참조 없이 단일분자 위치 측정 데이터를 해석하는 통계적 프레임워크
본 논문은 MINFLUX와 같은 초고해상도 단일분자 현미경 데이터에서 측정 불확실성을 고려한 베이지안 클러스터링, 빈 공간 탐지 기반 중심 검출, RJMCMC를 이용한 구조 중심 추정, 그리고 템플릿 없이 반복 구조를 재구성하는 전체 파이프라인을 제시한다. 시뮬레이션 및 실제 Nup96, DNA‑Origami 3×3 데이터에 적용해 클러스터링 정확도 ARI ≥ 0.75, 구조 검출 F1 ≈ 0.9를 달성하였다.
저자: Jack Peyton, Benjamin Davis, Emily Gribbin
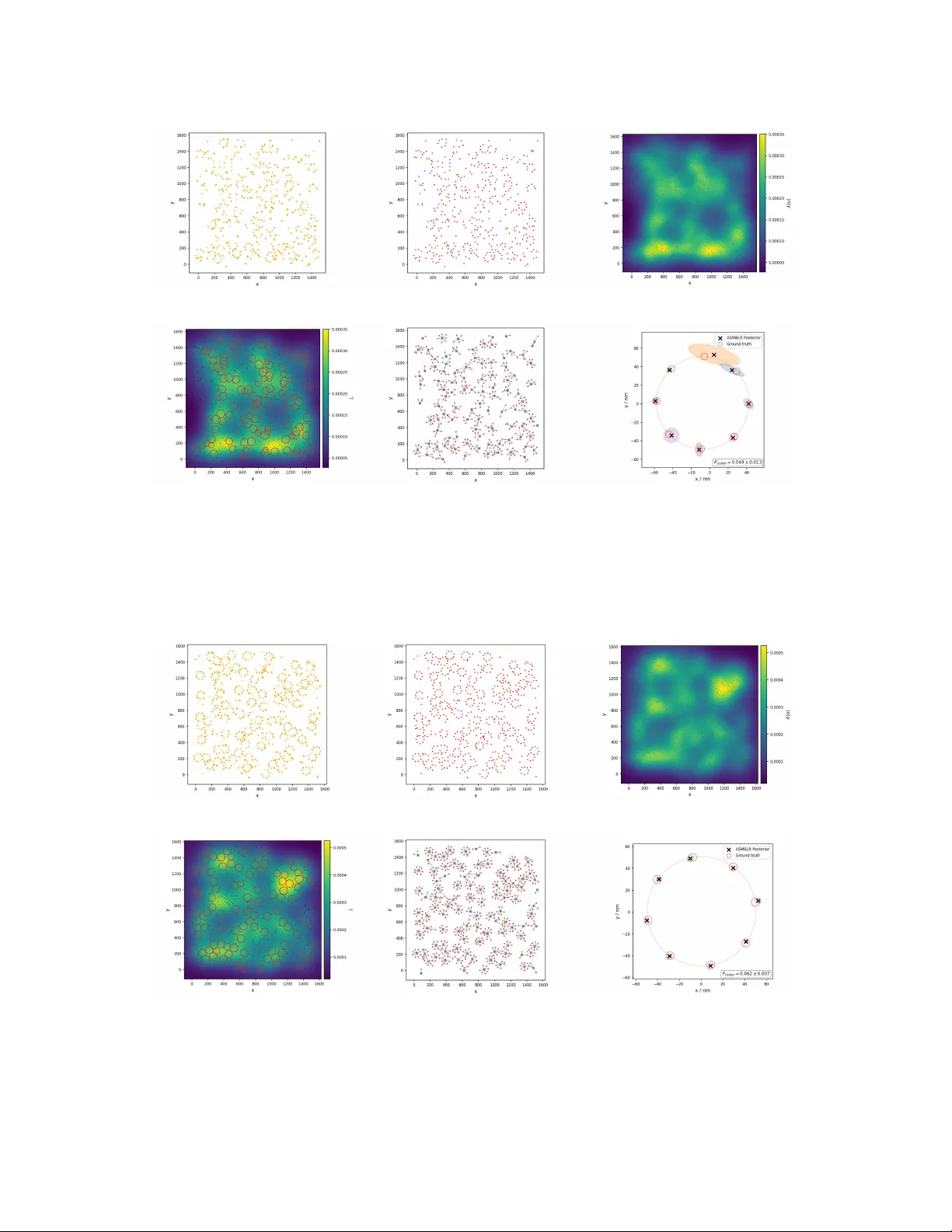
본 연구는 MINFLUX와 같은 초고해상도 단일분자 현미경 기술에서 얻어지는 점군 데이터를 ‘참조 없이(reference‑free)’ 해석하기 위한 전반적인 통계적 파이프라인을 제시한다. 논문은 크게 네 가지 문제점—측정 불확실성, 라벨링 효율 저하, 스푸리어스 검출, 그리고 템플릿 의존성—을 지적하고, 각각을 해결하기 위한 방법론을 단계별로 설계하였다.
