스펙트럴 조건을 활용한 μP 확장: 다양한 옵티마이저의 특징 학습 스케일링
본 논문은 최근 제안된 스펙트럴 스케일링 조건을 이용해 μP(최대 업데이트 파라미터화)를 일반화하고, AdamW, ADOPT, LAMB, Sophia, Shampoo, Muon 등 여섯 가지 최신 옵티마이저에 대해 정확한 스케일링 법칙을 유도한다. 실험적으로 NanoGPT와 Llama‑2 모델에 적용해 폭(Width) 확대 시 학습률을 그대로 전이(zero‑shot)할 수 있음을 보이며, 깊이(Depth) 확대에 대한 초기 탐색 결과도 제시한다…
저자: Akshita Gupta, Marieme Ngom, Sam Foreman
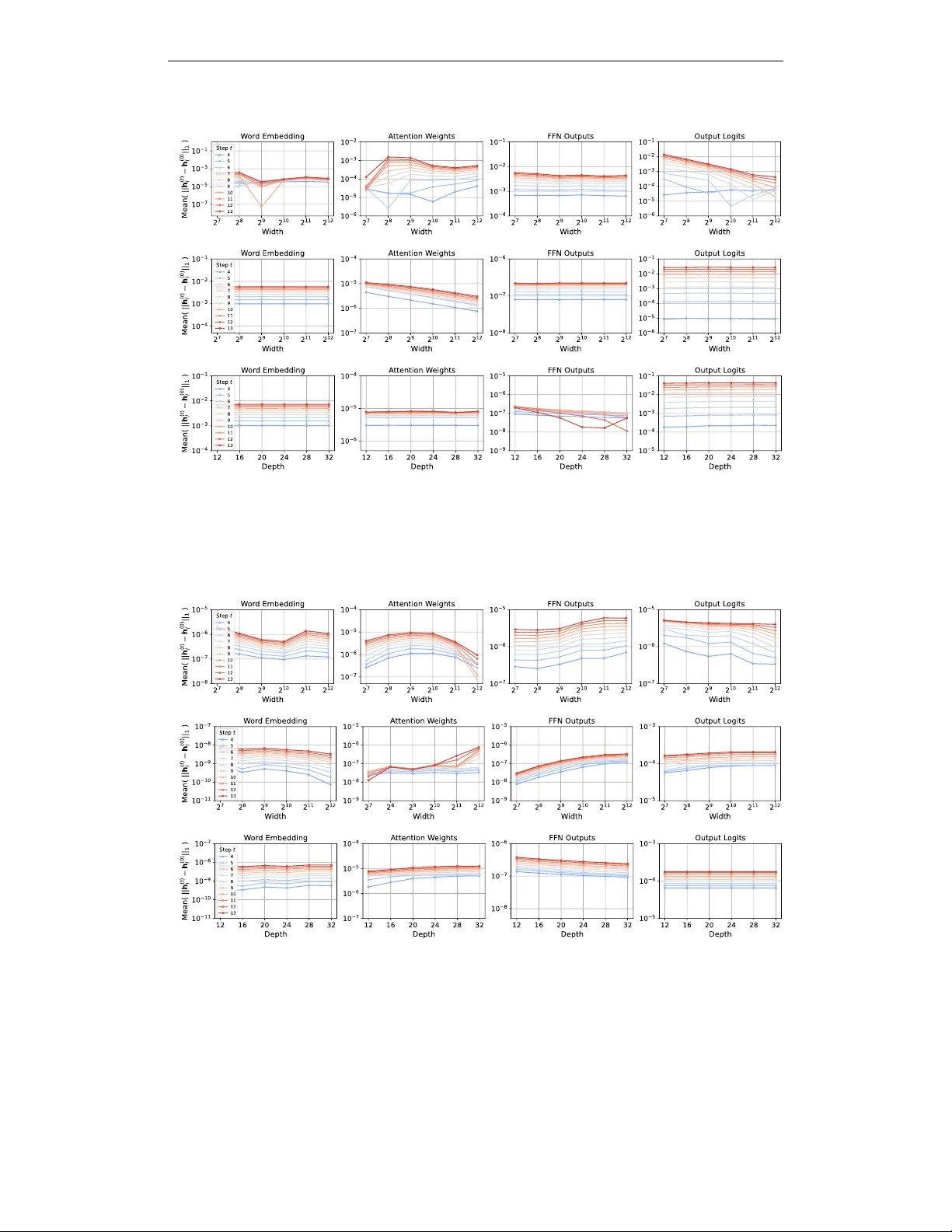
본 논문은 대규모 언어 모델(LLM) 훈련 시 하이퍼파라미터 튜닝 비용을 낮추기 위한 “최대 업데이트 파라미터화(μP)”를 보다 폭넓은 옵티마이저에 적용하는 방법을 제시한다. 기존 μP는 SGD와 Adam에 대해서만 이론적 스케일링이 정립돼 있었으며, 텐서 프로그램이라는 복잡한 수학적 도구를 사용해 가중치와 학습률을 모델 폭에 따라 어떻게 조정해야 하는지를 증명했다. 그러나 텐서 프로그램은 직관성이 떨어지고 구현이 어려워 실제 연구·산업 현장에서 적용이 제한적이었다.
최근 Yang et al. (2023a)는 μP의 핵심 요구조건을 “스펙트럴 스케일링 조건(C.2)”으로 대체하였다. 구체적으로, 각 레이어의 가중치 행렬 Wₗ 과 그 한 스텝 업데이트 ΔWₗ 의 스펙트럴 노름이 ‖Wₗ‖_* = Θ(√(nₗ nₗ₋₁)), ‖ΔWₗ‖_* = Θ(√(nₗ nₗ₋₁)) 을 만족하면, 특징 벡터의 ℓ₂ 노름이 Θ(√nₗ) 을 유지하고, 학습률을 폭에 독립적으로 전이할 수 있다.
