최소한의 전문가 호출만으로 대형 모델 수준의 성능을 달성, 비용·지연 측면에서 실용적인 솔루션 제공.
### 한계 및 향후 연구
- 현재 전문가 모델은 고정된 프롬프트와 단일 버전(Claude Sonnet)만 사용했으며, 전문가 자체를 미세조정하거나 다중 전문가(테스트 자동화, 보안 분석 등)와의 협업은 탐색되지 않았다.
- 75‑step·$2 예산 제한 내에서만 평가했으므로, 더 복잡한 리포지터리나 장시간 디버깅 상황에서의 확장성을 추가 실험이 필요하다.
- 인간‑전문가와의 실시간 인터페이스, 동적 비용‑효율성 게이트, 멀티‑모달(코드·문서·테스트) 전문가 연계 등은 향후 연구 방향으로 제시된다.
결론적으로, SWE‑Protégé는 소형 모델이 비용 효율적인 전문가 협업을 통해 장기 소프트웨어 엔지니어링 작업에서 경쟁력 있는 성능을 달성할 수 있음을 실증한다. 이는 AI‑지원 개발 도구가 대형 모델에 의존하지 않고도 실무에 적용될 수 있는 새로운 패러다임을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기