헬스케어 환경에서 강건한 컨포멀 예측을 위한 EEG 분류 사례 연구
본 논문은 EEG 발작 분류에서 발생하는 환자 간 분포 이동과 라벨 불확실성을 고려해, 기존 컨포멀 예측의 커버리지를 크게 개선할 수 있는 개인화 캘리브레이션 기법을 제안한다. 이웃 기반 컨포멀(NCP)과 K‑means 기반 캘리브레이션을 적용해 표준 방법 대비 20% 이상 높은 커버리지를 달성하면서도 예측 집합 크기는 크게 증가시키지 않는다. 구현은 오픈소스 PyHealth에 제공된다.
저자: Arjun Chatterjee, Sayeed Sajjad Razin, John Wu
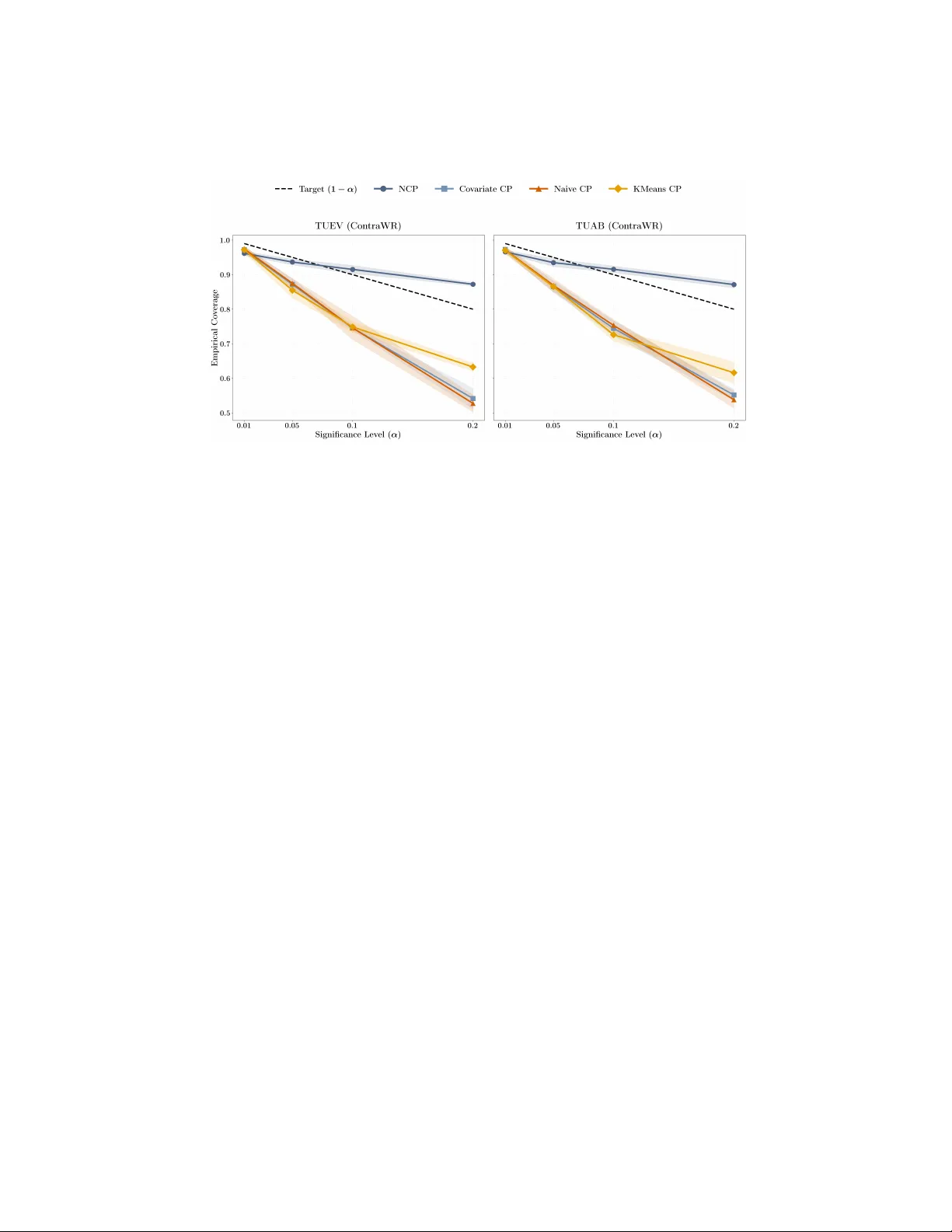
본 연구는 의료 AI 시스템에서 불확실성 정량화가 필수적인 상황을 배경으로, 특히 EEG 발작 분류 작업에서 나타나는 라벨 불확실성과 환자 간 분포 이동 문제에 초점을 맞춘다. 저자들은 기존 컨포멀 예측이 “교환 가능성(exchangeability)”이라는 i.i.d. 가정을 전제로 하여, 캘리브레이션 세트와 테스트 세트가 동일한 분포를 공유할 때만 이론적 커버리지 보장을 제공한다는 점을 지적한다. 그러나 실제 임상 환경에서는 환자 연령, 병력, 기록 장비, 측정 환경 등 다양한 요인으로 인해 데이터 분포가 지속적으로 변한다. 이러한 상황에서 전통적인 스플릿 컨포멀(SCP)은 목표 커버리지(1‑α)를 크게 벗어나 언더커버리지를 초래한다는 실증적 증거를 제시한다.
