Diffusion 언어 모델을 위한 Sink‑Aware 프루닝
초록
Diffusion Language Model(DLM)은 반복적인 디노이징 과정으로 추론 비용이 크다. 기존 프루닝 기법은 autoregressive(AR) 모델에서 발견된 “attention sink” 토큰을 보존하는데 초점을 맞추지만, DLM에서는 sink 위치가 시간에 따라 크게 변동한다. 저자는 sink 변동성을 정량화하고, 변동성이 큰 불안정 sink를 자동으로 식별·제거하는 Sink‑Aware Pruning을 제안한다. 재학습 없이 기존 프루닝 방법보다 품질‑효율성 트레이드오프가 개선되었으며, 코드가 공개되었다.
상세 분석
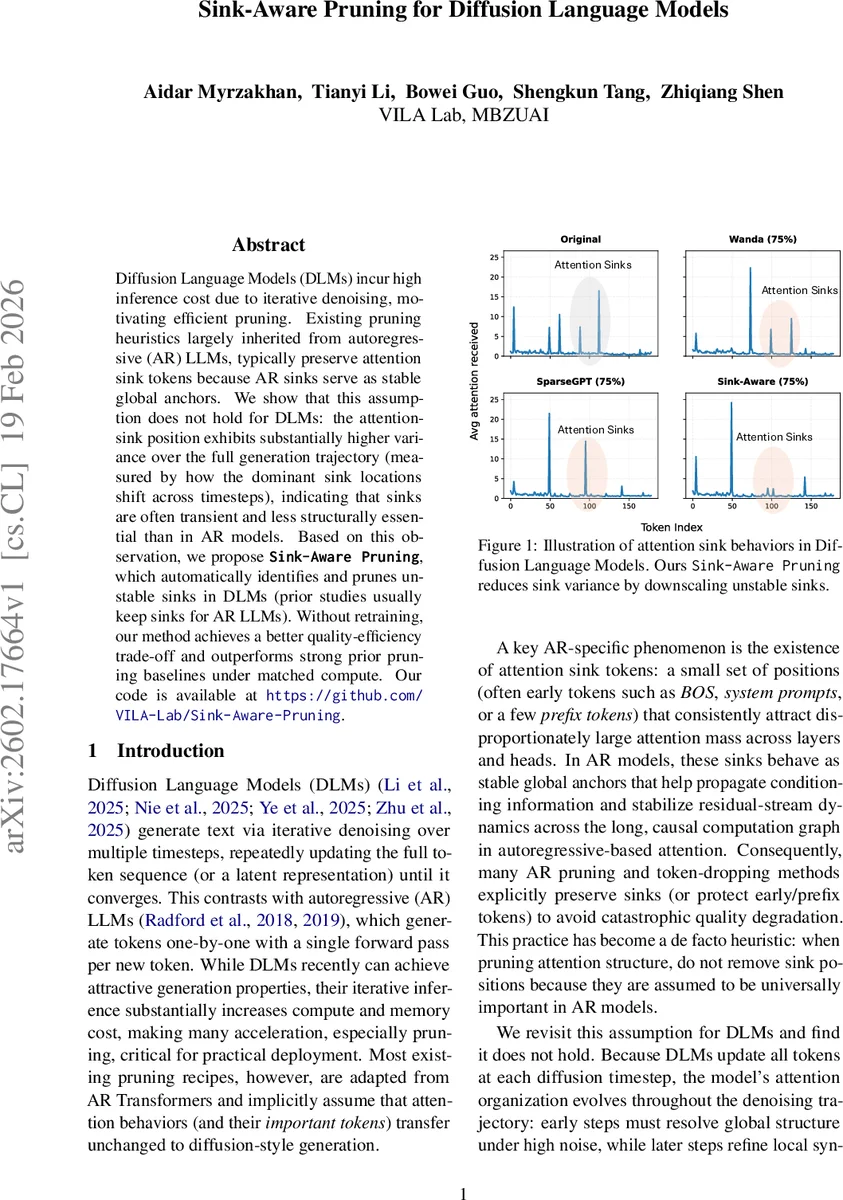
본 논문은 Diffusion Language Model(DLM)의 고유한 어텐션 동역학을 면밀히 분석하고, 이를 기반으로 효율적인 프루닝 전략을 설계한다. 먼저 AR 모델에서 관찰되는 “attention sink”—즉, 초기 토큰이나 BOS와 같이 여러 레이어·헤드에서 과도한 어텐션을 받는 소수 토큰—가 DLM에서는 시간에 따라 위치가 크게 변한다는 사실을 실험적으로 입증한다. 이를 위해 각 디노이징 타임스텝 t에서 토큰 i가 받는 총 어텐션 질량 m_t(i)를 정의하고, 평균 질량 \bar{m}(i)와 시간별 센트로이드 c_t를 이용해 공간적 분산(σ²_spatial)과 시간적 분산(σ²_temporal)을 계산한다. AR 모델은 높은 공간적 분산이지만 시간적 분산이 거의 0에 가까워 sink가 고정된 앵커 역할을 함을 확인한다. 반면 DLM은 공간적 분산이 낮고, 시간적 분산이 수십 배 이상 커서 sink가 전역 구조 형성 단계에서만 일시적으로 등장하고 이후 사라진다. 이러한 “불안정 sink”는 모델이 전역 정보를 빠르게 통합하고, 후속 단계에서 국부적인 정교화로 전환되는 과정에서 자연스럽게 발생한다.
