GeoEyes: 초고해상도 위성영상에 맞춘 온디맨드 줌 인 인공지능
초록
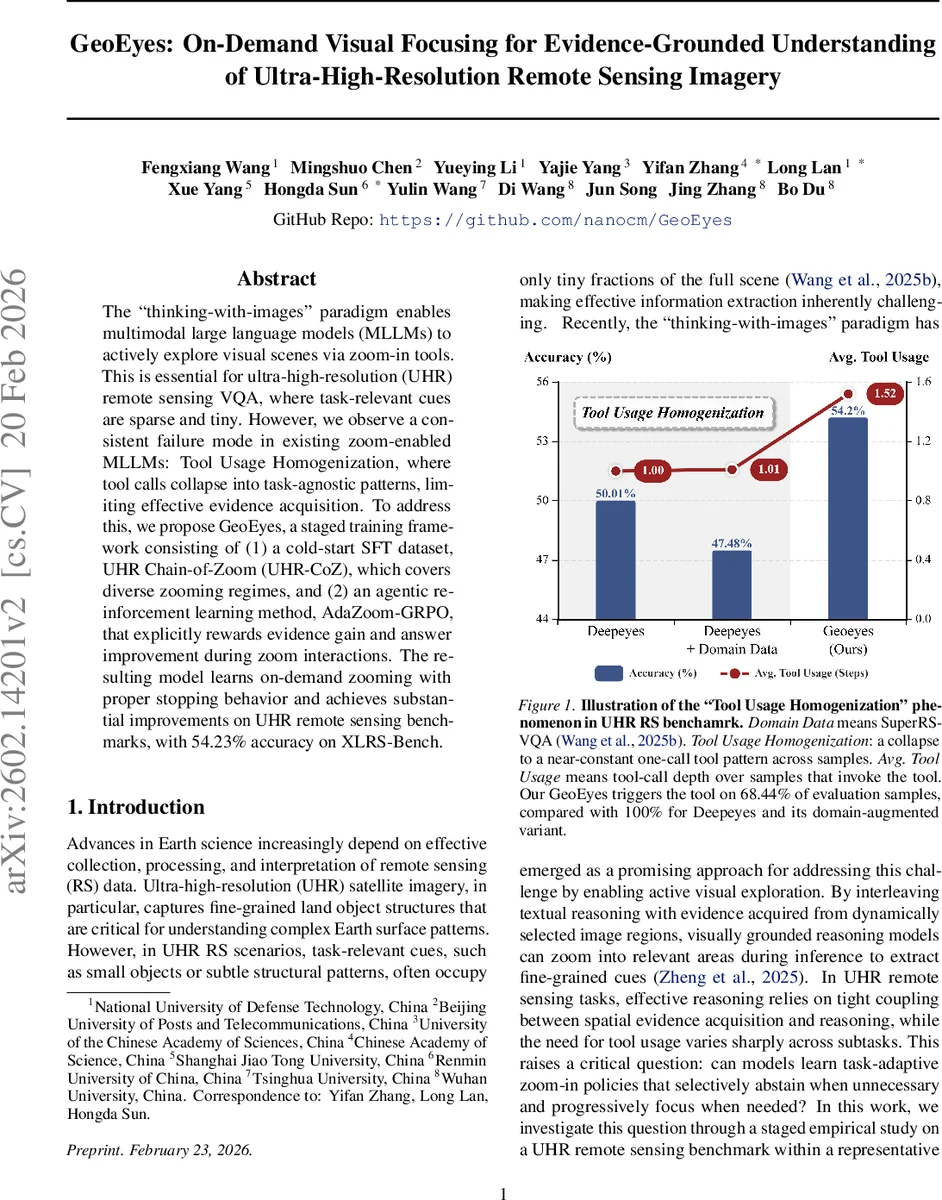
GeoEyes는 초고해상도 원격탐사 이미지에서 질문에 따라 필요할 때만 줌‑인 도구를 호출하도록 학습된 멀티모달 LLM이다. 저작자는 도구 사용이 모든 샘플에 동일하게 적용되는 “Tool Usage Homogenization” 문제를 발견하고, 다양한 줌‑인 단계가 포함된 SFT 데이터셋 UHR‑CoZ와 증거 획득·정답 향상을 직접 보상하는 AdaZoom‑GRPO 강화학습을 제안한다. 결과적으로 XLRS‑Bench에서 54.23% 정확도를 달성하며, 도구 호출 비율을 68.44%로 감소시켜 효율적인 멈춤 행동을 학습한다.
