배치 프롬프트로 과도한 추론 억제, 효율과 정확도 동시 향상
초록
대형 추론 모델(LRM)은 체인‑오브‑쓰(thought) 방식으로 높은 성능을 보이지만, 간단한 질문에도 불필요하게 긴 추론 과정을 생성하는 ‘오버싱킹’ 현상이 있다. 본 연구는 기존에 처리량 향상을 위해 고안된 배치 프롬프트(batch prompting)가 이러한 오버싱킹을 크게 완화한다는 사실을 실증한다. 13개 벤치마크와 두 최신 모델(DeepSeek‑R1, OpenAI‑o1)에서 배치 크기를 1에서 15로 늘릴 경우 평균 추론 토큰이 76 % 감소하면서 정확도는 유지되거나 오히려 상승한다. 저자는 배치가 (1) 공유 컨텍스트 압력, (2) 패턴 유도, (3) 메타인지적 헤징 억제라는 세 가지 메커니즘을 통해 추론 깊이를 자동 조절한다는 가설을 제시한다. 명시적 토큰 제한 프롬프트는 효과가 없으며, 배치 프롬프트가 비용 절감과 신뢰성 향상을 동시에 제공하는 실용적 인퍼런스 기법으로 재조명된다.
상세 분석
본 논문은 대형 추론 모델(LRM)의 핵심 약점인 ‘오버싱킹(overthinking)’을 인퍼런스 단계에서 모델 내부 수정 없이 해결할 수 있는 방법으로 배치 프롬프트(batch prompting)를 제안한다. 기존 연구들은 모델 내부의 활성화 조절이나 조기 종료 학습 등 무거운 접근법을 사용했지만, 클로즈드 API 환경에서는 적용이 어려웠다. 저자는 배치 프롬프트가 단순히 프롬프트 오버헤드를 분산시키는 비용 최적화 기법을 넘어, 모델의 추론 행동 자체를 규제하는 ‘암묵적 정규화(implicit regularizer)’ 역할을 한다는 점을 실험적으로 입증한다.
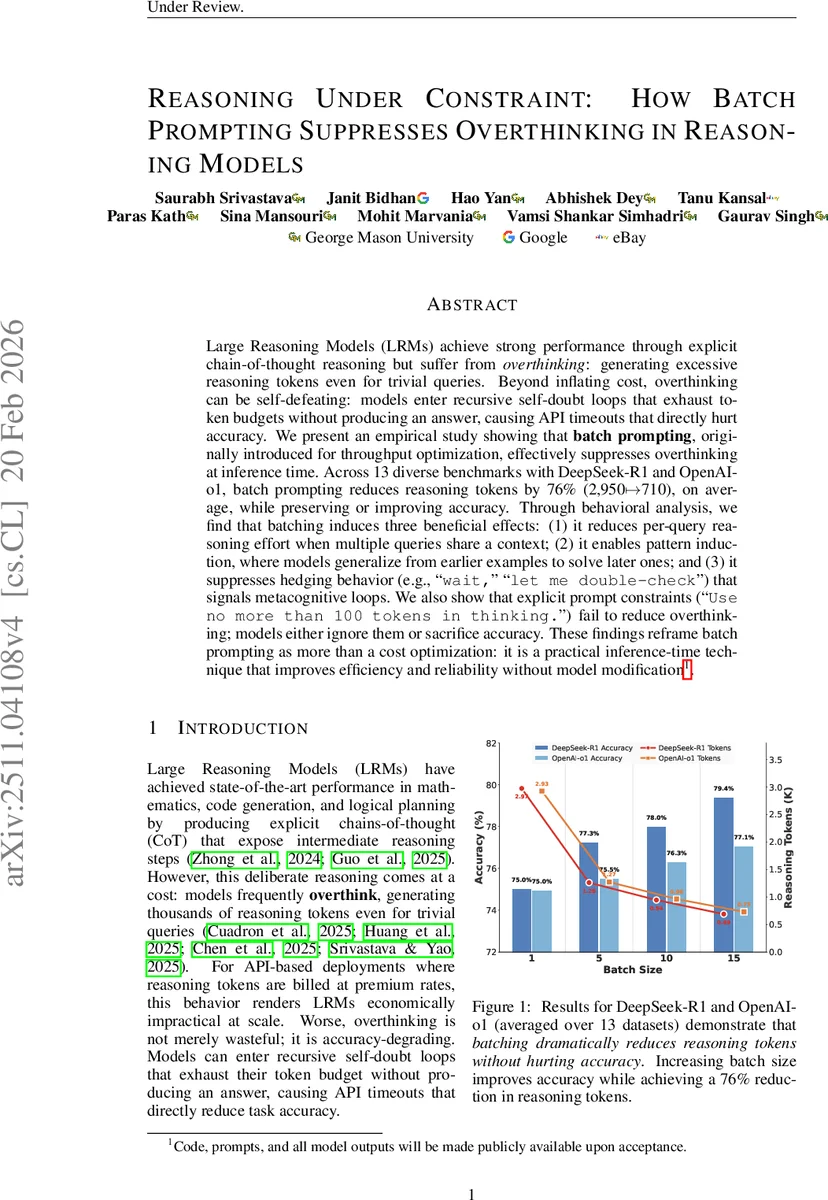
첫 번째 실험에서는 DeepSeek‑R1과 OpenAI‑o1 두 모델에 대해 13개의 서로 다른 데이터셋(수학, QA, 구조화 추출, 과학 등)을 사용해 배치 크기 1, 5, 10, 15를 비교하였다. 결과는 배치 크기가 커질수록 평균 추론 토큰 수가 2,950 → 710 토큰으로 76 % 감소했으며, 정확도는 배치 5에서 1보다 평균 1.2 %p 상승, 배치 15에서는 최대 3 %p까지 향상되는 현상을 보였다. 특히, 배치가 클수록 ‘wait, let me double‑check’와 같은 메타인지적 헤징 표현이 21 → 1로 급감했으며, 이는 모델이 자기 의심 루프에 빠지는 현상을 억제함을 의미한다.