논문은 이 스펙트럴 조건을 기반으로 새로운 일반 프레임워크를 구축한다. 먼저, 가중치 초기화 Wₗ = σₗ · \tilde{W}ₗ (σₗ은 스케일링 팩터, \tilde{W}ₗ은 단위 분산 랜덤 행렬) 로 두고, 랜덤 행렬 이론을 이용해 ‖\tilde{W}ₗ‖_* ≈ √nₗ + √nₗ₋₁ 임을 이용한다. 이를 스펙트럴 조건에 대입하면 σₗ ≈ 1/√(nₗ₋₁) 가 필요함을 도출한다. 이는 기존 μP에서 제시된 “가중치 스케일링 aₗ = 1/2, bₗ = 0”과 일치한다.
다음으로 학습률 스케일링을 다룬다. 일반적인 업데이트 식 ΔWₗ = ‑η Ψ(∇Wₗ L) 에서 Ψ 는 옵티마이저마다 다른 함수이다. 논문은 AdamW, ADOPT, LAMB, Sophia, Shampoo, Muon 여섯 가지 최신 옵티마이저에 대해 각각 Ψ 의 주요 항을 차수별로 분석한다.
- **AdamW / ADOPT**: Ψ ≈ \hat{m}/(√\hat{v}+ε) + λW. 여기서 ‖Ψ‖_* ≈ Θ(1) 이므로, 스펙트럴 조건 ‖ΔWₗ‖_* = Θ(√(nₗ nₗ₋₁)) 을 만족하려면 η ∝ 1/√(nₗ nₗ₋₁) 가 된다.
- **LAMB**: Ψ ≈ φ(‖Wₗ‖_F)·rₗ + λW. φ와 rₗ은 각각 가중치 노름과 정규화된 그라디언트이며, 차수 분석 결과 η 의 스케일은 동일하게 1/√(nₗ nₗ₋₁) 이다.
- **Sophia**: Ψ ≈ clip(m)·max{γh, ε} + λW. clip 연산은 상수 차원이며, 전체 스케일 역시 1/√(nₗ nₗ₋₁) 으로 수렴한다.
- **Shampoo**: Ψ ≈ (L(t))^{‑1/4} ∇W (R(t))^{‑1/4}. 여기서 L, R은 각각 행과 열 방향의 2차 통계량이며, 차수 분석을 통해 η ∝ √nₗ · 1/√(nₗ nₗ₋₁) = 1/√nₗ₋₁ 가 된다.
- **Muon**: 숨겨진 레이어에만 적용되는 특수 구조이지만, 가중치와 업데이트의 차원을 동일하게 고려하면 η ∝ 1/√(nₗ nₗ₋₁) 가 된다.
이러한 분석을 통해 각 옵티마이저에 대한 μP 스케일링 파라미터 aₗ, bₗ, c (학습률 스케일) 를 표 2에 정리한다.
논문은 또한 실험적 검증을 수행한다. NanoGPT와 Llama‑2 모델을 사용해 레이어 폭을 2배, 4배, 8배 확대하면서, 위에서 도출한 학습률 스케일을 그대로 적용한다. 결과는 다음과 같다.
1. **학습률 전이(zero‑shot)**: 모든 옵티마이저에서 최적 학습률이 폭에 관계없이 동일한 값(예: η = 0.001)으로 유지되었다. 이는 검증 손실 곡선이 거의 겹치는 것으로 확인된다.
2. **특징 학습 안정성**: 레이어별 특징 벡터의 ℓ₂ 노름이 폭 확대에 따라 Θ(√nₗ) 을 유지했으며, 이는 μP가 보장하는 “maximal feature learning”을 실증한다.
3. **wider‑is‑better**: 폭이 커질수록 훈련 손실이 지속적으로 감소했으며, 특히 Sophia와 Shampoo에서 가장 뚜렷한 개선을 보였다.
4. **깊이 스케일링 탐색**: 깊이를 늘리는 경우 학습률 전이가 완벽히 일치하지는 않지만, 최적 학습률 범위가 크게 축소되는 경향을 보여, 향후 깊이‑스케일링 이론 개발의 필요성을 제시한다.
마지막으로 논문은 μP 적용 시 몇 가지 가정이 필요함을 강조한다. 첫째, 업데이트가 초기 가중치와 완전히 상쇄되지 않아야 한다(Assumption 1). 둘째, 활성화 함수가 ℓ₂ 노름을 보존해야 한다(Assumption 2). 셋째, 배치 크기가 모델 폭에 독립적이어야 한다(Assumption 3). 특히 Assumption 3은 현재 μP 의 제한점으로, 실제 대규모 훈련에서는 배치 크기를 늘려야 하지만, 고정 배치에서 스케일링을 맞춘 뒤 학습률을 선형 스케일링 규칙에 따라 조정하면 충분히 적용 가능하다고 제안한다.
결론적으로, 스펙트럴 조건 기반 프레임워크는 텐서 프로그램보다 직관적이며, 다양한 최신 옵티마이저에 대해 일관된 μP 스케일링을 제공한다. 이는 대규모 LLM 훈련 시 하이퍼파라미터 튜닝 비용을 크게 절감하고, 모델 설계 단계에서 폭‑스케일링을 안전하게 적용할 수 있게 한다. 향후 연구는 깊이‑스케일링 이론 확장과 배치‑스케일링을 동시에 만족하는 μP 변형을 탐구할 여지를 남긴다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기