마코프 전이와 베이지안 학습을 결합한 무한 horizon 최적 제어
본 논문은 마코프 체인으로 변하는 관측 가능한 컨텍스트와, 컨텍스트에 조건부인 미지의 확률분포를 베이지안 방식으로 학습하여 무한 horizon stochastic optimal control 문제를 해결한다. 파라메트릭 밀도 모델과 사후 예측을 이용한 베이지안 벨먼 방정식을 제시하고, 마코프 샘플에 대한 사후 일관성, 가치 함수의 균일 수렴, 그리고 Bernstein‑von Mises 형태의 비대칭 정규성을 증명한다.
저자: Johannes Milz, Alex, er Shapiro
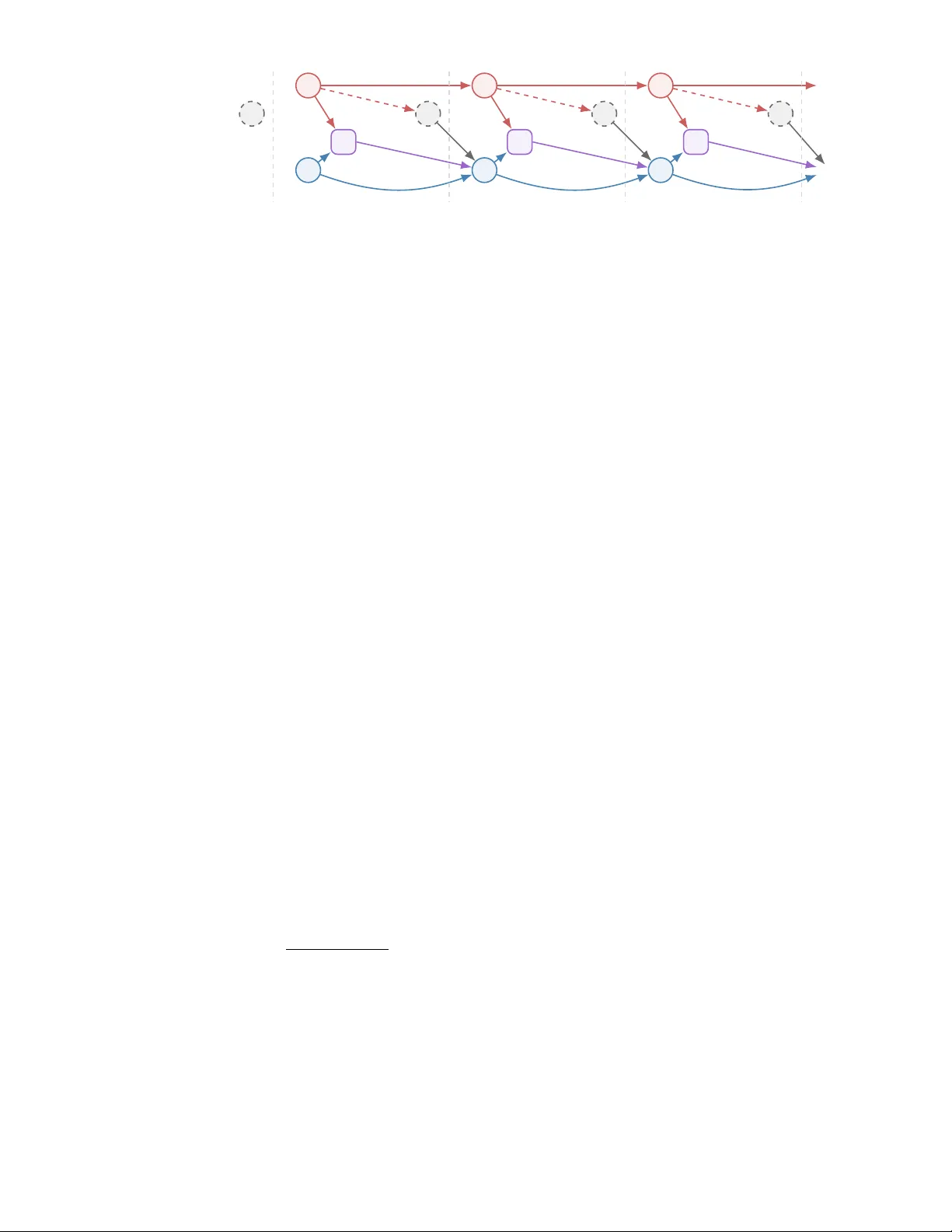
본 논문은 무한 horizon stochastic optimal control (SOC) 문제에 관측 가능한 사이드 정보, 즉 컨텍스트 ηₜ 를 도입하고, 이 컨텍스트가 마코프 체인으로 전이되는 상황을 다룬다. 시스템 상태 xₜ∈ℝⁿ, 제어 uₜ∈ℝᵐ, 외생 잡음 ξₜ∈ℝᵈ 로 구성된 동역학 xₜ₊₁=F(xₜ,uₜ,ξₜ) 와 비용 c(xₜ,uₜ,ξₜ) 를 고려한다. 목표는 할인계수 γ∈(0,1) 하에 기대 누적 비용을 최소화하는 정책 π 를 찾는 것이다. 기존 MDP 이론에서는 ξₜ 의 조건부 분포 q(·|ηₜ) 가 알려져 있다고 가정하지만, 실제 응용에서는 이 분포가 미지이며, 데이터 {(ξᵢ,ηᵢ)}₁ᴺ 로부터 추정해야 한다.
논문은 다음과 같은 단계로 문제를 해결한다.
1. **모델 설정**
- 컨텍스트 ηₜ 는 유한 집합 H 위의 마코프 체인이며 전이 확률 ϖₕ,ₕ′ 로 정의된다.
- ξₜ 는 ηₜ 에 조건부로 밀도 q(·|ηₜ) 를 갖고, 과거와는 독립이다.
- 이때 (xₜ,ηₜ) 가 충분히 상태가 되므로 정책은 마코프 형태 uₜ=πₜ(xₜ,ηₜ) 로 제한 가능하고, Bellman 방정식 (4) 가 성립한다.
2. **베이지안 재구성**
- q(·|η) 를 파라메트릭 가족 f(·|η,θ), θ∈Θ⊂ℝᵈ 로 근사한다.
- 사전 p(θ) 를 지정하고, 관측 데이터 {(ξᵢ,ηᵢ)} 로부터 사후 p_N(θ) ∝ p(θ)·∏_{i=1}^N f(ξ_i|η_i,θ)·ϖ_{η_{i-1},η_i} 를 계산한다.
- 사후 예측 기대 E_{p_N|η}
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기