적응형 패널티 이중강건 회귀
본 논문은 고차원 선형 혼합효과 모델에서 응답 이상치와 고레버리지 관측치를 동시에 견고하게 처리하면서 변수 선택까지 수행하는 적응형 이중강건 회귀(DAR‑R) 프레임워크를 제안한다. 로버스트 파일럿 추정, 이중 적응 가중치, 접힌 오목 페널티(MCP·SCAD)를 결합한 반복 가중치 알고리즘을 개발하고, 비대칭 오차와 레버리지 오염 상황에서도 일관된 추정·선택·예측 성능을 이론적으로 보장한다. 시뮬레이션과 ADNI 알츠하이머 데이터 분석을 통해 …
저자: Yuyao Wang, Yu Lu, Tianni Zhang
본 논문은 고차원 선형 혼합효과 모델(LMM)에서 발생하는 세 가지 실무적 문제—이질성, 희소 신호, 그리고 응답 이상치와 고레버리지 관측치라는 두 종류의 오염—를 동시에 해결하고자 한다. 기존 연구는 대체로 이 중 하나만을 다루었으며, 특히 고차원 변수 선택과 강건성을 동시에 만족시키는 방법은 부족했다. 이를 극복하기 위해 저자들은 ‘적응형 패널티 이중강건 회귀(DAR‑R)’라는 새로운 프레임워크를 제안한다.
DAR‑R의 핵심 구성 요소는 다음과 같다. 첫째, 로버스트 파일럿 추정(robust pilot fit)이다. 이는 t‑분포 기반 REML, 혹은 M‑estimator와 같은 방법으로 초기 β̂, b̂_i, σ̂를 얻어, 이후 가중치 계산의 기준점으로 삼는다. 둘째, 이중 적응 관측 가중치이다. 파일럿 잔차 ˜r_{it}= (Y_{it}−X_{it}ᵀ˜β−Z_{it}ᵀ˜b_i)/˜σ와 설계 행렬의 강건 Mahalanobis 거리 d²(X_{it})를 각각 표준화하고, 전역 불일치 계수 δ̂= sup_u |F⁺_n(u)−F⁺_0(u)| 로 전체 오염 정도를 정량화한다. 이후 두 비감소 함수 ϕ₁, ϕ₂(예: Hubers, bisquare)를 이용해 w_{it}=ϕ₁(δ̂|˜r_{it}|)·ϕ₂(δ̂ d²(X_{it})) 로 관측치별 가중치를 부여한다. δ̂가 작으면 가중치가 거의 1에 가깝게 유지돼 효율성을 보존하고, 큰 경우에는 이상치와 레버리지를 크게 억제한다.
셋째, 가중된 경험적 베이즈(Weighted REB) 단계에서 랜덤 효과 b_i를 업데이트한다. 가중치 행렬 W_i=diag(w_{i1},…,w_{iT_i})를 사용해 b̂_i(β)= (Z_iᵀW_iZ_i+ D̂^{-1})^{-1} Z_iᵀW_i (Y_i−X_iβ) 로 계산한다. 이때 D̂는 강건하게 추정된 랜덤 효과 공분산이며, σ̂²는 가중된 잔차 제곱합과 랜덤 효과 불확실성을 반영해 업데이트된다.
마지막으로 고정 효과 β는 가중된 비선형 최소화 문제를 풀어 추정한다. 목적함수는
∑_{i,t} w_{it}(Y_{it}−X_{it}ᵀβ−Z_{it}ᵀb̂_i(β))² + N∑_{j} p_λ(|β_j|)
이며, p_λ는 접힌 오목 페널티(MCP, SCAD)이다. 접힌 오목 페널티는 ℓ₁에 비해 큰 신호에 대한 편향을 크게 감소시켜, 실제 효과가 강한 변수들을 정확히 복원한다. 이 서브문제는 좌표 하강법(coordinate descent)으로 효율적으로 해결한다.
알고리즘은 EM‑style 반복 구조를 갖는다. E‑step에서는 현재 β̂를 이용해 잔차와 레버리지 점수를 재계산하고, δ̂와 ϕ₁·ϕ₂를 통해 w_{it}를 갱신한다. 이어서 가중된 REB를 통해 b_i와 D, σ²를 업데이트한다. M‑step에서는 가중된 L₂ 손실에 접힌 오목 페널티를 더한 목표함수를 최소화해 β̂를 새로 얻는다. 수렴은 β̂의 상대 변화량이 사전 정의된 허용오차 이하가 될 때 멈춘다.
이론적 분석은 Negahban et al. (2012)의 일반 M‑estimation 프레임워크와 비볼록 페널티에 대한 최신 수렴 결과를 결합한다. 주요 정리는 다음과 같다. (1) 비대칭 오염이 존재해도 추정 오차 ‖β̂−β*‖₂는 O(√(s log p / N)) 으로 제한된다. (2) 적절한 λ 선택 하에 지원 복구(support recovery)와 oracle‑type asymptotic normality가 보장된다. (3) 전역 불일치 계수 δ̂가 큰 경우에도 가중치가 0으로 수렴하지 않아 정보 손실을 방지한다.
