저비용 검증과 고비용 검증의 균형 언제 믿어야 할까
초록
LLM의 추론을 검증하는 두 단계, 저비용(약한) 검증과 고비용(강한) 검증을 공식화하고, 언제 약한 검증만으로 수용하고 언제 강한 검증을 요청할지 결정하는 최적 정책을 제시한다. 최적 정책은 두 임계값 구조를 가지며, 보정과 날카로움이 약한 검증기의 가치를 좌우한다. 또한 스트림에 대한 가정 없이 오류를 제어하는 온라인 알고리즘을 설계한다.
상세 분석
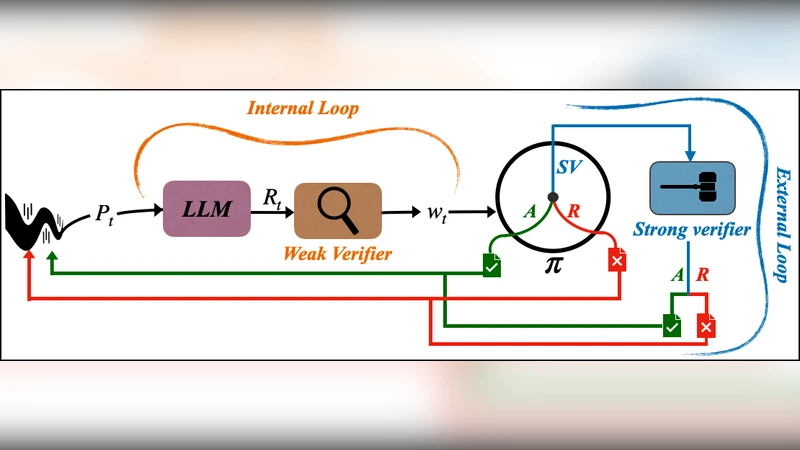
본 논문은 대규모 언어 모델(LLM)의 추론 결과를 신뢰할 수 있게 만드는 검증 루프를 두 축으로 나눈다. 내부에서 빠르게 실행되는 자기일관성, 프록시 보상 등은 ‘약한 검증(weak verification)’이라 정의하고, 사용자가 직접 결과를 검토하거나 인간 피드백을 제공하는 과정을 ‘강한 검증(strong verification)’이라 명명한다. 약한 검증은 비용이 낮고 대규모 적용이 가능하지만 노이즈가 많고 완전한 신뢰를 제공하지 못한다. 반면 강한 검증은 비용이 많이 들고 속도가 느리지만 정확한 신뢰를 보장한다. 이러한 트레이드오프를 정량화하기 위해 논문은 세 가지 메트릭을 도입한다: (1) 잘못 수용(incorrect acceptance) – 약한 검증만으로 허용했지만 실제는 오류인 경우, (2) 잘못 거부(incorrect rejection) – 약한 검증을 통해 거부했지만 강한 검증이면 올바른 경우, (3) 강한 검증 사용 빈도(strong-verification frequency). 정책 π는 약한 검증 점수에 따라 ‘수용’, ‘거부’, 혹은 ‘강한 검증 요청’ 중 하나를 선택한다. 저자들은 전체 인구(population) 수준에서 최적 정책이 두 개의 임계값 τ_low, τ_high 를 이용해 정의되는 구조임을 증명한다. 즉, 점수가 τ_low 이하이면 즉시 거부, τ_high 이상이면 즉시 수용, 그 사이이면 강한 검증을 호출한다. 이 구조는 약한 검증기의 보정(calibration)과 날카로움(sharpness)이 높을수록 τ_low와 τ_high가 서로 멀어져 강한 검증 호출 빈도가 감소함을 의미한다. 마지막으로, 스트림에 대한 사전 분포 가정이나 모델·검증기의 특성 가정 없이, 허용 오류와 거부 오류를 사전에 정한 한계 내에서 유지하도록 하는 온라인 알고리즘을 제시한다. 이 알고리즘은 매 단계마다 현재 약한 검증 점수와 누적 오류 통계를 이용해 임계값을 동적으로 조정한다. 따라서 실시간 서비스 환경에서도 비용 효율적인 검증 전략을 구현할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기