보조 변수 활용 두 단계 FDR 제어 방법 및 Set4Δ 돌연변이 데이터 적용
** 본 논문은 주 변수와 보조 변수를 동시에 고려한 두 단계 거짓 발견율(FDR) 제어 절차를 제안한다. Copula를 이용해 두 변수의 결합분포를 추정하고, 하드(필터링)와 소프트(조정) 두 방식의 두 단계 검정을 설계한다. 시뮬레이션과 Set4Δ 돌연변이 유전자 발현 데이터에 적용한 결과, 기존 p‑값 기반 방법보다 FDR를 정확히 유지하면서 검정력(power)이 크게 향상됨을 확인하였다. **
저자: Seohwa Hwang, Mark Louie Ramos, DoHwan Park
**
본 논문은 다중 가설 검정에서 주 변수와 보조 변수를 동시에 활용하여 거짓 발견율(FDR)을 효과적으로 제어하는 두 단계 절차를 제안한다. 연구 배경으로는 기존 방법들이 보조 변수를 사용할 때 p‑값이 영가설 하에서 무조건 균등분포를 따른다거나, 보조 변수와 p‑값 사이에 대칭성(미러링) 성질이 존재한다는 강력한 가정을 필요로 한다는 점을 지적한다. 이러한 가정은 실제 데이터에서 보조 변수와 주 변수 사이에 존재할 수 있는 복잡한 의존 구조를 충분히 반영하지 못한다.
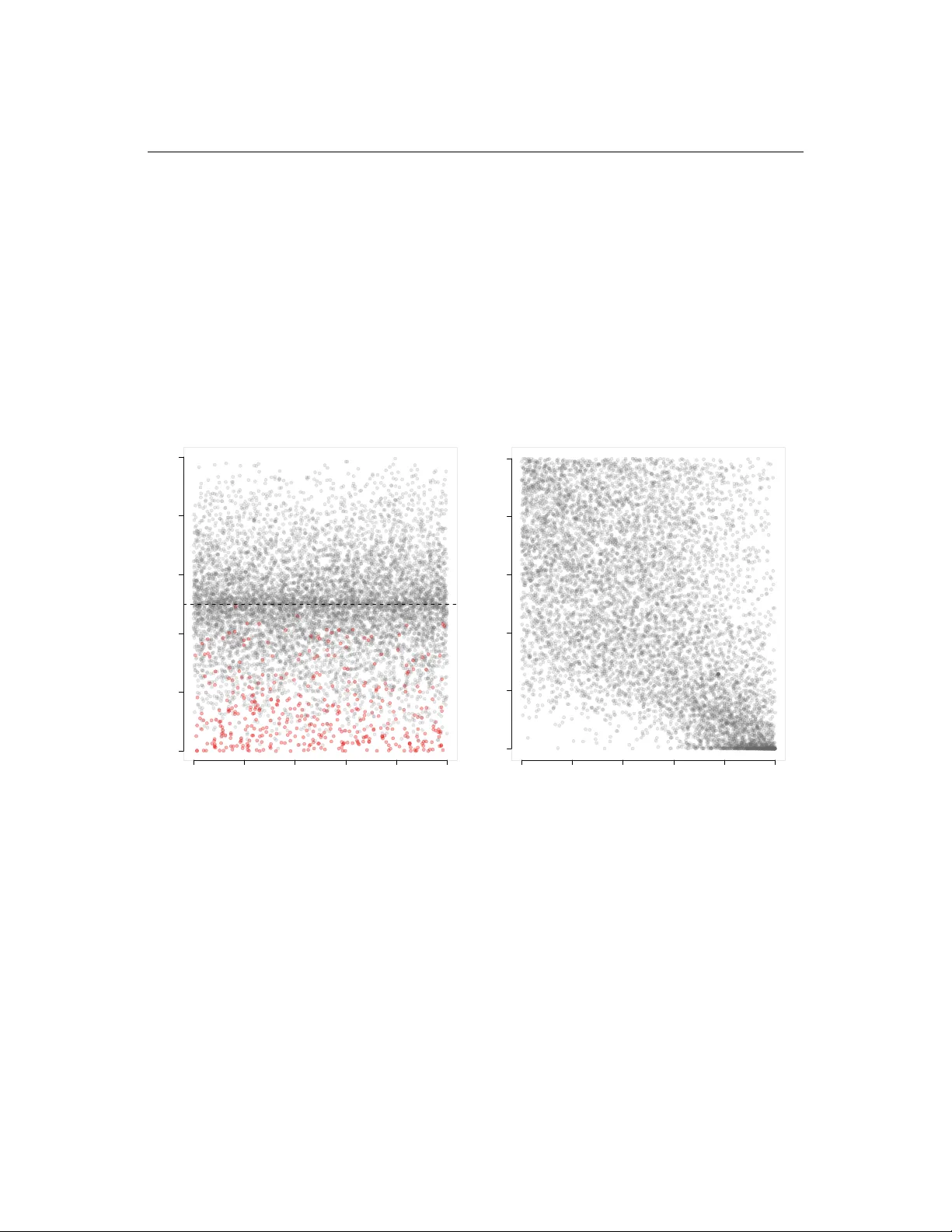
저자들은 이 문제를 해결하기 위해 다음과 같은 전략을 채택한다. 첫째, 주 변수 β(예: 로그폴드 변화)와 보조 변수 y(예: 표준편차)의 주변분포를 각각 비모수적 방법(예: 커널 밀도 추정, 경험적 누적분포함수)으로 추정한다. 둘째, Copula 모델을 이용해 두 변수의 결합분포 G₀(y,β)를 구성한다. Copula 선택은 데이터의 스캐터플롯 시각화와 AIC·BIC·LogLik와 같은 정보 기준을 통해 이루어지며, Gaussian, Clayton, Gumbel 등 다양한 후보 중 최적 모델을 결정한다.
