음악 의미를 담은 자연 언어‑오디오 데이터셋 MusicSem
MusicSem은 Reddit에서 수집한 32,493개의 언어‑오디오 쌍으로, 청취자가 일상 대화에서 사용하는 다섯 가지 의미 범주(서술, 분위기, 상황, 메타데이터, 맥락)를 체계화한 데이터셋이다. 기존 데이터셋이 기술적·전문가 중심의 설명에 머물렀던 반면, 본 연구는 인간‑중심적·다양한 의미를 포괄함으로써 멀티모달 음악 표현 학습·평가에 새로운 기준을 제시한다. 데이터 구축 과정, 윤리·법적 고려사항, 그리고 다양한 검색·생성 모델에 대한 …
저자: Rebecca Salganik, Teng Tu, Fei-Yueh Chen
**1. 연구 배경 및 동기**
음악 표현 학습은 음악 정보 검색, 자동 작곡, 개인화 추천 등 다양한 응용 분야의 핵심이다. 최근 멀티모달 학습이 텍스트와 오디오를 연결하는 데 큰 진전을 보였지만, 실제 사용자들이 자연스럽게 사용하는 언어는 기존 데이터셋이 포착하지 못한다는 한계가 있다. 전문가 중심의 캡션은 객관적 음악 특성에 집중하지만, 비전문 청취자는 감정·상황·문화적 맥락을 포함한 복합적인 의미를 담아 표현한다. 이러한 의미 격차는 텍스트‑투‑뮤직, 크로스모달 검색 등에서 모델이 사용자의 의도를 정확히 파악하지 못하게 만든다.
**2. 기존 데이터셋 분석**
표 1에 정리된 바와 같이, 현재 주요 언어‑오디오 데이터셋은 규모가 작거나(수천~수만 쌍) LLM이 자동 생성한 텍스트에 의존한다. 인간이 직접 작성한 데이터는 품질이 높지만, 기술적·전문가 중심의 라벨링으로 의미 다양성이 부족하다. 반면 LLM 기반 데이터는 규모는 크지만, 실제 청취 경험을 반영하지 못하고 텍스트의 허위·왜곡 위험이 존재한다.
**3. MusicSem 구축 과정**
- **데이터 수집**: Reddit의 r/Music, r/ListenToThis 등 음악 관련 서브레딧에서 2020‑2024년 사이의 포스트와 댓글을 크롤링. 저작권이 없는 공개 음원(YouTube‑Audio‑Library, CC‑licensed tracks 등)과 연결된 링크를 추출해 오디오 파일을 확보.
- **전처리 및 필터링**: 중복 제거, 최소 30초 이상 길이, 음질 기준(44.1kHz, 16bit) 충족 여부 확인. 개인 식별 정보(사용자명, URL)와 민감한 내용(혐오 표현 등)을 자동 탐지·삭제.
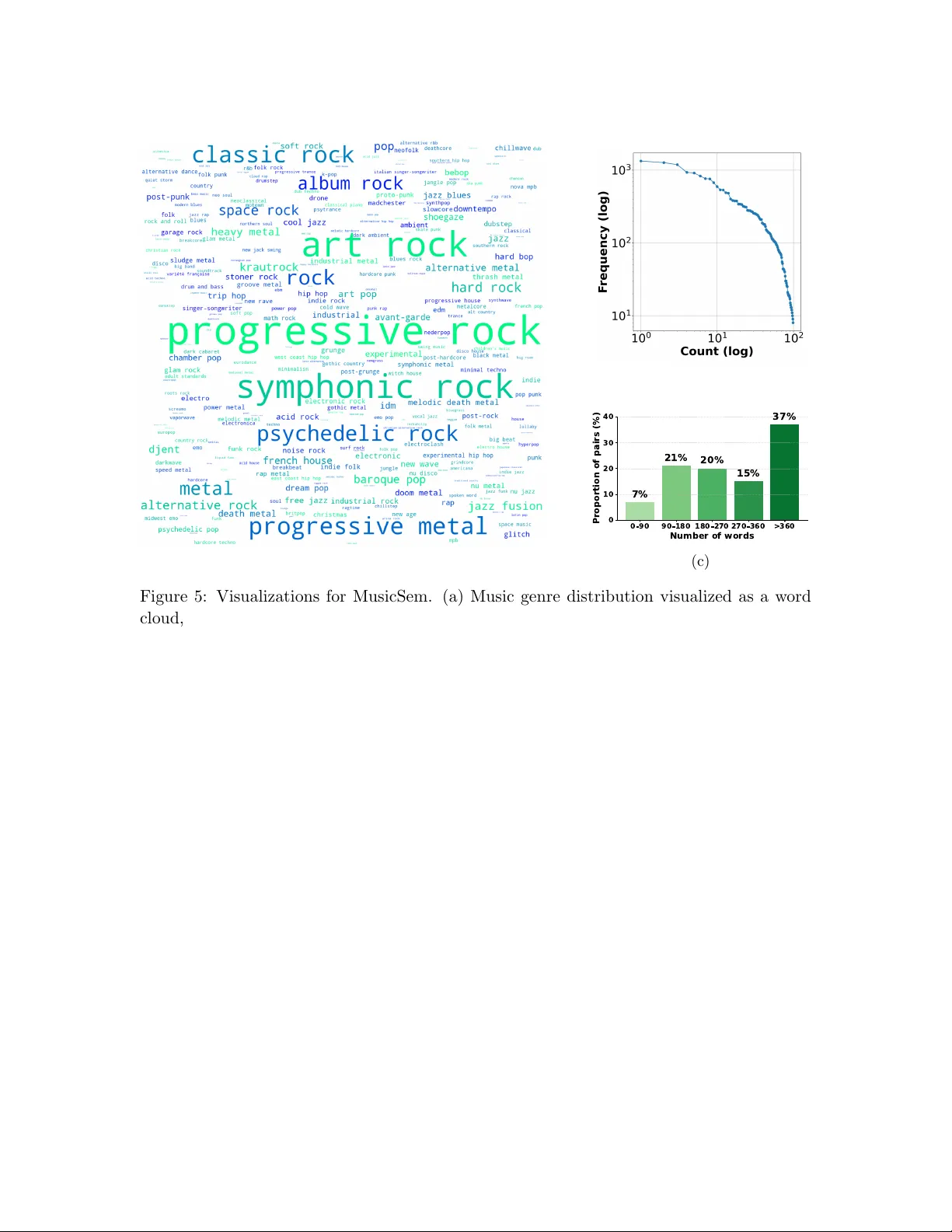
- **라벨링 및 카테고리화**: 두 명의 언어학·음악학 전문가가 5가지 의미 카테고리(서술, 맥락, 상황, 대기, 메타데이터)와 세부 서브라벨을 정의하고, 32,493개의 캡션을 수동 검증·분류. 라벨링 가이드라인과 예시를 부록에 제공.
- **윤리·법적 고려**: Reddit API 이용 약관 준수, 사용자 동의가 암시된 공개 포스트만 사용, 저작권이 명시된 음원만 포함, 데이터셋 배포 시 비식별화된 형태로 제공.