두 번째 분석에서는 배치가 어떻게 추론 깊이를 조절하는지를 세 가지 가설로 정리한다. (1) 공유‑컨텍스트 압력(shared‑context pressure): 동일한 컨텍스트 창에 여러 질문을 넣음으로써 모델이 각 질문당 할당할 수 있는 토큰 양이 제한돼 자연스럽게 간결한 추론을 선택한다. (2) 순차적 앵커링(sequential anchoring): 배치 내에서 모델은 질문을 순차적으로 처리하는데, 앞선 질문이 짧은 추론 스타일을 보이면 뒤따르는 질문도 이를 모방한다. (3) 암묵적 난이도 보정(implicit difficulty calibration): 여러 질문이 동시에 제시되면 모델은 전체 작업량을 고려해 개별 질문에 과도한 연산을 할당하지 않는다. 실험 데이터는 특히 난이도가 높은 질문에 대해서는 여전히 충분한 토큰을 할당하면서, 쉬운 질문은 크게 압축하는 ‘적응형 토큰 할당’ 현상을 보여, 정확도 손실 없이 효율을 높이는 메커니즘을 뒷받침한다.
또한, 명시적인 토큰 제한 프롬프트(“Use no more than 100 tokens in thinking.”)를 적용했을 때 모델이 이를 무시하거나 정확도가 급격히 떨어지는 현상이 관찰되었다. 이는 모델이 프롬프트 내 명령을 그대로 따르기보다 내부 토큰 생성 정책을 우선시한다는 점을 시사한다.
전체적으로, 배치 프롬프트는 (i) 비용 절감, (ii) 오버싱킹 억제, (iii) 정확도 유지·향상이라는 세 축을 동시에 만족시키는 실용적 기법으로 자리매김한다. 특히, 클로즈드 API 환경에서 모델 내부 접근이 불가능한 상황에서도 즉시 적용 가능하다는 점이 큰 강점이다. 향후 연구에서는 배치 내 질문의 이질성(heterogeneous batches)이 오버싱킹 억제 효과에 미치는 영향, 그리고 배치 크기와 토큰 제한 사이의 최적 트레이드오프를 정량화하는 작업이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기