음성인식의 정확도와 속도를 동시에 잡는 마스크드 디퓨전 비자율 디코딩
본 논문은 사전 학습된 스피치 인코더와 트랜스포머 기반 마스크드 디퓨전 디코더를 결합한 비자율(Non‑Autoregressive) ASR 프레임워크인 MDM‑ASR를 제안한다. 마스크드 디퓨전 과정을 통해 전체 토큰을 병렬로 예측하면서도 양방향 문맥을 활용하고, 훈련‑추론 불일치를 완화하기 위해 Iterative Self‑Correction Training(ISCT)를 도입한다. 또한 엔트로피 기반 신뢰도 샘플러와 위치 편향을 결합한 PB‑EB…
저자: Hao Yen, Pin-Jui Ku, Ante Jukić
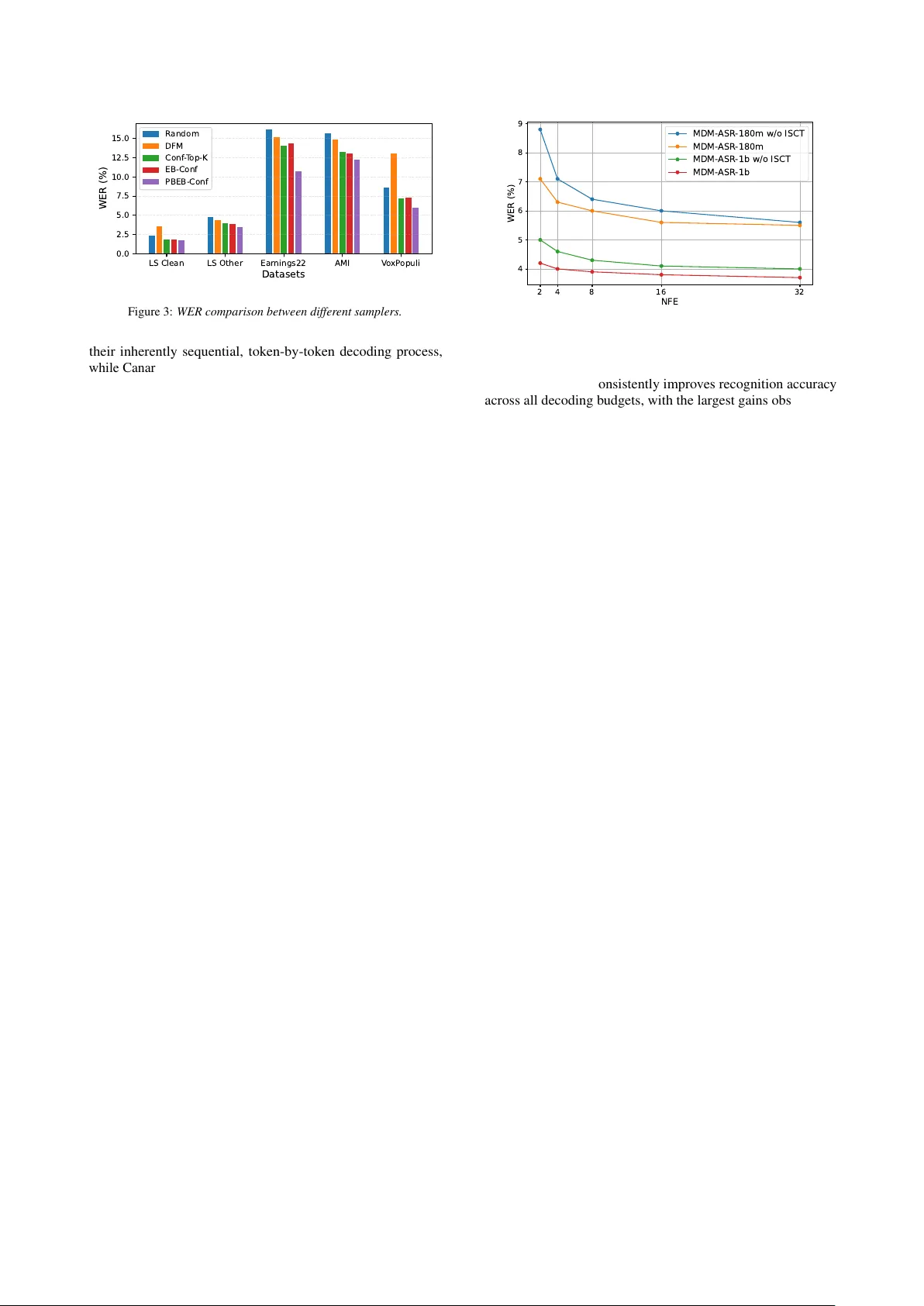
본 논문은 자동 음성 인식(ASR) 분야에서 비자율(Non‑Autoregressive, NAR) 모델이 갖는 속도 장점은 유지하면서, 기존 AR(Autoregressive) 모델에 버금가는 정확도를 달성하고자 하는 목표를 갖는다. 이를 위해 저자들은 마스크드 디퓨전(Masked Diffusion Model, MDM)이라는 최신 생성 모델을 ASR에 적용한 새로운 프레임워크 MDM‑ASR를 설계하였다.
1. **배경 및 동기**
- AR 기반 시퀀스‑투‑시퀀스 트랜스포머는 높은 정확도를 제공하지만, 토큰을 순차적으로 생성하므로 디코딩 시간이 출력 길이에 비례해 선형적으로 증가한다.
- 기존 NAR 접근법인 CTC, Mask‑CTC 등은 병렬 디코딩이 가능해 빠르지만, 토큰 간 독립성을 가정해 언어적 종속성을 충분히 모델링하지 못한다.
- 최근 텍스트 생성 분야에서 diffusion 및 flow‑matching 기반 NAR 모델이 성공을 거두면서, 이를 음성 인식에 적용하려는 시도가 늘어나고 있다. 그러나 기존 연구(Transfusion, FFDM, Whisfusion, Drax 등)는 정확도가 AR 모델에 크게 뒤처지거나, 복잡한 두 단계 학습 파이프라인을 필요로 하는 한계가 있었다.
2. **MDM‑ASR 구조**
- **음성 인코더**: 사전 학습된 wav2vec 2.0, HuBERT 등 강력한 스피치 인코더를 사용해 입력 음성을 고차원 특징 a∈ℝ^{T×D} 로 변환한다.
- **마스크드 디퓨전 디코더**: 전통적인 트랜스포머 디코더를 비인과적(self‑attention) 형태로 변경하고, 각 디퓨전 스텝마다 전체 토큰 시퀀스를 동시에 예측한다. 디코더는 cross‑attention을 통해 음성 특징 a와 현재 마스크된 토큰 시퀀스 z_t 를 동시에 참조한다.
- **마스크드 디퓨전 과정**: 토큰 x∈V 를 점진적으로
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기