실제 데이터에 맞춘 조건부 독립성 검정 교정 방법
조건부 독립성 검정(CIT)은 작은 표본이나 모델 오차가 있을 때 p‑값이 제대로 보정되지 않아 오류율이 크게 늘어난다. 논문은 이러한 문제를 해결하기 위해 ‘ECCIT’이라는 적대적 교정 프레임워크를 제안한다. 주어진 CIT에 대해 가장 위험한 데이터 생성 모델을 적대적으로 찾고, 그 모델이 만든 p‑값을 이용해 단조(monotone) 보정 함수를 학습한다. 실험 결과 ECCIT은 기존 보정 기법보다 FDR을 정확히 제어하면서 검정력도 향상시…
저자: Milleno Pan, Antoine de Mathelin, Wesley Tansey
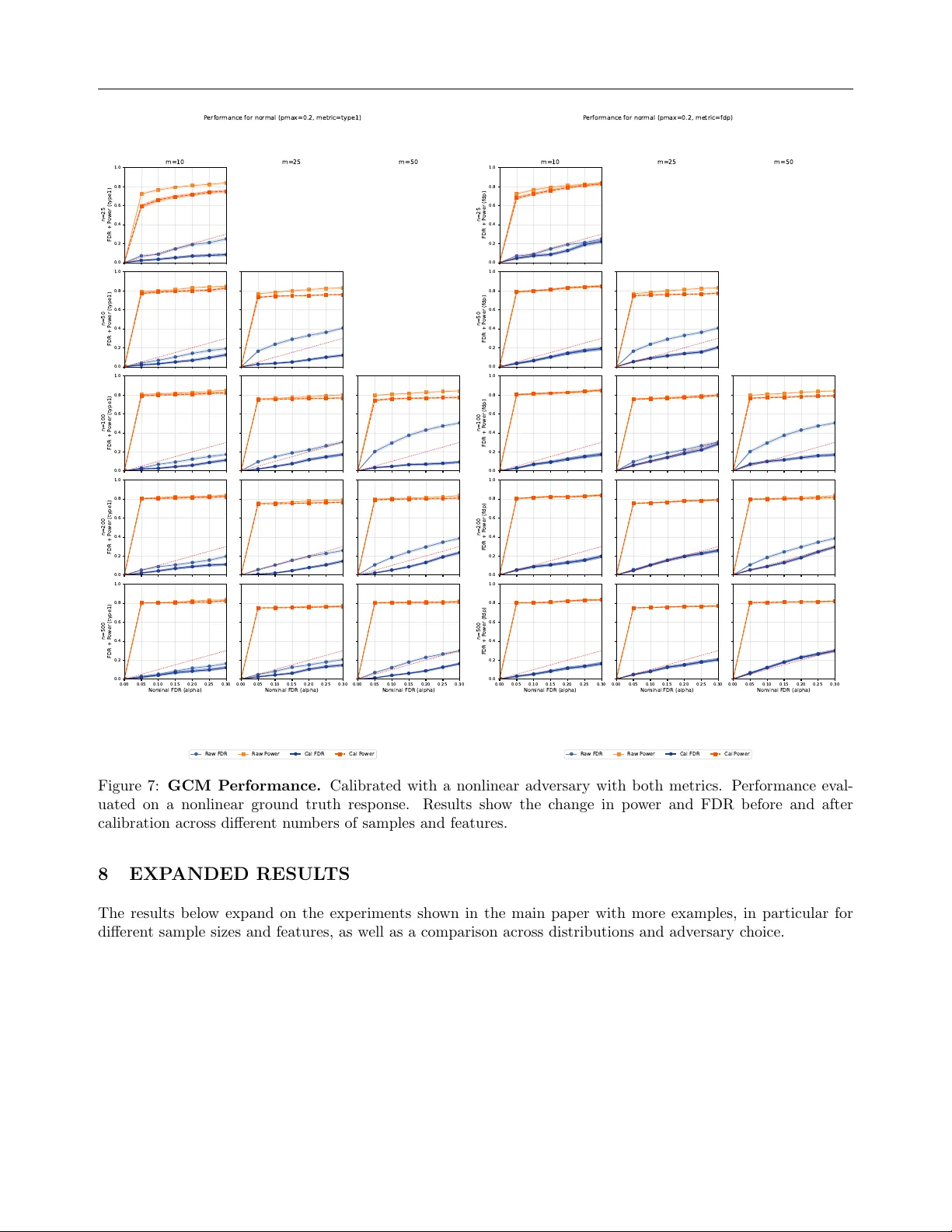
본 논문은 조건부 독립성 검정(CIT)이 실제 과학 데이터에서 자주 겪는 두 가지 주요 실패 모드—작은 표본에서의 asymptotic 근사 부정확성 및 모델 miss‑specification에 의한 p‑값 편향—를 지적하고, 이를 해결하기 위한 새로운 교정 프레임워크인 **Empirically Calibrated Conditional Independence Tests (ECCIT)** 를 제안한다.
**1. 문제 정의와 배경**
조건부 독립성 검정은 “X ⟂ Y | Z”라는 귀무가설을 검정함으로써 인과 관계 탐색이나 변수 선택에 핵심적인 역할을 한다. 기존 검정은 크게 세 가지 접근법으로 나뉜다: 로컬 퍼뮤테이션, 모델‑X, 그리고 asymptotic 기반. 로컬 퍼뮤테이션은 연속형 변수에 적용하기 어려우며, 모델‑X와 asymptotic 검정은 각각 조건부 분포 추정과 모델 가정에 크게 의존한다. 특히 고차원·저표본 상황에서 이들 방법은 type‑I 오류를 크게 초과하거나 검정력을 급격히 잃는다. 기존 연구들은 각각의 문제를 완화하기 위한 방법(예: CR‑T 보정, Maxway CR‑T, CONTRA 등)을 제시했지만, **전반적인 p‑값 교정 메커니즘**을 제공하지 못한다.
**2. ECCIT 프레임워크**
ECCIT은 “가장 위험한” 데이터 생성 모델을 찾아 그 모델이 만든 p‑값을 기반으로 **단조 보정 함수**를 학습한다. 구체적인 절차는 다음과 같다.
- **(a) 적대적 모델 클래스 정의**: 함수 클래스 F는 Y = f(X, ε) 형태로 정의되며, 여기서 f는 평균 함수 µ_θ와 이진 마스크 γ로 구성된다. γ_j = 1이면 X_j가 Y 생성에 기여하고, γ_j = 0이면 null 변수이다. µ_θ는 신경망 등 차분 가능한 모델로 구현한다.
- **(b) Miscalibration Metric M 정의**: 목표 오류 수준 α와 제어하고자 하는 오류 지표(FWER 혹은 FDR)를 반영하는 metric M을 설정한다. 예를 들어, FDR 목표라면 M은 “실제 FDR - α”와 같은 형태가 된다.
- **(c) 최악의 적대자 찾기**: 기대값 E_X
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기