첫 번째 단계인 GROUP A는 기존 밀도 기반 클러스터링(DBSCAN, HDBSCAN)의 한계를 극복한다. 측정마다 제공되는 위치 불확실성(σ)을 베이지안 사후 확률로 활용하고, 쌍별 베이즈 팩터를 계산해 Infomap 커뮤니티 탐지 알고리즘에 입력한다. 이 과정은 거리 임계값을 필요로 하지 않으며, 자동으로 측정들을 동일 발광체(emitters)로 그룹화한다. 시뮬레이션 결과, σ가 0.5 nm에서 10 nm까지 증가해도 ARI가 0.75 이상을 유지해 기존 방법보다 월등히 강인함을 보였다.
두 번째 단계인 Voidwalker‑Gibbs는 점군 내 ‘빈 공간’을 통계적으로 탐지한다. 빈 공간은 구조적 의미를 가진 ‘구멍(void)’으로 해석되며, 이를 기반으로 사전 분포와 제안(proposal) 공간을 정의한다. 빈 공간 탐지는 공간점 과정 이론에 기반해 유의미한 공백을 식별하고, 이를 통해 RJMCMC 샘플링이 탐색할 파라미터 공간을 효율적으로 제한한다. 실험에서는 라벨링 효율이 30 % 이하이고 스푸리어스 비율이 30 %까지 상승해도 중심 검출 F1 점수가 0.6 ~ 0.75 수준을 유지하였다.
세 번째 단계는 RJMCMC 기반 구조 중심 추정이다. 구조 중심을 Gibbs 점 과정으로 모델링하고, BaGoL에서 영감을 받은 이동 집합(move set)을 사용해 발광체‑중심 할당 확률을 샘플링한다. 각 발광체는 여러 중심에 대한 할당 확률(마크) 벡터를 갖게 되며, 이는 이후 단계에서 불확실성을 정량화하는 데 활용된다. 라벨링 효율이 0.9 이상일 때 중심 위치 오차는 평균 1.5 nm 이하이며, 반경 파라미터 추정도 실제값과 3 % 이내의 편차를 보였다.
네 번째 단계는 마크드 점 과정을 이용한 슈퍼‑구조 탐지와 ASMBLR에 의한 템플릿‑프리 재구성이다. 중심 간 거리와 할당 확률을 이용해 무작위 퍼뮤테이션 테스트를 수행, CSR(완전 무작위) 가설 대비 유의미한 근접성을 보이는 중심 쌍을 ‘슈퍼‑구조’로 정의한다. 라벨링 효율이 0.9 ~ 1.0이고 스푸리어스 비율이 10 % 이하일 때 F1 점수가 0.8 ~ 0.9에 달해 실제 복합 구조를 정확히 식별한다. 이후 ASMBLR은 샘플링된 클리크(2 ~ 8개의 발광체)들을 이용해 구조 단위(예: Nup96의 8‑점 원형, DNA‑Origami 3×3 격자)를 템플릿 없이 재구성한다. 재구성된 구조는 평균 2 nm 이하의 오차로 원본과 일치한다.
전체 파이프라인은 1,600개의 시뮬레이션 데이터와 실제 MINFLUX 측정 Nup96, DNA‑Origami 데이터를 대상으로 검증되었다. 각 단계는 독립적인 성능 지표(ARI, FMI, NMI, F1, Gelman‑Rubin ˆR 등)로 평가되었으며, 전반적으로 높은 정확도와 강인성을 보였다. 특히, 측정 불확실성, 라벨링 효율, 스푸리어스 비율 등 다양한 실험 조건에서도 일관된 결과를 제공함으로써, 기존 방법이 갖는 파라미터 튜닝 의존성을 크게 완화하였다.
논문의 의의는 다음과 같다. 첫째, 측정 불확실성을 직접 모델링함으로써 파라미터‑프리 클러스터링을 구현하였다. 둘째, 빈 공간 탐지를 통해 사전 분포를 데이터‑드리븐하게 정의함으로써 중심 검출의 효율성을 높였다. 셋째, RJMCMC와 마크드 점 과정을 결합해 구조 중심 할당의 불확실성을 정량화하였다. 넷째, 템플릿‑프리 슈퍼‑구조 탐지와 ASMBLR을 통해 반복 구조를 자동으로 재구성함으로써, 사전 지식에 의존하지 않는 ‘참조 없이’ 분석이 가능하도록 했다. 이러한 통합 프레임워크는 MINFLUX뿐 아니라 다른 SMLM 기법에도 적용 가능하며, 실험 설계 단계에서 정보‑이론적 한계를 사전에 평가하고, 과도한 해석 편향을 방지하는 데 유용한 도구가 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기