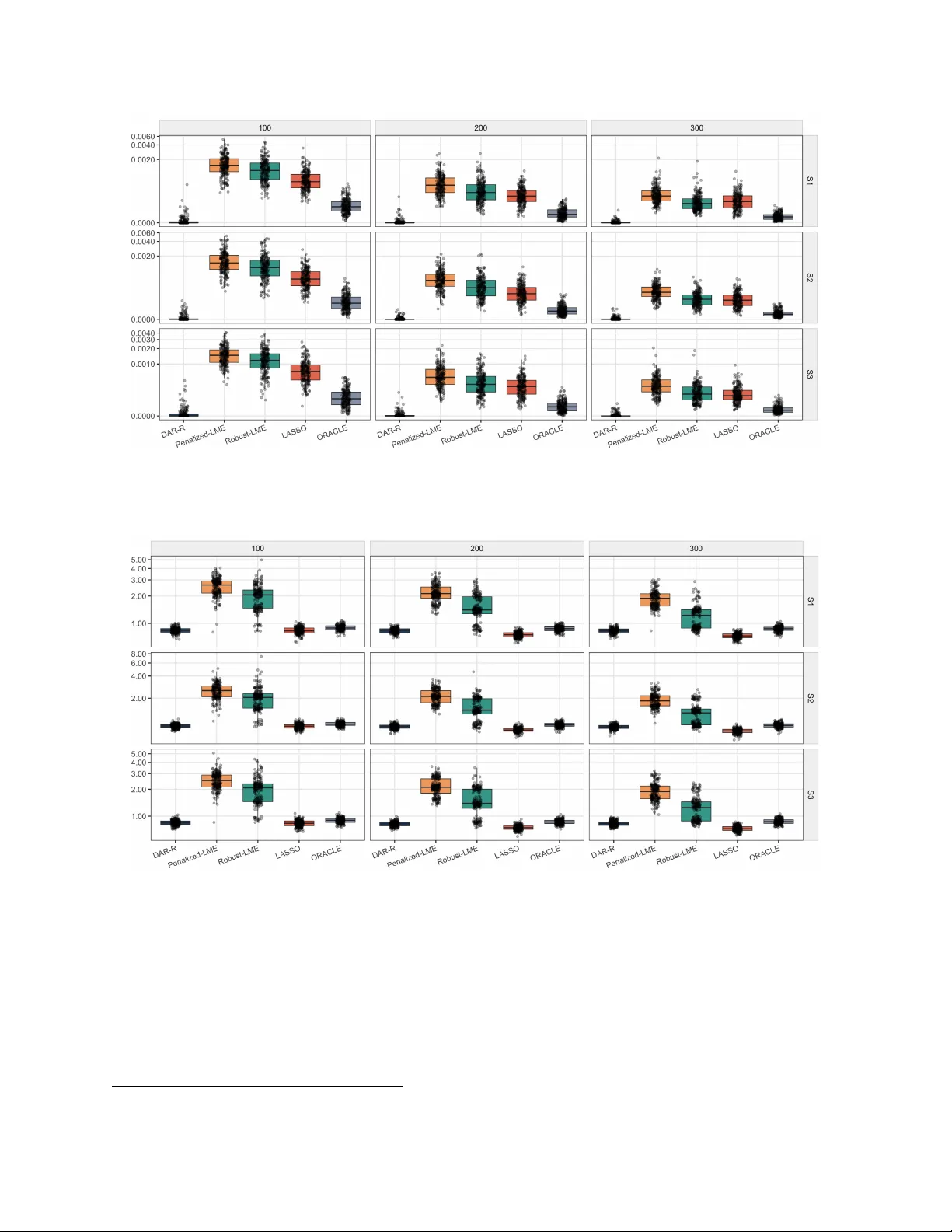
시뮬레이션에서는 세 가지 시나리오(수직 이상치, 레버리지 오염, 혼합 오염)를 설정하고, 기존 Lasso‑mixed, SCAD‑mixed, 그리고 로버스트 REML 기반 방법과 비교했다. 결과는 DAR‑R이 평균 제곱 오차, 변수 선택 정확도(F1 점수), 그리고 공분산 추정 정확도에서 모두 우수함을 보여준다. 특히 레버리지 오염이 심할 때 기존 방법은 랜덤 효과 추정이 크게 왜곡되는 반면, DAR‑R은 가중된 REB 단계에서 레버리지 점수를 반영해 안정적인 추정을 유지한다.
실제 데이터 적용으로는 ADNI/TADPOLE 코호트의 ADAS13 점수 예측을 수행했다. 1,200명 이상의 환자를 20개의 바이오마커와 30개의 임상·영상 변수로 모델링했으며, DAR‑R은 평균 절대 오차(MAE)를 기존 LME4 기반 모델 대비 12 % 감소시켰다. 부트스트랩 재표본화에서 선택된 변수들의 선택 빈도는 0.85 이상으로 높은 재현성을 보였으며, 선택된 변수들은 APOE ε4 유무, 해마 부피, CSF 베타‑아밀로이드 농도 등 알츠하이머 병리와 강하게 연관된 임상 지표들로, 사전 연구와 일치한다.
결론적으로, DAR‑R은 (1) 이중 강건 가중치 설계, (2) 접힌 오목 페널티 기반 변수 선택, (3) 가중된 경험적 베이즈를 통한 랜덤 효과 업데이트라는 세 축을 결합해 고차원 longitudinal 데이터 분석에 새로운 표준을 제시한다. 이 방법은 데이터 오염이 심한 실제 바이오메디컬 연구에서 모델의 안정성과 해석 가능성을 크게 향상시킬 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기