CTC 기반 이중 스트리밍 TTS, 지연‑품질 트레이드오프를 혁신하다
CTC‑TTS는 GMM‑HMM 강제 정렬을 대체하는 CTC 정렬기와 단어‑쌍(bi‑word) 인터리빙 전략을 도입해, 텍스트와 음성 토큰을 효율적으로 결합한다. 토큰을 길이 방향으로 연결하는 CTC‑TTS‑L과 임베딩을 특성 차원에 쌓는 CTC‑TTS‑F 두 변형을 제시해 품질과 지연 사이의 균형을 조절한다. 실험 결과, 두 변형 모두 기존 LLMVox와 MFA 기반 방법보다 낮은 오류율과 짧은 첫 패킷 지연(FPL)을 달성했으며, 다중 화자 …
저자: Hanwen Liu, Saierdaer Yusuyin, Hao Huang
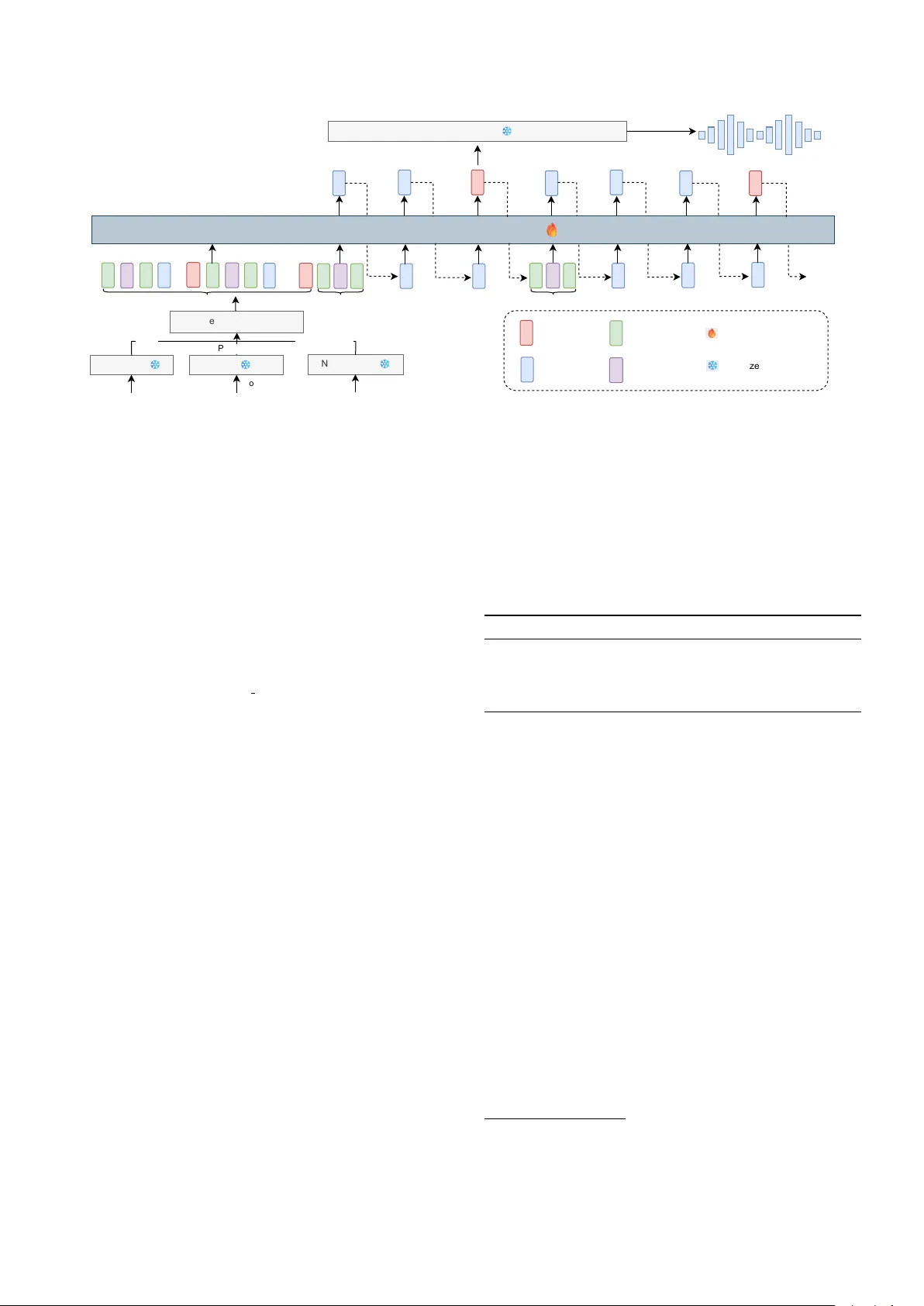
본 논문은 대규모 언어 모델(LLM) 기반 텍스트‑투‑스피치(TTS) 시스템이 실시간 이중 스트리밍 합성에 직면한 두 가지 핵심 문제, 즉 텍스트와 음성 간 정확한 정렬과 지연‑품질 균형을 맞춘 시퀀스 설계에 대한 해결책을 제시한다. 기존 연구는 주로 GMM‑HMM 기반의 Montreal Forced Aligner(MFA)를 이용해 강제 정렬을 수행했으며, 텍스트와 음성 토큰을 고정 비율로 교차 배치하는 방식을 사용했다. 이러한 파이프라인은 복잡하고, 정렬 정확도가 제한적이며, 고정 비율 인터리빙은 텍스트‑음성 정렬 규칙성을 충분히 반영하지 못한다는 한계가 있었다.