**4. 의미 체계(음악 의미)와 분류**
Table 2에 제시된 다섯 카테고리는 청취 경험을 포괄적으로 설명한다.
- **Descriptive**: “고음 보컬, 피아노 리프, 120BPM” 등 객관적 특성.
- **Contextual**: “이 곡은 Ariana Grande와 비슷한 분위기” 등 비교·연관성.
- **Situational**: “운동할 때 듣기 좋은” 등 사용 상황.
- **Atmospheric**: “우울한 밤에 어울리는” 등 감정·기분.
- **Metadata**: “2013년 발매된 디럭스 에디션” 등 사실적 정보.
이 체계는 기존 연구가 놓친 의미적 층위를 명시적으로 드러내며, 모델이 텍스트와 오디오를 다차원적으로 매핑하도록 설계된 기준이 된다.
**5. 모델 평가**
- **베이스라인**: CLIP‑audio, Audio‑BERT, MusicLM 등 최신 멀티모달 인코더와 텍스트‑투‑뮤직 생성 모델을 선택.
- **검색 실험**: 텍스트 쿼리(각 카테고리별 500개)와 오디오 간 코사인 유사도 기반 검색 수행. 결과는 서술적 쿼리에서 78% Top‑10 정확도, 상황·대기·맥락 쿼리에서는 42% 이하로 크게 차이.
- **생성 실험**: 동일한 서술적 프롬프트에 상황적 변형을 추가한 두 그룹을 생성 모델에 입력. 청취자 설문(100명) 결과, 상황 변형이 반영된 샘플은 평균 만족도 3.2/5, 반영되지 않은 샘플은 2.1/5로 의미적 차이가 명확히 드러남.
- **분석**: 현재 모델은 음향적 특징을 학습하는 데는 강하지만, 텍스트에 내재된 비음향적 의미(감정, 상황, 문화적 맥락)를 추출·반영하는 능력이 부족함을 확인.
**6. 논문의 기여와 향후 연구**
- **데이터 기여**: 규모·다양성·의미 라벨이 결합된 최초의 공개 언어‑오디오 데이터셋 제공.
- **분석 기여**: 기존 모델의 의미 민감도 한계를 실증적으로 제시, 의미 기반 평가 지표 필요성을 강조.
- **연구 로드맵**: (1) 의미 라벨을 활용한 사전학습(멀티태스크), (2) 상황·감정 제어가 가능한 텍스트‑투‑뮤직 모델 설계, (3) 의미 기반 검색·추천 시스템 구축, (4) 다른 문화권·언어에 대한 확장 연구.
**7. 결론**
MusicSem은 청취자가 실제로 사용하는 자연 언어를 기반으로 한 대규모 언어‑오디오 쌍을 제공함으로써, 멀티모달 음악 표현 학습의 데이터 편향을 해소한다. 제안된 의미 체계와 실험 결과는 현재 모델이 의미적 다양성을 충분히 포착하지 못함을 보여주며, 향후 연구가 의미 중심의 학습·평가로 전환될 필요성을 강조한다. 데이터와 코드가 공개되어 있어, 연구 커뮤니티가 즉시 활용하고 확장할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기