다중목표 강화학습을 위한 병렬 보상 통합 및 대칭성 활용 PRISM
PRISM은 시간 빈도 차이가 큰 다중목표 강화학습에서 밀집 보상과 희소 보상의 학습 불균형을 해소한다. ReSymNet이라는 잔차 네트워크로 희소 보상을 밀집 형태로 예측해 보상 주기를 맞추고, SymReg라는 반사 대칭 정규화로 정책을 대칭 불변 공간에 제한한다. 이론적 복잡도 감소와 경험적 하이퍼볼륨 향상을 통해 MuJoCo 벤치마크에서 기존 희소 보상 기반 방법보다 100 % 이상, 전밀집 보상 오라클보다 최대 32 % 개선한다.
저자: Finn van der Knaap, Kejiang Qian, Zheng Xu
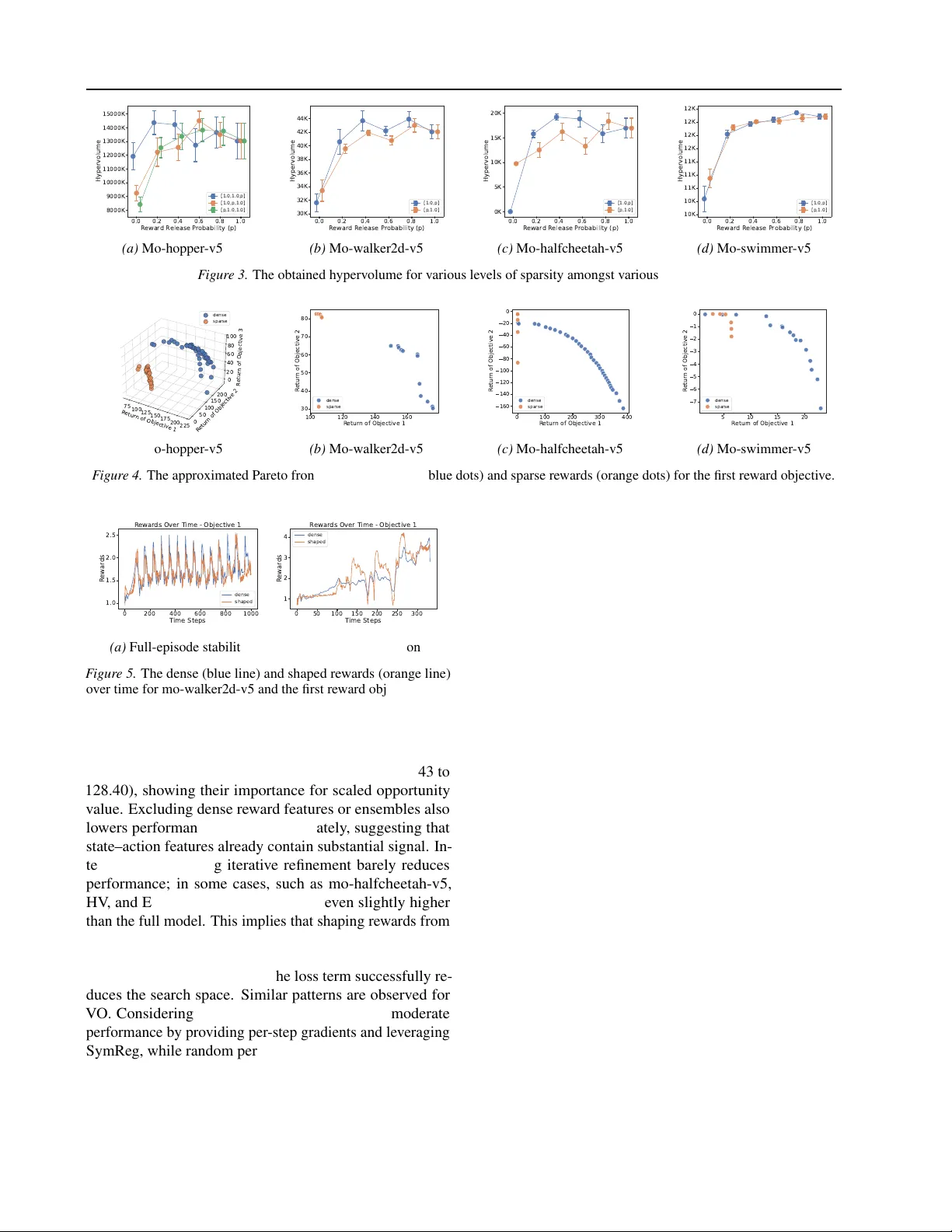
본 논문은 다중목표 강화학습(Multi‑Objective Reinforcement Learning, MORL)에서 보상 채널 간 시간‑주파수 차이가 학습 효율을 크게 저해한다는 사실을 지적한다. 밀집 보상은 매 타임스텝마다 즉각적인 피드백을 제공해 빠른 정책 업데이트를 가능하게 하지만, 희소 보상은 에피소드 종료 시점에만 누적값을 제공한다. 이러한 비대칭은 특히 물리적 대칭성을 갖는 로봇 시스템(예: 양쪽 다리가 대칭인 2‑다리 로봇)에서 한쪽 방향에 과도하게 편향된 정책을 초래한다. 기존의 보상 shaping 기법은 단일 목표 환경에 초점을 맞추었으며, MORL에서 서로 다른 스케일과 빈도의 보상을 동시에 정렬하는 방법이 부족했다.