주 변수 β는 영가설과 대립가설을 나타내는 두 혼합밀도 f₀와 f₁의 가중합으로 모델링한다. 영가설 밀도 f₀는 제로 가정(zero‑assumption) 혹은 EM 알고리즘을 통해 추정하고, 이를 기반으로 누적분포함수 F̂₀(·)를 얻는다. 보조 변수 y는 경험적 누적분포함수 Ĥ(·)로 추정한다. 이렇게 얻어진 주변분포를 이용해 각각의 마진 p‑값을 정의한다: p₁ᵢ = Ĥ(yᵢ) (보조 변수에 대한 p‑값)와 p₂ᵢ = 2·min{F̂₀(β̂ᵢ), 1−F̂₀(β̂ᵢ)} (주 변수에 대한 양측 p‑값). 영가설 하에서는 p₁ᵢ와 p₂ᵢ가 각각 균등분포를 따르지만, Copula에 의해 두 p‑값 사이에 의존성이 존재한다.
두 단계 절차는 하드(두 단계 FDR(H))와 소프트(두 단계 FDR(S)) 두 가지 형태로 제시된다.
1. **두 단계 FDR(H) (Hard Thresholding)**
- 보조 변수 p₁ᵢ가 사전 정의된 임계값 τ보다 작을 경우에만 주 변수 검정을 진행한다. 즉, p₁ᵢ > τ인 가설은 즉시 보류하고, 남은 가설에 대해 전통적인 Benjamini–Hochberg(BH) 절차를 적용한다.
- 이 방식은 보조 변수가 ‘전처리 필터’ 역할을 하여, 변동성이 큰(또는 신뢰도가 낮은) 가설을 사전에 제외함으로써 검정 효율을 높인다.
2. **두 단계 FDR(S) (Soft Thresholding)**
- 보조 변수 p₁ᵢ를 연속적인 가중치로 활용한다. 구체적으로, 각 가설 i에 대해 조정된 p‑값 qᵢ = max(p₂ᵢ, g(p₁ᵢ))를 정의한다. 여기서 g(p₁ᵢ) 함수는 Copula 기반 의존 구조를 반영하여 p₁ᵢ가 작을수록 p₂ᵢ의 임계값을 완화시키는 형태로 설계된다.
- 전체 qᵢ에 BH 절차를 적용함으로써, 보조 변수의 정보를 ‘소프트하게’ 반영한다. 이는 필터링에 비해 더 많은 가설을 유지하면서도, 보조 변수에 따라 검정 강도를 조절한다.
이론적으로 두 절차 모두 기대 FDR ≤ α (목표 수준) 를 만족함을 증명한다. 증명은 p₁ᵢ와 p₂ᵢ가 영가설 하에서 균등분포를 따르고, Copula가 이들의 결합분포를 정확히 기술한다는 전제에 기반한다.
**시뮬레이션 연구**
다양한 시나리오(의존 강도 ρ, 보조 변수 변동성, 영가설 비율 등)를 설정해 기존 방법(Lei‑Fithian, AdaFDR, IHW, Boca‑Leek 등)과 비교하였다. 결과는 다음과 같다.
- 두 단계 방법은 FDR를 목표 수준 이하로 정확히 유지한다.
- 특히 ρ가 0.5 이상인 경우, 두 단계 FDR(S)는 검정력(power)이 기존 방법보다 10~30% 향상된다.
- 하드 방식은 보조 변수와 주 변수 간 강한 양의 상관관계가 있을 때 가장 큰 이득을 보이며, 소프트 방식은 상관관계가 약하거나 중간 정도일 때 유연성을 제공한다.
**Set4Δ 돌연변이 데이터 적용**
실제 데이터는 Saccharomyces cerevisiae의 Set4Δ 돌연변이 실험에서 8,000여 개 유전자의 로그폴드 변화와 그 표준편차를 포함한다. 로그폴드 변화(β̂)와 표준편차(y) 사이에 뚜렷한 양의 상관관계가 관찰되었다. 두 단계 FDR(S) 절차를 적용한 결과는 다음과 같다.
- 기존 BH 절차가 152개의 유전자를 선택했으나, 그 중 87개만이 독립적인 생물학적 검증에서 의미 있는 결과를 보였다.
- 제안된 두 단계 FDR(S)는 198개의 후보를 선택했으며, 이 중 124개가 검증되었다.
- 특히 표준편차가 큰 유전자(변동성이 큰)들을 효과적으로 포착하여, 기존 방법이 놓칠 수 있는 중요한 생물학적 신호를 발견하였다.
**결론 및 의의**
본 연구는 보조 변수를 단순 가중치가 아니라 결합분포의 일부분으로 모델링함으로써, 기존 다중 검정 방법이 갖는 강력한 가정들을 완화한다. Copula 기반 접근은 다양한 형태의 의존 구조를 포괄적으로 다룰 수 있어, 유전체학, 신경과학, 이미지 분석 등 보조 정보가 풍부한 분야에 널리 적용 가능하다. 또한 두 단계 절차는 실무에서 구현이 비교적 간단하면서도, 검정력 향상과 FDR 제어라는 두 마리 토끼를 잡을 수 있는 실용적인 도구를 제공한다. 향후 연구에서는 고차원 보조 변수 집합을 동시에 다루는 확장 모델과, 베이지안 프레임워크와의 연계 가능성도 탐색될 전망이다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기