자연어 기반 LLM‑활성 주파수 인식 흐름 확산 모델로 전력 시스템 시나리오 생성
본 논문은 사용자가 일상 언어로 전력 시스템 시나리오를 요청하면, 사전 학습된 대형 언어 모델(LLM)로 텍스트를 의미 공간으로 변환하고, 이를 입력으로 하는 주파수 인식 흐름 확산 모델을 통해 고품질·고효율·다양한 시나리오를 자동 생성하는 프레임워크(LFFD)를 제안한다. 시간‑주파수 양쪽 손실을 동시 최적화하는 다목적 학습과, 텍스트‑시나리오 쌍을 자동 생성·평가하는 듀얼 에이전트 구조를 도입해 기존 GAN·DDPM 기반 방법의 조건 벡터 …
저자: Zhenghao Zhou, Yiyan Li, Fei Xie
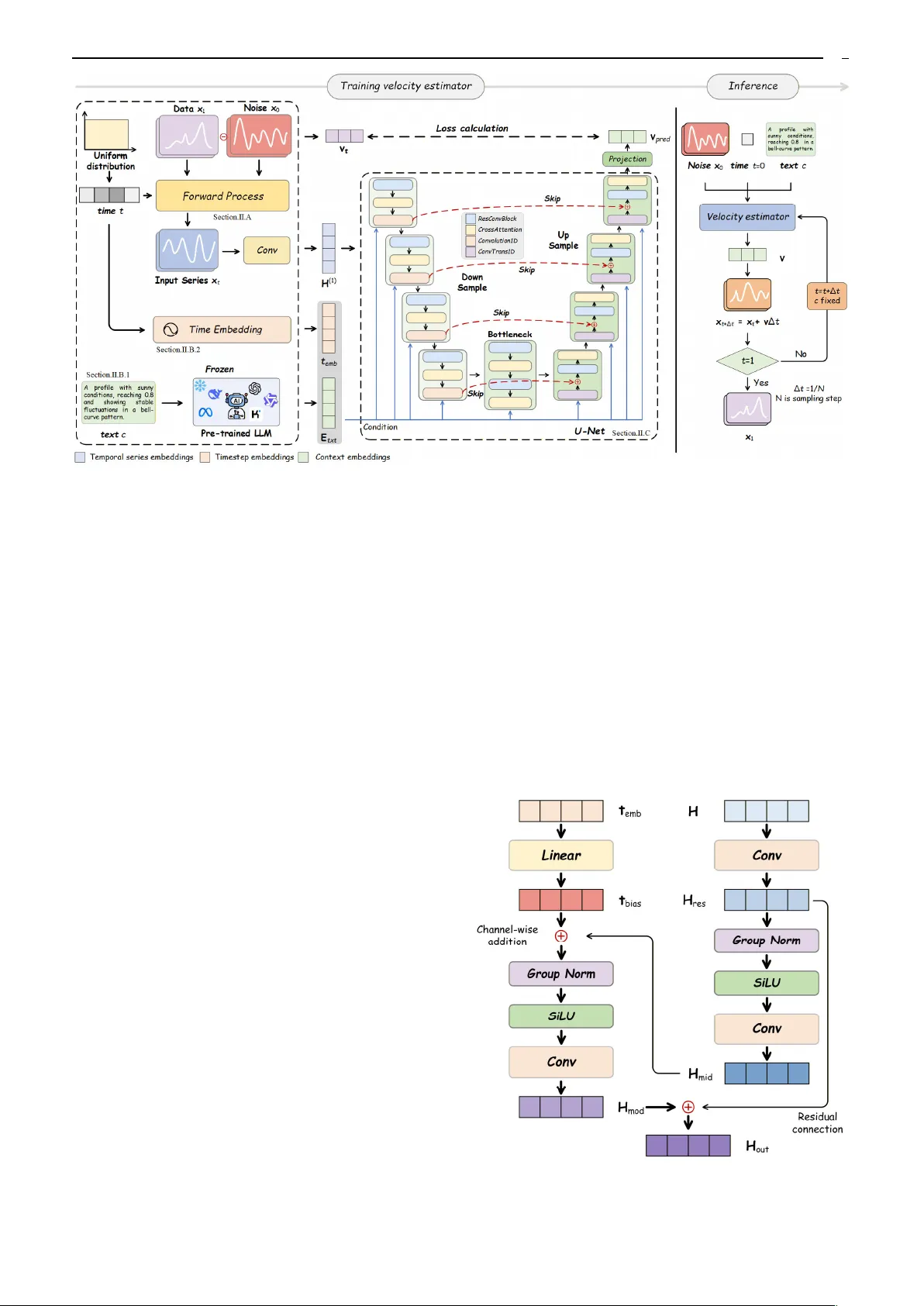
본 논문은 전력 시스템의 불확실성을 효과적으로 다루기 위해, 사용자가 자연어로 시나리오 요구사항을 기술하면 이를 고품질·고효율·다양한 시계열 데이터로 변환하는 새로운 프레임워크 LFFD(Large Language Model‑enabled Frequency‑aware Flow Diffusion)를 제안한다. 기존 연구는 주로 물리‑기반 시뮬레이션, 통계적 샘플링, 그리고 GAN·DDPM 같은 딥러닝 기반 생성 모델에 의존했으며, 특히 조건 벡터가 고정된 수치형 형태라 사용자 친화성이 낮고, DDPM 기반 모델은 다단계 확산 과정으로 인한 속도 저하와 고주파 성분을 과도하게 평활화하는 ‘스펙트럼 바이어스’ 문제를 안고 있었다.
