리로 브이엘에이: 연결된 객체 중심 정책으로 구현하는 장기 조작
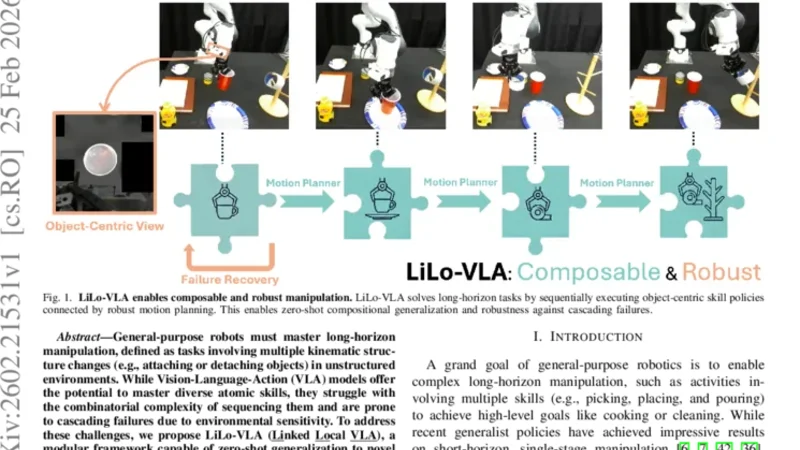
리로-브이엘에이는 이동과 상호작용을 분리한 모듈식 프레임워크로, 객체 중심 비전‑언어‑액션 모델을 활용해 복잡한 장기 조작을 제로샷으로 수행한다. 전역 이동을 담당하는 Reaching Module과 물체별 상호작용을 담당하는 Interaction Module을 연결해 환경 변화에 강인하고, 실패 시 동적 재계획과 스킬 재사용으로 오류 전파를 억제한다. 21
초록
리로-브이엘에이는 이동과 상호작용을 분리한 모듈식 프레임워크로, 객체 중심 비전‑언어‑액션 모델을 활용해 복잡한 장기 조작을 제로샷으로 수행한다. 전역 이동을 담당하는 Reaching Module과 물체별 상호작용을 담당하는 Interaction Module을 연결해 환경 변화에 강인하고, 실패 시 동적 재계획과 스킬 재사용으로 오류 전파를 억제한다. 21개의 시뮬레이션 과제와 8개의 실제 로봇 과제에서 각각 69%와 85%의 성공률을 기록했다.
상세 요약
리로-브이엘에이(LiLo-VLA)는 장기 조작 문제를 “이동(transport)”과 “상호작용(interaction)”이라는 두 축으로 분해한다. Reaching Module은 전역 좌표계에서 목표 물체까지 로봇 팔을 이동시키는 역할을 수행하며, 전통적인 경로 계획 알고리즘이나 학습 기반 이동 정책을 사용할 수 있다. 반면 Interaction Module은 객체‑중심 VLA 모델을 적용해, 물체를 격리된 시점에 입력함으로써 주변 배경이나 다른 물체의 시각적 방해를 최소화한다. 이 설계는 VLA가 “시각‑언어‑행동” 삼위일체를 학습할 때 겪는 공간적 편향을 크게 감소시킨다.
모듈 간 연결 고리는 “Linked” 메커니즘으로 구현된다. Reaching Module이 목표 물체에 도달하면, 해당 물체의 바운딩 박스를 추출해 Interaction Module에 전달한다. Interaction Module은 물체‑특정 프롬프트와 함께 VLA를 호출해 집게, 끼우기, 나사 조이기 등 원자적 스킬을 생성한다. 생성된 스킬은 로봇 제어 레이어에 바로 매핑되어 실행된다.
실패 복구는 두 단계로 이루어진다. 첫째, Interaction Module이 예상치 못한 물체 상태(예: 미끄러짐, 위치 오차)를 감지하면 즉시 현재 스킬을 중단하고 Reaching Module에 재배치를 요청한다. 둘째, 재배치 후 동일 스킬을 재시도하거나, 필요 시 대체 스킬을 선택해 진행한다. 이러한 동적 재계획은 오류 전파를 방지하고, 복합적인 작업 흐름에서도 높은 성공률을 유지한다.
벤치마크는 LIBERO‑Long++와 Ultra‑Long 두 스위트로 구성된 21개의 시뮬레이션 과제와, 실제 로봇 환경에서 8개의 장기 조작 과제로 나뉜다. 시뮬레이션에서 LiLo‑VLA는 평균 69% 성공률을 기록했으며, 기존 최첨단 모델인 Pi0.5 대비 41%, OpenVLA‑OFT 대비 67% 향상된 결과를 보였다. 실제 로봇 실험에서는 환경 잡음과 센서 오차가 존재함에도 불구하고 85%의 성공률을 달성했다.
핵심 기여는 (1) 이동‑상호작용 모듈화로 VLA의 환경 민감성을 감소, (2) 객체‑중심 입력 설계로 스킬 재사용성을 극대화, (3) 동적 재계획 메커니즘을 통한 오류 복구 능력이다. 이러한 설계 원칙은 장기 조작을 위한 범용 로봇 시스템에 적용 가능하며, 향후 복합적인 물리적 변형과 다중 로봇 협업에도 확장될 여지를 제공한다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...