PRISM은 이 문제를 두 단계로 해결한다. 첫 번째 단계는 ReSymNet(Reward Symmetry Network)이다. ReSymNet은 상태‑행동 쌍 \((s_t, a_t)\)와 현재 시점의 밀집 보상 \(\mathbf{r}^{dense}_t\)을 입력으로 받아, 잔차 블록(residual blocks)으로 구성된 신경망을 통해 “스케일된 기회 가치(scaled opportunity value)”를 학습한다. 이 값은 희소 보상의 순간값을 근사하는 역할을 하며, 전체 에피소드에 걸쳐 예측된 순간값들의 합이 실제 누적 희소 보상과 일치하도록 MSE 손실 \(\mathcal{L}(\psi)=\sum_{\tau}\bigl(\sum_{t\in\tau}R_{pred}(h_t;\psi)-R^{sp}(\tau)\bigr)^2\)을 최소화한다. 네트워크는 앙상블 방식으로 불확실성을 감소시키고, 온‑폴리시 데이터(에이전트가 학습하면서 수집한 데이터)를 주기적으로 재학습함으로써 초기 랜덤 정책에서 시작한 분포 이동에 적응한다. 이렇게 함으로써 희소 보상이 밀집 형태로 변환되어, 시간‑주파수 차이가 해소되고 모든 보상 채널이 동일한 학습 속도로 반영된다.
두 번째 단계는 SymReg(Symmetry Regulariser)이다. 물리적 대칭성을 수학적으로 표현하기 위해 반사 대칭 그룹 \(G=\mathbb{Z}_2\) 를 도입한다. 상태 공간 \(S\)와 행동 공간 \(A\)를 비대칭 부분(\(s^{asym}, a^{asym}\))과 대칭 부분(\(s^{sym}, a^{sym}\))으로 분할하고, 변환 연산자 \(L_g(s) = (s^{asym}, -s^{sym})\), \(K_g(a) = (a^{asym}, -a^{sym})\)를 정의한다. 정책 \(\pi\)가 반사 대칭 불변(equivariant)하려면 \(\pi(L_g(s)) = K_g(\pi(s))\)를 만족해야 한다. 이를 강제하기 위해 대칭 손실 \(\mathcal{L}_{eq}= \mathbb{E}_{s\sim\mathcal{D}}\bigl\|\pi(L_g(s);\phi) - K_g(\pi(s;\phi))\bigr\|^2\)를 도입하고, 전체 목표 함수에 \(\lambda\) 가중치로 결합한다: \(\mathcal{L}_{total}= J_{\pi}(\phi) + \lambda \mathcal{L}_{eq}\). 이 정규화는 정책 탐색 공간을 대칭‑불변 부분으로 투사하고, 커버링 넘버와 라다머 복잡도를 이론적으로 감소시켜 일반화 경계를 향상시킨다.
이론적 분석에서는 (1) ReSymNet의 가정 하에 보상 예측 오차가 제한됨을 보이고, (2) SymReg에 의해 정책 공간이 대칭‑불변 하위공간으로 제한되면 함수 클래스의 복잡도가 감소한다는 정리(첨부 파일 B.8)를 제시한다. 가정 5.2(보상의 유계성)와 가정 5.3(보상의 Lipschitz 연속성)을 바탕으로, 정책 간 반환 차이가 정책 거리 \(d(\pi,\tilde\pi)\)에 비례함을 증명한다.
실험은 MuJoCo 기반 MORL 환경(예: Hopper‑Multi, Walker2d‑Multi 등)에서 CAPQL(Concave‑Augmented Pareto Q‑learning)을 백본으로 사용한다. 실험 설정은 두 종류의 보상 채널을 정의한다: (i) 밀집 보상(에너지 효율, 관절 토크 등)과 (ii) 희소 보상(목표 도달 여부, 장기 안전성 등). PRISM은 기본 희소 보상만 사용한 베이스라인 대비 하이퍼볼륨을 평균 110 %~150 % 향상시켰으며, 전밀집 보상 오라클(모든 보상이 밀집 형태로 제공되는 이상적인 상황) 대비 최대 32 %의 추가 이득을 기록했다. 또한 정책의 분포적 균형성(각 목표 간 비율)과 로봇의 물리적 대칭성 유지 측면에서도 개선이 확인되었다. Ablation 실험에서는 (a) ReSymNet만 사용했을 때는 보상 정렬 효과는 있으나 대칭성 위반으로 인해 일부 목표에서 과적합이 발생하고, (b) SymReg만 적용했을 때는 대칭성은 유지되지만 희소 보상의 신호가 부족해 학습 속도가 느려지는 것을 보여준다. 두 모듈을 결합한 PRISM이 가장 높은 성능을 달성한다.
결론적으로 PRISM은 (1) 보상 주기의 이질성을 모델 기반 보상 재구성으로 정규화하고, (2) 물리적 대칭성을 정책에 강제함으로써 샘플 효율성과 일반화 능력을 동시에 향상시킨다. 이 접근은 복잡한 다중목표 로봇 제어, 자율주행 등 시간‑스케일이 다른 여러 목표를 동시에 최적화해야 하는 실제 시스템에 적용 가능성이 크다. 향후 연구에서는 대칭성 외에도 회전·전이 대칭 등 보다 일반적인 군(Group) 구조를 활용하거나, 비대칭 환경에서도 유연하게 적용할 수 있는 적응형 대칭 정규화 기법을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기