빼기로 생각하기 신뢰도 기반 대비 디코딩
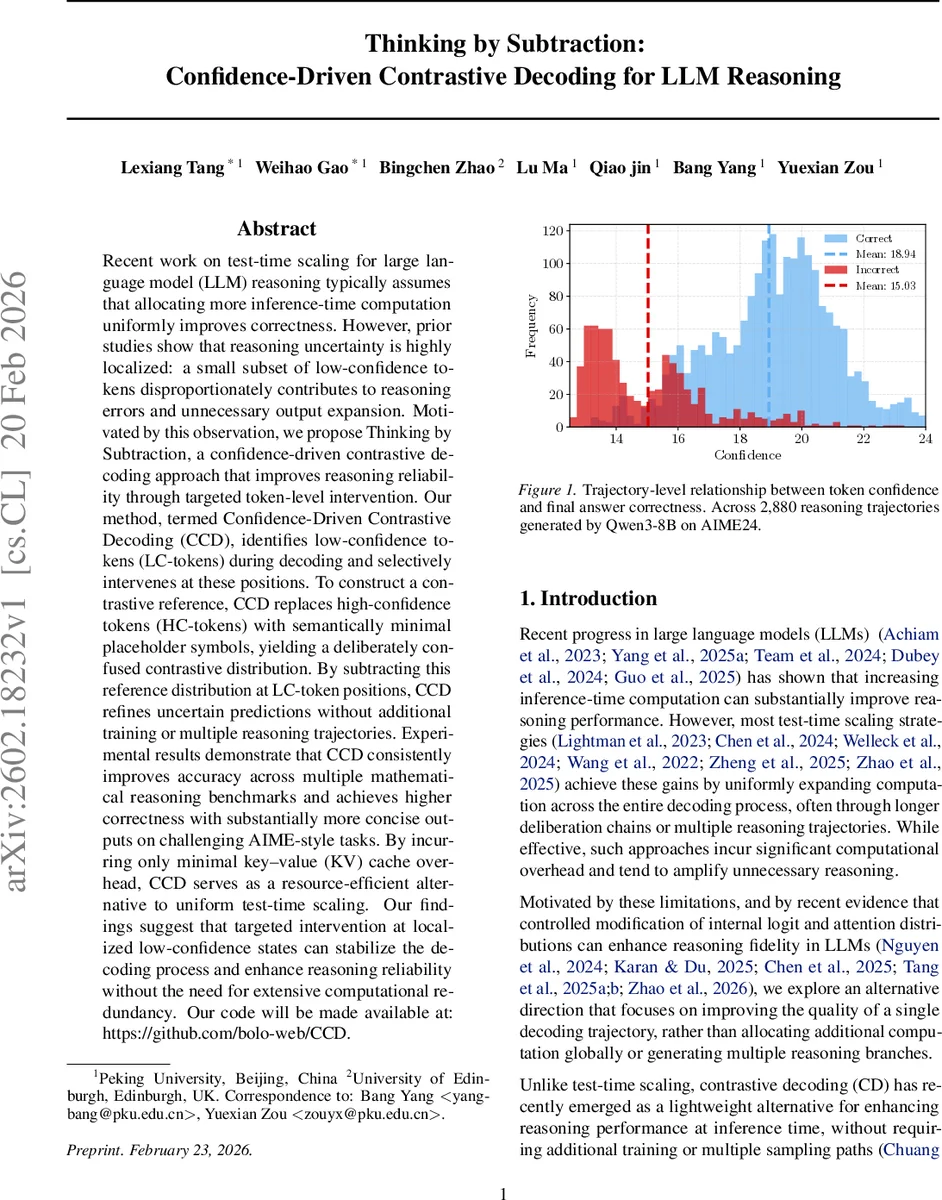
초록
본 논문은 토큰 수준의 신뢰도를 이용해 낮은 확신을 보이는 토큰에만 대비 디코딩을 적용하는 “Confidence‑Driven Contrastive Decoding (CCD)”을 제안한다. 고신뢰 토큰은 자리표시자로 대체해 대비 분포를 의도적으로 혼란스럽게 만든 뒤, 저신뢰 위치에서 메인 로짓과 대비 로짓을 가중합(뺄셈)하여 예측을 정제한다. 실험 결과 CCD는 수학적 추론 벤치마크에서 정확도를 크게 높이고 출력 길이를 줄이며, KV‑cache 오버헤드도 최소화한다.
상세 분석
CCD는 LLM 추론 과정에서 발생하는 불확실성이 토큰 수준에서 국지적으로 집중된다는 관찰에서 출발한다. 기존의 테스트‑타임 스케일링은 전체 디코딩 단계에 일관된 추가 연산을 부여해 계산 비용을 크게 늘리는 반면, CCD는 “Low‑Confidence Token”(LC‑token)과 “High‑Confidence Token”(HC‑token)을 실시간으로 구분한다. 신뢰도는 상위 k 개의 토큰 확률 로그합으로 정의되며, 슬라이딩 윈도우를 통해 최근 토큰들의 신뢰도 분포를 추적한다.
LC‑token은 현재 신뢰도가 윈도우 내 q_cd 백분위수보다 낮은 경우로 판정되고, 이때만 대비 디코딩이 활성화된다. 대비 디코딩을 위해 HC‑token을 자리표시자(예:
CCD는 최종 로짓을 ℓ_final_t = (1+α)·ℓ_main_t – α·ℓ_cd_t 로 계산한다. 여기서 α는 대비 가중치이며, LC‑token일 때만 적용된다. 이렇게 하면 메인 로짓이 낮은 확신을 보이는 토큰에 대해 대비 로짓이 “빼기” 역할을 하여 토큰 선택을 더 확신 있게 만든다.
구현 측면에서 CCD는 두 개의 KV‑cache(메인과 대비)를 병렬 유지한다. 대비 캐시는 HC‑token을 자리표시자로 교체한 상태만 저장하므로, 추가 연산은 로그잇 단계와 간단한 가중합에 국한된다. 따라서 메모리 사용량은 기존 KV‑cache와 동일하고, 연산량도 제한된 α·|R|·|V| 수준에 머문다(여기서 R은 추론 단계, V는 어휘 크기).
이론적 분석에서는 HC‑token이 어텐션 가중치 a_t,i 를 크게 차지해 z_t 표현에 강한 영향을 미친다는 점을 이용한다. HC‑token을 마스킹하면 ∆e_i 가 큰 편미분 J_t,i 를 통해 z_t 가 크게 변하고, 이는 대비 로짓의 엔트로피 상승으로 이어진다. 엔트로피가 높은 대비 분포와 메인 분포를 차감함으로써 토큰‑레벨 확신이 상승하고, 오류 전파가 억제된다.
실험에서는 Qwen3‑8B, Qwen3‑32B 등 다양한 규모의 모델에 CCD를 적용했으며, AIME24·25, BRUMO, HMMT 등 수학적 추론 벤치마크에서 정확도가 평균 47%p 상승했다. 특히 출력 길이가 2035% 감소해 효율성도 크게 개선되었다. KV‑cache 오버헤드는 1.1배 수준에 불과해 실시간 서비스에 적용 가능함을 보여준다.
전체적으로 CCD는 “신뢰도‑조건부 대비 디코딩”이라는 새로운 패러다임을 제시하며, 전역적인 연산 확대 없이도 LLM 추론의 정확도와 효율성을 동시에 끌어올릴 수 있음을 입증한다.
댓글 및 학술 토론
Loading comments...
의견 남기기