이러한 관찰을 토대로 저자는 Sink‑Aware Pruning을 제안한다. 핵심 아이디어는 (1) 여러 타임스텝에 걸친 어텐션 질량을 집계해 토큰별 sink 스코어 φ_t(j)를 sigmoid 함수로 부드럽게 추정하고, (2) 전체 타임스텝에 평균화해 최종 sink 점수 s_j를 얻은 뒤, 1−s_j를 가중치 ω_j로 사용해 해당 토큰 위치의 활성화를 억제한다. 억제된 활성화 ˜X는 기존 프루닝 메트릭인 Wanda 또는 SparseGPT에 입력되어, 가중치 중요도 점수를 “sink‑aware”하게 재계산한다. 이렇게 하면 불안정 sink에 해당하는 가중치가 낮게 평가되어 더 공격적인 프루닝이 가능해진다.
실험에서는 LLaDA·Dream 등 최신 DLM과 LLaMA‑3·Qwen2.5 등 AR 모델을 동일한 계산 예산 하에 비교한다. DLM에 대해 Sink‑Aware Pruning을 적용하면, 동일한 sparsity(예: 70 %~90 %)에서도 Perplexity와 BLEU 점수가 기존 프루닝 방법보다 현저히 개선된다. 특히 AR 모델에서는 기존 “sink 보존” 규칙이 여전히 유효함을 확인해, 제안 방법이 diffusion‑specific 특성을 정확히 포착함을 입증한다. 코드와 평가 파이프라인을 공개함으로써 재현성을 확보하고, 향후 다양한 diffusion 기반 생성 모델에 적용 가능한 일반화 가능성을 제시한다.
이 논문의 주요 공헌은 (1) DLM에서의 sink 변동성을 정량화하는 새로운 메트릭을 도입, (2) 불안정 sink를 자동으로 식별·제거하는 프루닝 프레임워크를 설계, (3) 재학습 없이도 기존 프루닝 기법 대비 품질‑효율성 트레이드오프를 크게 향상시킨 점이다. 향후 연구는 sink‑aware 기법을 다른 구조적 압축(예: 양자화, 지식 증류)과 결합하거나, diffusion 과정 자체를 동적으로 조절해 더 낮은 연산량으로 고품질 텍스트를 생성하는 방향으로 확장될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기