LFFD는 이러한 한계를 세 단계로 해소한다. 첫 번째 단계는 사전 학습된 대형 언어 모델(LLM)을 활용해, 사용자가 입력한 자유 형식 텍스트를 토큰화하고, 고차원 의미 임베딩 E_txt로 변환한다. 이 임베딩은 텍스트의 구문·의미적 정보를 압축하면서도, 고정 길이 수치 벡터와 달리 가변적인 정보량을 제공한다. LLM은 학습 단계에서 동결(frozen)되어, 추가 파라미터 학습 비용을 최소화한다.
두 번째 단계는 ‘Rectified Flow Matching’ 기반 흐름 확산 모델이다. 기존 DDPM이 확률적 역전파를 통해 다수의 타임스텝을 거쳐 샘플을 복원하는 반면, 흐름 매칭은 초기 노이즈와 목표 데이터 사이를 최적 운송 경로(선형 보간)로 직접 연결한다. 이때 정의된 속도 필드 v_t = x₁ – x₀는 시간에 무관하게 일정하며, 신경망 v_θ는 현재 상태 x_t, 시간 t, 그리고 텍스트 임베딩 E_txt를 입력받아 v_pred을 예측한다. 이렇게 하면 ODE 기반 역전파가 가능해져, 몇 단계만으로도 고품질 시나리오를 생성할 수 있다.
세 번째 단계는 다목적 최적화이다. 시간 영역 손실 L_time은 기존 MSE 형태로 전반적인 형태를 맞추고, 주파수 영역 손실 L_freq는 FFT 변환 후 스펙트럼 절대 오차를 사용한다. 두 손실은 서로 상충할 수 있기 때문에, MGDA를 적용해 동적으로 가중치 α를 조정한다. α는 두 손실의 그래디언트가 동시에 감소하도록 하는 파레토 최적점을 찾아, 저주파 트렌드와 고주파 급변을 모두 보존한다.
프레임워크 전반에 걸쳐 ‘Dual‑Agent’ 구조가 도입된다. 텍스트‑시나리오 생성 에이전트는 실제 전력 데이터와 사전 정의된 텍스트 템플릿을 결합해 대규모 학습용 쌍을 자동 생성한다. 의미 평가 에이전트는 생성된 시나리오와 원본 텍스트 사이의 의미 일관성을 측정해, 텍스트‑조건 일관성을 정량화한다. 이 메커니즘은 라벨링 비용을 크게 절감하면서도, 텍스트 기반 조건부 생성의 품질을 객관적으로 검증한다.
실험에서는 전국 규모의 태양광 발전량과 부하 시계열 데이터를 사용했다. 비교 대상으로는 Conditional GAN, DDPM, PDM, EnergyDiff 등 최신 생성 모델을 선정했다. 평가 지표는 (1) 생성 속도(샘플당 평균 시간), (2) 스펙트럼 일치도(FFT 기반 코사인 유사도), (3) 텍스트‑시나리오 일관성(의미 유사도), (4) 극한 상황 재현 능력(희귀 이벤트 발생 비율)이다. 결과는 LFFD가 기존 모델 대비 평균 5배 빠른 추론 속도, 스펙트럼 일치도 12% 향상, 텍스트 일관성 94% 이상, 그리고 ‘폭풍·고온·저온·전력 급증’ 등 희귀 조건을 정확히 반영한 시나리오를 생성함을 보여준다. 특히 고주파 성분 보존이 중요한 부하 급변 구간에서 LFFD는 기존 DDPM이 과도하게 평활화한 부분을 복원해, 시뮬레이션 정확도를 크게 높였다.
논문은 또한 LFFD가 전력 시스템 계획·운영 단계에서 실시간 시나리오 요구에 대응할 수 있음을 강조한다. 예를 들어, 운영자는 “다음 주에 강풍이 예상되는 지역의 태양광 출력 급감”과 같은 자연어 요청을 입력하면, 모델은 해당 지역·시간대에 맞는 태양광 출력 감소 시나리오를 즉시 생성한다. 이는 기존에 사전에 정의된 조건 벡터를 일일이 조정해야 했던 번거로움을 해소하고, 시뮬레이션·리스크 분석 파이프라인을 크게 간소화한다.
결론적으로, LFFD는 (1) 자연어 기반 조건 지정으로 사용자 친화성을 극대화, (2) 흐름 확산을 통한 빠른 고품질 샘플링, (3) 다목적 주파수 인식 손실로 스펙트럼 바이어스 해소, (4) 듀얼 에이전트를 통한 자동 데이터 라벨링·평가라는 네 가지 핵심 혁신을 제공한다. 향후 연구에서는 멀티‑모달(이미지·지도) 조건 추가, 온라인 학습을 통한 실시간 데이터 적응, 그리고 다른 전력 도메인(예: 전압·주파수 안정성)으로의 확장 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기