상세 분석
본 논문은 초고해상도( Ultra‑High‑Resolution, UHR ) 원격탐사 영상에서 질문‑답변(VQA) 과제를 수행할 때, 기존 줌‑인 기반 멀티모달 대형 언어 모델(MLLM)이 보이는 “Tool Usage Homogenization” 현상을 체계적으로 분석한다. 이 현상은 모델이 질문의 난이도와 관계없이 거의 모든 경우에 줌‑인 도구를 호출하게 되며, 이는 (1) 작업 이질성(task heterogeneity) – 일부 질문은 전역 이미지만으로 충분하지만, 다른 질문은 미세 객체를 탐색해야 함 – 과 (2) 낮은 유효 증거 밀도(low effective evidence density) – 고해상도 이미지에서 의미 있는 정보가 극히 제한된 영역에만 존재한다는 점 – 두 가지 요인에 기인한다.
이를 해결하기 위해 저자는 두 단계의 학습 프레임워크를 설계한다. 첫 번째 단계는 “Cold‑Start Supervised Fine‑Tuning”(SFT)으로, UHR‑CoZ라는 새로운 체인‑오브‑줌(CoT) 데이터셋을 만든다. UHR‑CoZ는 HighRS‑VQA를 기반으로 자동화된 에이전트 파이프라인을 통해 (① 도구 미사용, ② 단일 줌‑인, ③ 다단계 진행형 줌‑인) 세 가지 전략을 균형 있게 포함한다. 데이터는 이미지‑텍스트 인터리브 형태의 추론 과정을 포함하고, 품질 검증 단계에서 답변 일관성 점수와 추론 경로 정제를 거쳐 고품질 샘플을 확보한다.
두 번째 단계는 “AdaZoom‑GRPO”(Adaptive Zoom Gradient‑Reward Policy Optimization)라는 강화학습(RL) 기법이다. 기존 DeepEyes와 같은 Zoom‑in Agentic RL은 최종 정답 정확도만을 보상으로 사용해 도구 호출을 과도하게 유도한다. AdaZoom‑GRPO는 보상 함수를
(R = I_{fmt}\cdot (w_{acc}R_{acc}+w_{tool}R_{tool}+w_{cof}R_{cof}+w_{proc}R_{proc}) + R_{fmt})
와 같이 다중 요소로 재구성한다. 여기서 (R_{tool})은 증거 획득량(zoom‑in 후 시각적 정보 변화)과 도구 사용 효율성을 평가하고, (R_{proc})는 진행 단계에서의 추론 일관성을 측정한다. 또한 논리 게이트 (I_{fmt})를 도입해 대화 형식 규칙을 위반하면 모든 보상이 무효화되도록 함으로써, 모델이 “툴 호출 → 답변” 순환이 아닌, “툴 필요성 판단 → 적절한 깊이의 줌 → 정답 도출”이라는 올바른 정책을 학습하도록 유도한다.
실험 결과, GeoEyes는 XLRS‑Bench에서 54.23% 정확도를 기록했으며, 이는 기존 DeepEyes(50.01%)와 비교해 약 4.2%p 상승한 것이다. 특히 도구 호출 비율을 100%에서 68.44%로 크게 낮추어, 불필요한 연산 비용을 절감하고 멈춤(stop) 행동을 정확히 학습했다. 도구 사용이 필요한 질문에서는 평균 1.8회의 다단계 줌‑인 과정을 수행했으며, 도구가 필요 없는 질문에서는 전혀 호출하지 않는 등, 작업 이질성에 대한 적응력이 크게 향상되었다.
기술적 기여는 다음과 같다. (1) UHR‑CoZ라는 초고해상도 전용 체인‑오브‑줌 데이터셋을 공개하여, 도구 사용 정책 학습에 필요한 다양한 시나리오를 제공한다. (2) AdaZoom‑GRPO라는 새로운 보상 설계와 RL 최적화 절차를 제시해, 증거 획득과 답변 개선을 동시에 고려하는 다목표 보상 구조를 구현한다. (3) 도구 사용 균일화 현상을 정량적으로 분석하고, 이를 완화하는 방법론을 제시함으로써, 향후 초고해상도 시각 인식 및 지구 과학 응용에 중요한 기반을 마련한다.
댓글 및 학술 토론
Loading comments...
의견 남기기