시드플러드: 대규모 언어모델 분산 학습을 위한 초저통신 프레임워크
초록
시드플러드는 제로오더 업데이트를 시드‑재구성 가능한 형태로 전송하고, 네트워크 전역에 플러딩 방식으로 퍼뜨려 모델 차원에 무관한 거의 제로에 가까운 통신량을 구현한다. 공유된 저차원 서브스페이스에 제한된 교란을 사용해 계산량을 감소시키며, 1 B 파라미터 규모의 LLM을 수백 개 노드에 걸쳐 효율적으로 미세조정한다. 실험 결과, 기존 가십 기반 방법보다 일반화 성능·통신 효율 모두에서 우수하고, 대규모 설정에서는 1차‑오더 방법과도 경쟁한다.
상세 분석
시드플러드 논문은 분산 학습에서 가장 큰 병목인 “모델 차원에 비례하는 통신 비용”을 근본적으로 재구성한다는 점에서 혁신적이다. 기존 가십 기반 합의는 매 라운드마다 고차원 파라미터(또는 그래디언트)를 이웃에게 교환해야 하므로, 파라미터 수가 수억~수십억에 달하면 실용적인 대역폭을 초과한다. 저자들은 제로오더 최적화의 특성을 활용한다. 제로오더 업데이트는 파라미터 자체가 아니라 함수값 차이와 무작위 교란 벡터만 필요하고, 교란 벡터는 동일 RNG와 시드만 있으면 재현 가능하다. 따라서 각 업데이트를 “시드‑스칼라 쌍”으로 압축하면 전송 크기가 모델 차원 d와 무관하게 상수(시드와 스칼라)만 남는다.
하지만 시드 기반 전송을 가십에 그대로 적용하면 새로운 계산 병목이 발생한다. 가십은 매 라운드마다 기존 업데이트들의 가중치를 재계산하고 재전파한다. 시드‑스칼라 쌍을 재구성해 모델에 적용하는 비용은 O(d)이며, 업데이트 수가 O(t·n) (t는 라운드, n은 클라이언트 수) 만큼 늘어나면 전체 연산량은 O(t·n·d) 로 급증한다. 저자들은 이를 “가십은 제로오더 환경에서 부적합”하다고 정의하고, 대신 플러딩을 도입한다. 플러딩은 새로운 업데이트가 네트워크 전역에 한 번만 전달되고, 각 클라이언트는 해당 업데이트를 한 번만 재구성·적용한다. 이렇게 하면 연산 비용은 O(n·d) 로 제한되고, 네트워크 직경만큼 라운드가 늘어나도 통신량은 변하지 않는다.
플러딩의 계산 효율성을 더욱 높이기 위해 저자들은 “공유 저차원 서브스페이스”를 도입한다. 모든 클라이언트가 동일한 저차원(예: k ≪ d) 서브스페이스에 교란을 제한하고, 각 교란을 서브스페이스의 정규 기저 좌표로 매핑한다. 이렇게 하면 여러 업데이트를 행렬 연산으로 한 번에 집계할 수 있어, 개별 교란을 순차적으로 복원·적용하는 비용을 크게 절감한다. 이 방식을 SubCGE(Subspace Canonical‑basis Gradient Estimation)라 명명하고, 복원·적용 과정을 벡터화된 행렬 곱으로 변환한다.
