오디오 대형 언어 모델을 활용한 반복적 의사라벨 정제 프레임워크 ReHear
ReHear는 음성 인식 모델이 생성한 초안과 원본 오디오를 동시에 입력으로 받아, 멀티모달 오디오 LLM이 오류를 교정하고 정제된 의사라벨을 만든다. 이 정제된 라벨을 이용해 ASR 모델을 반복적으로 재학습함으로써 기존 의사라벨링 방식에서 발생하던 확인 편향과 오류 누적을 크게 감소시킨다. 실험 결과, 재무 회의, 대규모 기업 발표, 회의 녹음 등 다양한 도메인에서 기존 감독 학습 및 전통적인 의사라벨링보다 일관되게 낮은 WER을 달성하였다.
저자: Zefang Liu, Chenyang Zhu, Sangwoo Cho
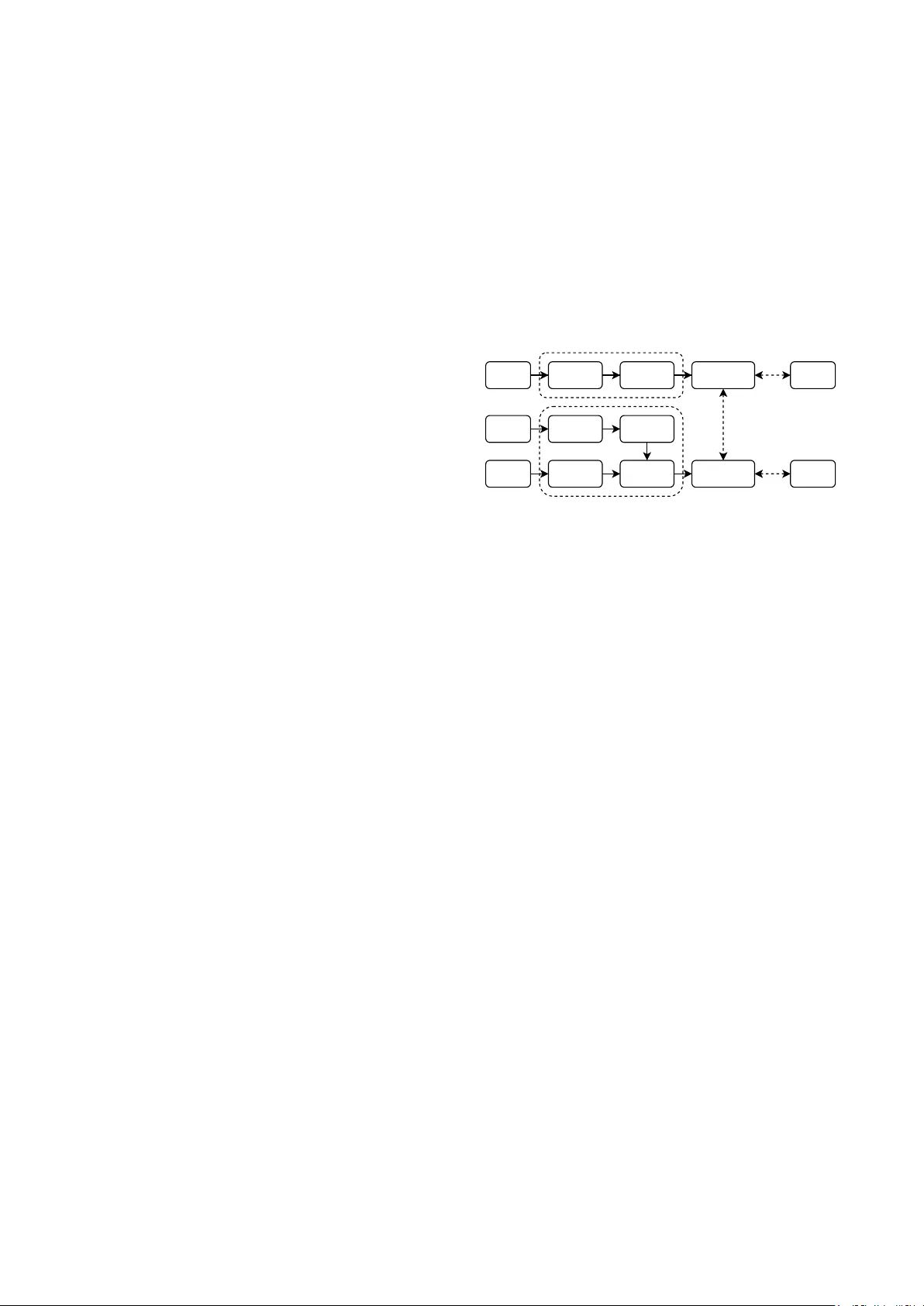
본 논문은 반자동 음성 인식(ASR) 시스템의 라벨 부족 문제를 해결하고자, 기존의 의사라벨링(pseudo‑labeling) 방식에서 발생하는 확인 편향과 오류 누적을 완화하는 새로운 프레임워크인 ReHear를 제안한다. ReHear는 두 개의 핵심 구성요소, 즉 기본 ASR 모델(M_A)과 멀티모달 오디오 대형 언어 모델(M_L)로 이루어진 협업 루프를 기반으로 한다. 첫 단계에서 M_A는 라벨이 있는 데이터와 라벨이 없는 데이터 모두에 대해 초기 전사 가설을 생성한다. 라벨이 있는 경우에는 (오디오, 실제 라벨, 가설) 삼중항을, 라벨이 없는 경우에는 (오디오, 가설) 쌍을 만든다. 이 데이터를 이용해 M_L을 instruction‑tuned 형태로 fine‑tuning한다. 여기서 프롬프트는 “Hypothesis: <가설>” 형태로 제공되며, 모델은 “음성을 정확히 그대로 전사하라”는 명령을 수행한다. 이 과정에서 M_L은 음성 신호의 스펙트럼, 억양, 발음 정보를 직접 활용해 텍스트‑기반 교정기가 놓치기 쉬운 오류를 복원한다. 예를 들어, “bank”와 “bang”처럼 발음이 유사하지만 문맥에 따라 의미가 달라지는 경우, 오디오 정보를 통해 올바른 단어를 선택한다.
