변수 이산화가 인과 함수에 미치는 편향과 그 교정 방법
연속 매개변수의 인과 효과를 추정할 때 변수 이산화를 통해 적분을 합산으로 대체하면 편향이 발생한다. 저자는 이 “코어싱 편향”이 구간 폭에 비례하는 1차 오차임을 증명하고, 구간 내 평균값을 이용한 보정 함수가 2차 오차로 감소시킨다. 플러그인 및 원스텝 추정기를 제시하고, 시뮬레이션을 통해 보정 효과와 신뢰구간 커버리지를 확인한다.
저자: Xiaxian Ou, Razieh Nabi
본 논문은 연속형 매개변수 M을 포함하는 인과 효과 함수의 추정에서, 계산 복잡성을 낮추기 위해 흔히 사용되는 변수 이산화(디스크리타이제이션) 과정이 야기하는 근사 편향, 즉 “코어싱 편향”(coarsening bias)을 체계적으로 분석하고 교정하는 방법을 제시한다.
1. **문제 정의와 기존 접근법**
인과 함수 θ(Q)(c)=∫μ(m,a₁,c)f_{M|A=a₀ ,C=c}(m)dm 은 매개변수 M의 조건밀도와 결과 회귀 μ를 결합한 형태이며, ψ(Q)와 γ(Q)와 같은 전체 인과 효과는 θ(Q)(c)를 C에 대해 평균함으로써 정의된다. 연속 M에 대해 이 적분을 직접 계산하려면 조건밀도 추정과 수치적분이 필요해 통계적·계산적 부담이 크다. 실무에서는 M을 K개의 구간 Bₖ로 나누고, 이산화된 변수 f_M=h(M) 를 사용해 적분을 합산 형태 θ_h(Q)(c)=∑_{k=1}^K μ_k(a₁,c)g_k(a₀,c) 로 근사한다. 여기서 μ_k와 g_k는 각각 구간 내 평균 결과와 구간 확률이다.
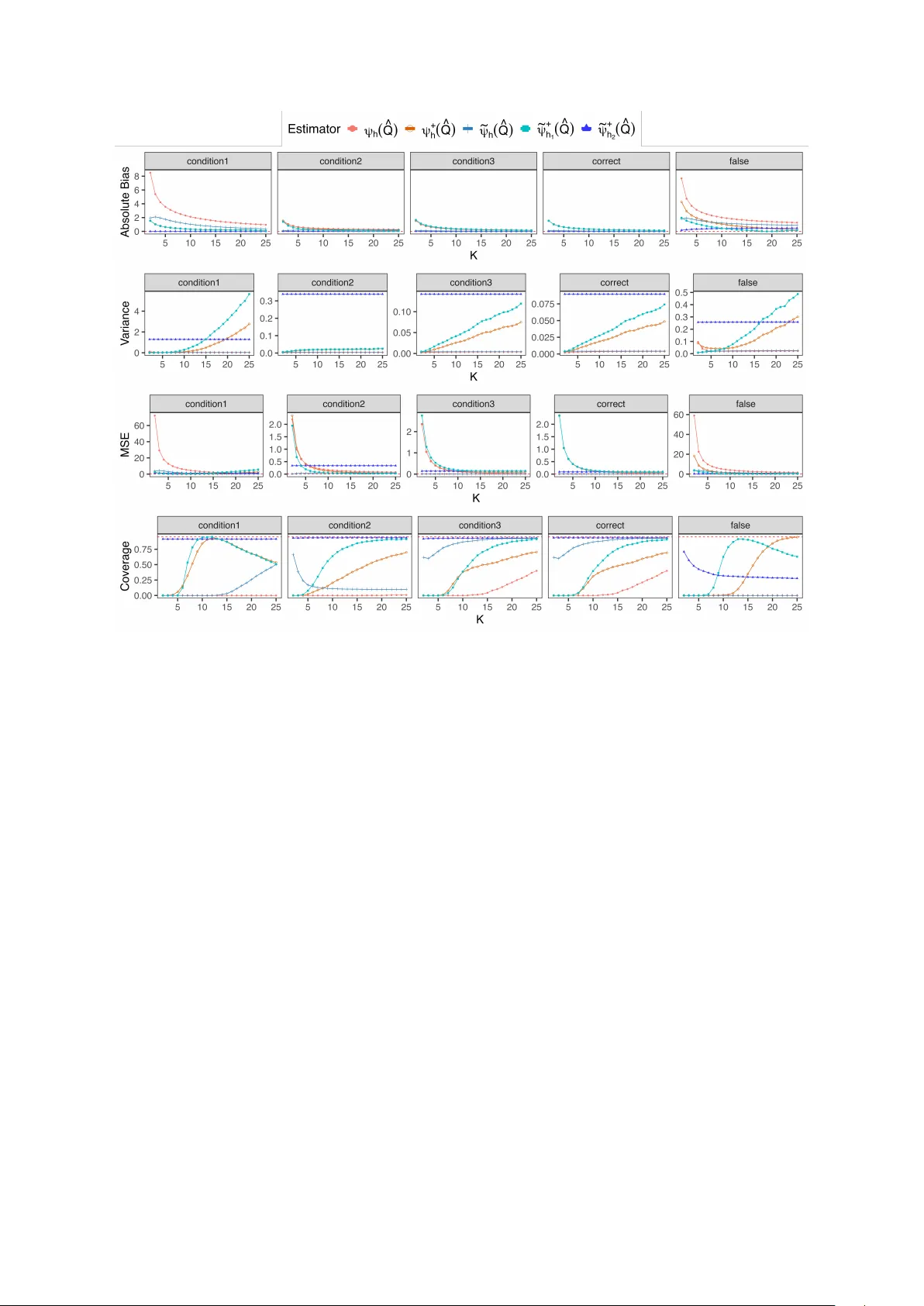
2. **코어싱 편향의 정량적 특성**
Lemma 3.1에 의해 편향 Δ_h(Q)(c)=θ_h(Q)(c)-θ(Q)(c)는 구간 내 평균 μ_k와 구간 내 조건부 평균 μ_{k,a₁}의 차이에 의해 결정된다. 매개변수 μ(m,a₁,c)가 각 구간에서 연속적으로 미분 가능하고, 그 도함수의 절댓값이 상수 L(c) 이하라면 |Δ_h(Q)(c)|=O(w_max) 로, 구간 폭 w_max에 비례하는 1차 오차가 존재한다. 이는 구간 내 평균값 m_k(a₁,c)와 m_k(a₀,c) 사이의 차이와 μ의 기울기 μ'_m가 결합돼 발생한다. 구간이 넓을수록, 혹은 μ'_m가 크게 변할수록 편향이 커진다.
3. **1차 편향을 제거하는 보정 함수**
저자는 구간 평균 m_k(a₀,c)에서 μ를 직접 평가하는 새로운 함수 eθ_h(Q)(c)=∑_{k=1}^K μ(m_k(a₀,c),a₁,c)g_k(a₀,c) 를 제안한다. Taylor 전개를 이용하면 μ_k(a₁,c)-μ_{k,a₁}(a₀,c)=μ'_m·
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기