CTC‑TTS는 이러한 한계를 극복하기 위해 세 가지 주요 기여를 한다. 첫째, MFA 대신 Conformer 기반 CTC 자동 음성 인식(ASR) 모델을 활용해 텍스트‑음성 정렬을 수행한다. CTC는 블랭크 심볼을 도입해 연속된 동일 라벨을 자연스럽게 병합하고, Viterbi 알고리즘을 통해 최대 확률 정렬 경로를 추출한다. 이 정렬은 프레임‑정밀도가 필요 없는 구조적 정렬을 제공하며, 음소와 음성 토큰 사이의 1:3 비율을 이용해 각 음소에 세 개의 음성 토큰을 매핑한다.
둘째, ‘bi‑word’ 인터리빙 전략을 도입한다. 한 블록은 현재 단어의 음소, 단어 구분자(공백·구두점), 다음 단어의 음소, 그리고 현재 단어에 대응하는 음성 토큰 순으로 구성된다. 이렇게 하면 앞선 단어와 뒤따르는 단어의 음소 정보를 동시에 제공함으로써, 발음 컨텍스트를 보존하면서도 스트리밍 시 첫 번째 음성 토큰을 빠르게 생성할 수 있다.
셋째, 두 가지 인터리빙 구현을 설계한다. (a) CTC‑TTS‑L은 텍스트와 음성 토큰을 시퀀스 길이 차원에 순차적으로 연결한다. 이 방식은 모델이 두 단어의 음소를 모두 받은 뒤 음성 토큰을 예측하도록 하여, 품질 면에서 최고의 성능을 보인다. (b) CTC‑TTS‑F은 텍스트와 음성 임베딩을 특성 차원에 스택한다. 첫 번째 음소와 제로 텐서를 결합해 바로 음성 토큰을 출력하도록 설계했으며, 결과적으로 첫 패킷 지연(FPL)을 크게 감소시킨다. 두 변형 모두 동일한 디코더‑전용 트랜스포머를 사용하지만 입력 형식만 달라 품질‑지연 트레이드오프를 자유롭게 조절한다.
실험은 두 단계로 진행된다. 첫 번째는 단일 화자 Voice‑Assistant400K 데이터셋을 이용한 스트리밍 합성 평가이다. LLMVox와 비교했을 때, CTC‑TTS‑F은 WER 1.80 %·CER 1.04 %로 오류율을 크게 낮추고, FPL을 159 ms(8 % 감소)로 단축했다. CTC‑TTS‑L은 WER 1.50 %·CER 0.79 %까지 더 낮추지만 FPL이 210 ms로 약간 늘어났다. 두 모델 모두 UTMOS 4.15로 자연스러움은 동일했다.
두 번째는 LibriSpeech 기반 다중 화자 제로샷 평가이다. 여기서는 ELLA‑V와 MFA 기반 정렬을 재현하고, CTC 정렬 + bi‑word 시퀀스, MFA + bi‑word 시퀀스 등 다양한 조합을 비교한다. 연속성(Continuation) 과제에서 CTC‑TTS‑L은 WER 4.82 %·CER 2.47 %로 가장 낮은 오류율을 기록했고, MF A+bi‑word(5.14 %·2.63 %)보다 우수했다. 교차 화자(Cross‑speaker) 실험에서도 CTC‑TTS‑L이 WER 6.33 %·CER 3.21 %로 최고의 성능을 보였으며, 화자 유사도(SPK)와 MOS에서도 경쟁력을 유지했다.
핵심 인사이트는 다음과 같다. (1) CTC 기반 정렬은 강제 정렬보다 가볍고 유연하며, 단어 수준 정렬에 충분히 정확하다. (2) bi‑word 블록은 텍스트‑음성 정렬 규칙성을 효과적으로 반영하면서도 최소한의 앞선 컨텍스트(두 단어)만 요구한다. (3) 임베딩 스택 방식은 첫 패킷 지연을 크게 줄여 실시간 스트리밍에 적합하고, 길이 연결 방식은 품질을 극대화한다. (4) 동일한 백본에 두 변형을 적용함으로써, 서비스 요구에 따라 품질‑지연 트레이드오프를 손쉽게 선택할 수 있다. 향후 연구에서는 더 세밀한 음소‑단위 정렬, 다중 언어 확장, 대규모 멀티모달 프롬프트와의 결합을 통해 제로샷 성능을 향상시킬 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기