언롤링의 저주: 비대칭 미분이 처음에 발산하는 이유와 해결 방안
본 논문은 바이레벨 최적화와 메타러닝에서 사용되는 알고리즘 언롤링이 초기 단계에서 진짜 야코비안을 벗어나는 현상, 즉 “언롤링의 저주”를 비대칭(non‑asymptotic) 관점에서 분석한다. 수축성 가정과 Lipschitz 연속성을 바탕으로 도함수 오차가 어떻게 누적되는지 정량화하고, 초기 몇 단계의 미분을 생략(트렁케이션)하거나 워밍‑스타트를 활용하면 저주를 완화할 수 있음을 이론과 실험으로 입증한다.
저자: Sheheryar Mehmood, Florian Knoll, Peter Ochs
본 논문은 바이레벨 최적화와 메타러닝 등에서 내부 문제의 해 x★(u)를 암시적 함수로 두고, 외부 목적 ℓ(x★(u),u)의 그래디언트를 구하기 위해 알고리즘 언롤링을 사용하는 상황을 다룬다. 전통적인 암시적 미분은 (I−DₓA)⁻¹·DᵤA 형태의 닫힌 해를 제공하지만, 실제로는 내부 알고리즘을 K번 반복한 근사 해 x(K)(u)를 사용하고, 자동 미분(전방·역방)으로 Dₓx(K)(u)를 계산한다. 이때 Dₓx(K)(u) 가 진짜 야코비안 Dₓx★(u)와 얼마나 빠르게 수렴하는지는 기존 연구에서 asymptotic linear 수렴만 보였고, 초기 단계에서 오히려 오차가 증가한다는 현상이 보고되었다. 이를 “언롤링의 저주”라 명명하고, 논문은 이를 비대칭(non‑asymptotic) 관점에서 정량화한다.
먼저, A가 C¹‑smooth하고 전역 수축성(ρ(u)<1)을 만족한다는 Assumption 2.1을 도입한다. 이 가정 하에 Banach 고정점 정리와 암시적 함수 정리를 이용해 x★(u)와 그 야코비안 Dₓx★(u) = (I−B(u))⁻¹C(u) 가 존재함을 보인다. 여기서 B(u)=DₓA(x★(u),u), C(u)=DᵤA(x★(u),u)이다. 내부 알고리즘은 x(k+1)(u)=A(x(k)(u),u) 로 정의되고, 수축성으로 인해 ‖x(k)−x★‖ ≤ ρ^k‖x(0)−x★‖ 로 선형 수렴한다.
다음으로 자동 미분을 두 모드(전방·역방)로 기술한다. 전방 모드에서는 ˙X(k+1)=Bₖ·˙X(k)+Cₖ 로 재귀가 정의되고, ˙X(k)=Dₓx(k) 와 동일하다. 역방 모드에서는 역전파 형태의 (¯X(k),¯U(k)) 를 정의해 최종 야코비안 Dₓx(K)=¯U(0)와 같다. 두 모드 모두 동일한 최종 결과를 제공한다.
비대칭 분석의 핵심은 Lemma 4와 Lemma 6이다. Lemma 4는 전방 오차 ˙e(k)=‖˙X(k)−Dₓx★‖ 가 재귀적으로 ˙e(k+1) ≤ ρ·˙e(k)+Γ·e(k) 를 만족함을 보인다. 여기서 e(k)=‖x(k)−x★‖ 이며, Γ는 DₓA와 DᵤA의 Lipschitz 상수(Mₓ, Mᵤ)와 수축계수 ρ, 그리고 DᵤA의 절대 상한 κ 로 구성된다: Γ = Mₓ·κ/(1−ρ)+Mᵤ. Lemma 6은 Bₖ와 Cₖ 가 최적값 주변의 B, C 와 차이가 O(e(k)) 임을 증명해 위 부등식의 Γ·e(k) 항을 정당화한다.