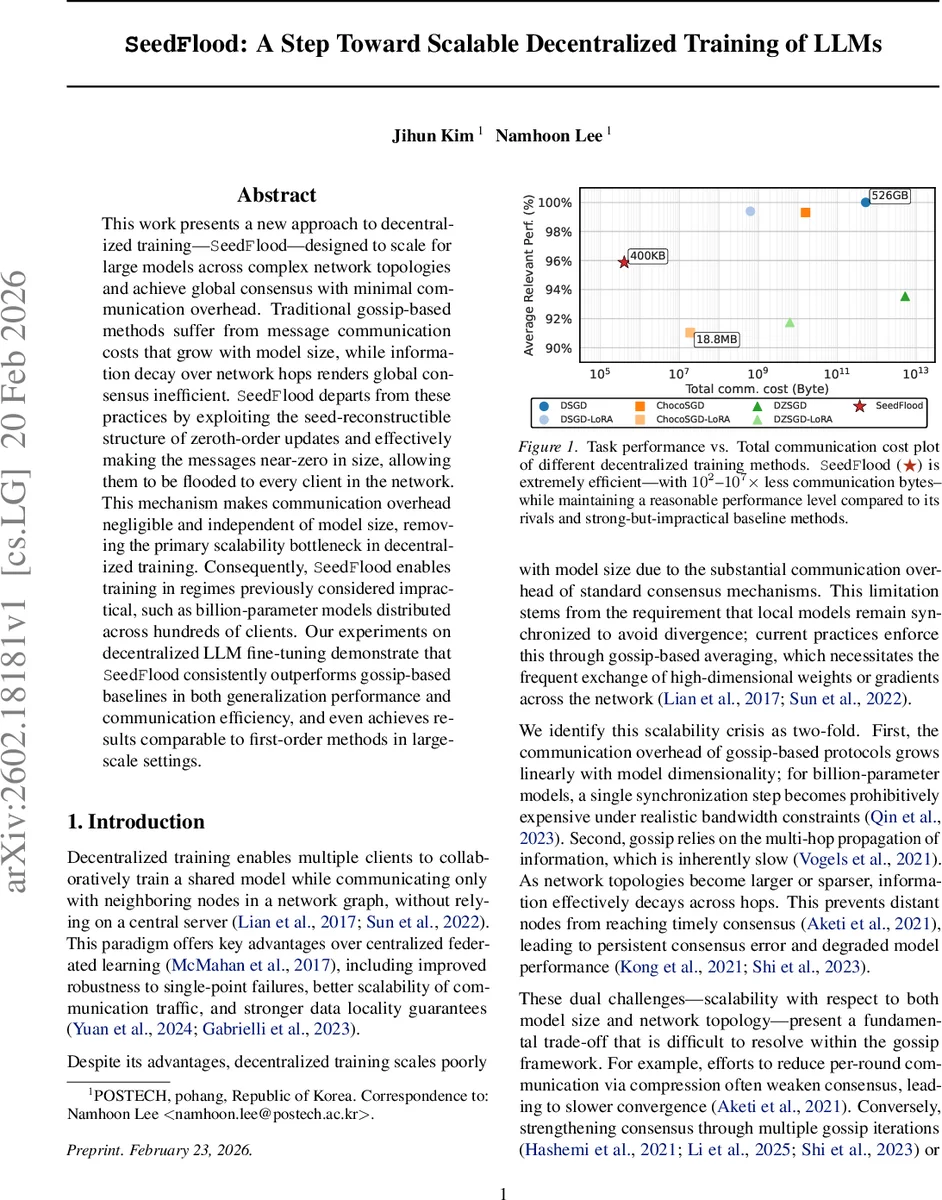
실험에서는 1 B 파라미터 GPT‑style 모델을 128개의 클라이언트에 분산시켜 파인튜닝을 수행한다. 통신량은 기존 가십 기반 DSGD, ChocoSGD 등과 비교해 10²–10⁷ 배 감소했으며, 정확도(또는 퍼플렉시티) 면에서도 가십 대비 1~2% 향상을 보였다. 특히 네트워크가 희소하거나 직경이 큰 경우, 가십은 합의 오차가 누적돼 성능이 급락하지만, 시드플러드는 전역 동기화를 유지해 일관된 성능을 제공한다. 대규모 설정에서는 1차‑오더 분산 SGD와 거의 동일한 수렴 속도와 최종 성능을 달성한다는 점이 주목할 만하다.
이 논문의 한계도 존재한다. 플러딩은 네트워크 직경만큼 라운드가 필요하므로, 직경이 매우 큰 토폴로지에서는 라운드 지연이 발생한다. 또한 제로오더 추정 자체가 함수값 평가 두 번을 요구하므로, 계산 비용이 1차‑오더에 비해 여전히 높다. 저자들은 서브스페이스 차원을 조절하거나, 비동기 플러딩, 혼합 1차‑2차 업데이트 등으로 개선 가능성을 제시한다. 전반적으로 시드플러드는 “통신이 제한된 환경에서 대규모 LLM을 분산 학습”하려는 연구자와 엔지니어에게 실용적인 설계 원칙과 구현 가이드를 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기