M_L이 교정한 라벨 y″_u는 선택적 필터링 과정을 거친다. 규칙 기반 필터는 교정 전후의 문자 오류율(CER), 길이 비율, 고유 토큰 비율, 숫자 불일치 등을 기준으로 하여, 과도한 변형이나 허위 생성(hallucination)을 차단한다. 모델 기반 필터는 별도 텍스트 인코더를 학습시켜, 교정 라벨이 실제 WER을 감소시키는지를 이진 분류기로 판단한다. 필터링된 고품질 라벨 집합 D_fU와 원본 라벨 D_L를 합쳐 M_A를 재학습한다. 이 과정을 여러 번 반복함으로써, M_A는 점차 더 정확한 가설을 생성하고, M_L은 점점 더 정교한 교정 능력을 얻게 된다. 최종적으로는 라벨이 없는 방대한 음성 데이터에서도 높은 품질의 의사라벨을 얻어, 라벨이 제한된 도메인에서도 ASR 성능을 크게 향상시킬 수 있다.
실험은 네 개의 실제 데이터셋( Earnings‑21, Earnings‑22, SPGISpeech 소규모 버전, AMI 회의)에서 수행되었다. 기본 ASR 모델은 Whisper‑Large‑v3, 오디오 LLM은 Voxtral‑Mini‑3B‑2507, 필터는 DeBERTa‑v3‑Base를 사용하였다. 파라미터 효율성을 위해 LoRA와 4‑bit QLoRA를 적용했으며, 각 모델은 5 epoch, 배치 128, 코사인 학습률 스케줄링으로 훈련되었다. 비교 대상으로는 전통적인 감독 학습(ISL), 반복적 의사라벨링(IPL) 및 필터링된 IPL이 포함되었다. 결과는 표 2에 요약되어 있으며, ReHear는 모든 데이터셋에서 ISL과 IPL을 능가한다. 특히 Earnings‑21/22와 AMI와 같이 억양·다중 화자·노이즈가 복합적으로 존재하는 환경에서 WER 감소폭이 가장 크게 나타났다. 필터링 없이도 ReHear는 IPL+Rule보다 우수했으며, 이는 오디오 LLM이 제공하는 교정 능력이 라벨 품질을 자체적으로 보장한다는 점을 의미한다.
추가적인 분석에서는 모달리티와 포지셔닝의 영향을 조사하였다. 텍스트‑전용 교정(오디오 없이) 대비 오디오‑텍스트 멀티모달 교정이 평균 0.4%p 이상의 WER 개선을 가져왔으며, 오디오 특성의 위치 정보를 포함한 입력이 교정 정확도에 긍정적인 영향을 미쳤다. 또한, 규칙 기반 필터가 가장 안정적인 성능을 보였고, 모델 기반 필터는 라벨이 충분히 많지 않을 경우 과적합 위험이 있음을 확인하였다.
본 연구의 의의는 크게 세 가지로 정리할 수 있다. 첫째, 오디오‑텍스트 멀티모달 LLM을 의사라벨 교정기에 적용함으로써 기존 텍스트‑전용 교정기의 한계를 극복하고, 음성 신호 자체를 활용한 정교한 오류 복원이 가능함을 입증하였다. 둘째, ASR 모델과 오디오 LLM 사이의 반복적 공동 학습 루프를 설계해, 두 모델이 상호 보완적으로 성능을 향상시키는 시너지 효과를 실증하였다. 셋째, 최종 배포 단계에서는 경량화된 ASR 모델만을 사용하도록 설계함으로써, 실시간 서비스에 적용 가능한 비용 효율적인 솔루션을 제공한다. 향후 연구에서는 더 큰 규모와 다언어 지원을 갖춘 오디오 LLM, 실시간 스트리밍 환경에서의 교정 지연 최소화, 그리고 교정 과정에서의 신뢰도 추정 방법 등을 탐구할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기