이 부등식으로부터 Theorem 7은 전방(또는 역방) 도함수 오차에 대한 비대칭 수렴식
˙e(k) ≤ ρ^k·˙e(0) + k·ρ^{k−1}·Γ·e(0)
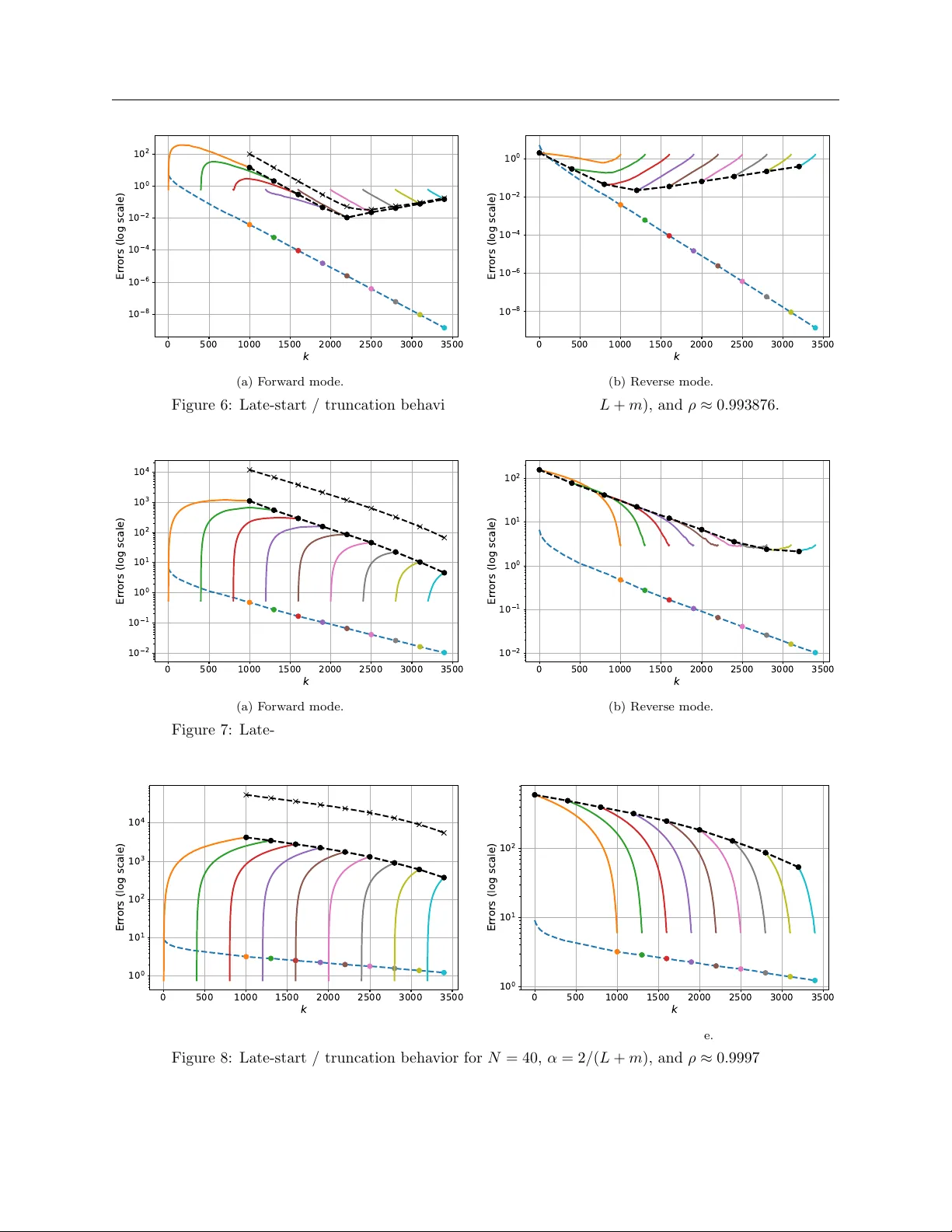
을 도출한다. 첫 번째 항은 전통적인 선형 수렴을, 두 번째 항은 초기 단계에서 k·ρ^{k−1} 형태로 급격히 증가할 수 있는 “오차 피크”를 설명한다. 즉, 초기 e(0) 가 작지 않다면 Γ·e(0) 가 지배적으로 작용해 ˙e(k) 가 일시적으로 상승한다. 이것이 바로 “언롤링의 저주”이다.
저주를 완화하는 두 가지 실용적인 전략을 제시한다. 첫째, 트렁케이션은 초기 몇 단계(예: 0~t) 를 미분에서 제외하고 t+1부터 역전파하거나 전방 전파를 수행한다. 이 경우 Γ·e(k) 항이 초기 큰 e(k) 를 포함하지 않게 되므로 오차 피크가 크게 감소한다. 둘째, 워밍‑스타트는 외부 파라미터 u가 바뀔 때 이전 최적점 x★(u₀) 근처에서 내부 알고리즘을 시작하도록 하여 초기 e(0) 자체를 작게 만든다. 논문은 워밍‑스타트가 자동으로 트렁케이션 효과를 내며, 메모리 사용량도 절감된다는 점을 강조한다.
실험에서는 1차 및 2차 최적화, 선형 시스템, 신경망 기반 메타러닝 등 여러 베이스라인에 대해 트렁케이션 비율과 워밍‑스타트 빈도를 변화시켜 오차 곡선을 측정했다. 결과는 이론적 경계와 일치하며, 트렁케이션·워밍‑스타트가 초기 오차 피크를 거의 없애고 전체 수렴 속도는 유지하거나 약간 향상됨을 보여준다.
결론적으로, 논문은 언롤링이 단순히 “많이 풀면 정확해진다”는 직관을 넘어, 초기 단계에서의 오차 전파 메커니즘을 정량적으로 이해하고, 트렁케이션과 워밍‑스타트를 통해 실용적으로 저주를 극복할 수 있음을 입증한다. 이는 대규모 바이레벨 최적화와 메타러닝 시스템 설계 시 메모리·시간 효율을 크게 개선할 수 있는 중요한 지침을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기