마진 인식 보상 모델링과 자체 정제 기반 적응형 데이터 증강
초록
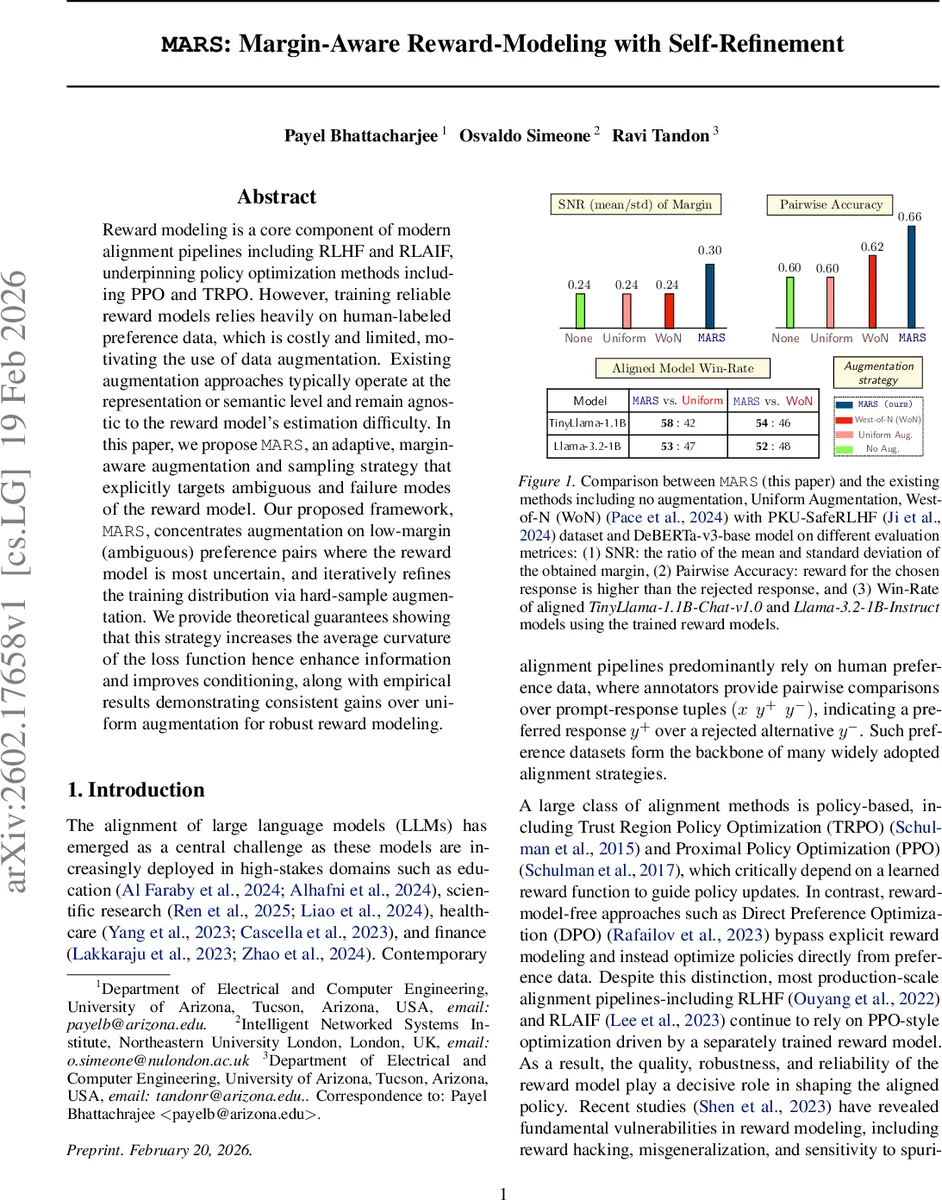
MARS는 보상 모델이 예측하기 어려운 낮은 마진의 선호 쌍에 초점을 맞춰 데이터 증강을 수행하고, 증강된 샘플을 반복적으로 재학습함으로써 손실 함수의 평균 곡률을 높여 학습 안정성을 강화한다. 이론적 분석과 PKU‑SafeRLHF 데이터셋을 이용한 실험을 통해 기존의 균일 증강 및 West‑of‑N(WoN) 방법보다 높은 SNR, 페어와이즈 정확도, 그리고 정렬된 Llama 모델의 승률을 달성한다.
상세 분석
MARS는 기존 보상 모델링에서 “어디가 불확실한가?”라는 질문에 직접 답한다는 점에서 차별화된다. 일반적인 데이터 증강은 무작위 변형이나 의미적 변형을 적용해 데이터 양을 늘리지만, 보상 모델의 학습 난이도와는 무관하게 진행된다. MARS는 먼저 현재 보상 모델이 예측한 마진 (m = r(x,y^+)-r(x,y^-)) 의 절대값이 작은, 즉 |m| 가 낮은 쌍을 저마진(ambiguous) 샘플로 정의한다. 이러한 샘플은 모델이 확신을 갖지 못하는 영역을 직접 드러내며, 손실 함수의 2차 미분(곡률)이 작아 최적화가 느려지는 경향이 있다.
MARS는 저마진 샘플을 선택적으로 증강한다. 구체적으로는 (1) 마진‑분포를 추정해 μ와 σ를 구하고, SNR = μ/σ 가 낮은 구간을 식별한다; (2) 그 구간에 속한 원본 쌍에 대해 텍스트 변형(패러프레이징, 문장 순서 뒤바꾸기 등)과 의미 보존을 보장하는 레이블‑스무딩을 적용해 새로운 ( (x’, y^{+,\prime}, y^{-,\prime}) ) 를 만든다; (3) 증강된 샘플을 기존 학습 셋에 병합하고, 보상 모델을 재학습한다. 이 과정을 “Self‑Refinement”라 부르며, 매 반복마다 저마진 영역이 점차 축소되고 고마진 영역이 확대되는 피드백 루프를 형성한다.
이론적으로 저자들은 증강 전후의 손실 함수 (L(\theta)=\mathbb{E}_{(x,y^+,y^-)}
댓글 및 학술 토론
Loading comments...
의견 남기기