문제 해결을 위해 저자들은 두 가지 개인화 캘리브레이션 전략을 제안한다. 첫 번째는 K‑means 기반 개인화 컨포멀(K‑means CP)으로, 전체 캘리브레이션 데이터를 K개의 클러스터로 나눈 뒤 테스트 샘플이 속한 클러스터 내부 데이터만을 사용해 지역 임계값을 계산한다. 이는 전역 임계값보다 더 적합한 지역 분포를 반영한다. 두 번째이자 핵심인 이웃 기반 컨포멀(NCP)은 사전 학습된 임베딩(예: ContraWR 모델의 penultimate layer) 공간에서 테스트 샘플과 가장 가까운 k개의 캘리브레이션 샘플을 찾아, 각 이웃에 거리 기반 가중치를 부여한다. 비정상 점수 V(x, y)=1‑pθ(y|x)를 이용해 가중 평균 분위수를 추정하고, 이를 통해 테스트 샘플에 대한 예측 집합을 구성한다. NCP는 “지역 수준 신뢰도”를 제공하도록 설계돼, 동일 환자군 내에서는 높은 커버리지를 유지하고, 다른 군으로 이동했을 때도 변동성을 최소화한다.
이론적 분석에서는 커버리지 오차를 Cov(w, s) 형태로 분해한다. 여기서 w(x)=p_test(x)/p_cal(x) 는 밀도 비율, s(x)=c(x)‑(1‑α)는 지역 슬랙을 의미한다. NCP가 s(x)의 분산을 감소시키면 Cov(w, s)의 절대값이 감소하고, 따라서 최악의 경우에도 커버리지 오차가 작아진다. 이와 대비해 표준 SCP는 전역 임계값 하나만 사용하므로 s(x)의 변동성이 크고, 밀도 비율 w(x)와의 상관관계가 커져 커버리지 손실이 심해진다.
실험은 두 개의 공개 EEG 데이터셋인 TUAB(정상 vs 비정상 이진 분류)와 TUEV(여섯 종류의 이벤트 다중 클래스 분류)를 사용했다. 데이터는 60% 훈련, 10% 검증, 15% 캘리브레이션, 15% 테스트로 분할했으며, ContraWR 모델을 기본 분류기로 채택했다. 네 가지 컨포멀 방법(Naive CP, Covariate CP, K‑means CP, NCP)을 각각 5개의 랜덤 시드에 대해 평가했다. 결과는 다음과 같다. (1) NCP는 α=0.02에서 Naive CP 대비 약 25% 높은 커버리지를 달성했으며, α가 작아질수록(고위험 상황) 커버리지는 목표선에 근접했지만 완전히 도달하지는 못했다. (2) K‑means CP도 커버리지를 개선했지만, NCP에 비해 변동성이 커서 높은 α 구간에서 예측 집합 크기가 다소 늘어났다. (3) Covariate CP는 고차원 EEG 임베딩에서 커널 밀도 추정이 부정확해 실제 커버리지 개선 효과가 없었다. (4) 개인화 방법들은 예측 집합 크기 증가가 미미해, 임상 현장에서 실시간 의사결정에 큰 부담을 주지 않는다.
결론적으로, 개인화 캘리브레이션, 특히 이웃 기반 컨포멀(NCP)은 EEG와 같이 분포 이동이 빈번한 의료 데이터에 대해 기존 컨포멀 방법보다 훨씬 견고한 커버리지를 제공한다. 다만, α가 매우 낮은 고위험 상황에서는 아직 목표 커버리지를 완전히 만족시키지 못하므로, 추가적인 안전 장치나 보수적 임계값 설정이 필요하다. 향후 연구에서는 (1) 다른 의료 분야(예: 영상, 전자 차트)로 확장, (2) 더 정교한 임베딩 및 거리 학습, (3) 온라인 적응형 캘리브레이션을 통한 실시간 분포 변화 대응 등을 제시한다. 구현 코드는 오픈소스 PyHealth에 포함되어 있어, 연구자와 실무자가 손쉽게 재현·응용할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기