초장기 작업을 위한 LLM 에이전트 KLong
초록
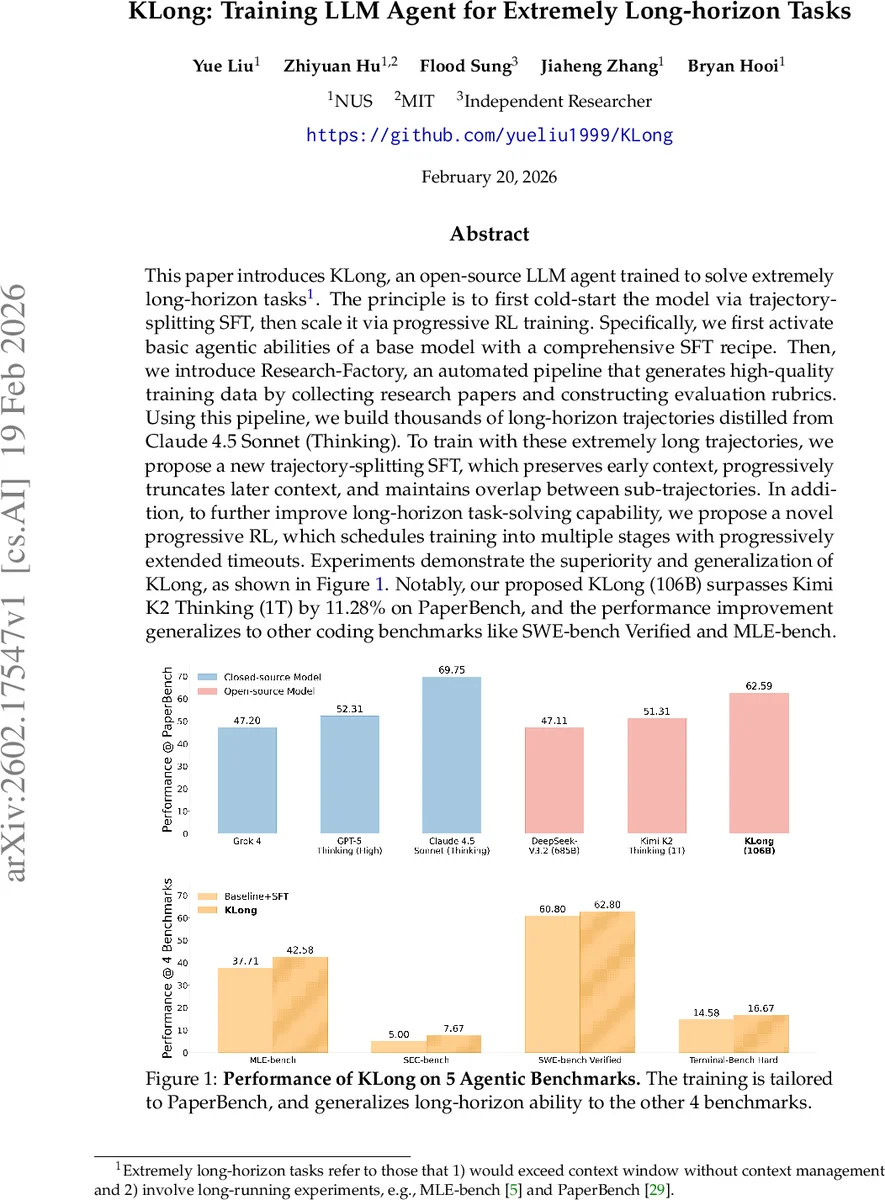
KLong은 초장기(Extremely Long‑horizon) 과제를 해결하도록 설계된 106 B 규모의 오픈소스 LLM 에이전트이다. 논문은 먼저 긴 행동 궤적을 “trajectory‑splitting” 방식으로 나누어 초기에 SFT(지도학습)로 기본 에이전트 능력을 활성화하고, 이후 점진적으로 타임아웃을 늘리는 “progressive RL”을 적용해 성능을 확장한다. 데이터는 Research‑Factory 파이프라인을 통해 연구 논문을 자동 수집·평가 루브릭을 생성해 수천 개의 고품질 궤적을 만든 뒤, Claude 4.5 Sonnet(Thinking)으로부터 증류한다. 실험 결과 KLong(106 B)은 1 T 규모의 Kimi K2 Thinking을 11.28 % 앞서며, SWE‑bench Verified, MLE‑bench 등 다른 코딩 벤치마크에서도 일반화된 향상을 보인다.
상세 분석
본 논문은 LLM 에이전트가 컨텍스트 윈도우를 초과하는 초장기 작업을 수행하기 위한 두 가지 핵심 학습 전략을 제시한다. 첫 번째는 “trajectory‑splitting SFT”이다. 초장기 작업은 수천 단계에 달하는 관찰‑행동 시퀀스로 구성되며, 기존 SFT는 전체 궤적을 한 번에 입력할 수 없어 학습이 불가능했다. 저자들은 궤적을 겹치는 서브‑궤적으로 분할하고, 각 서브‑궤적의 앞부분에 논문 읽기와 같은 초기 컨텍스트를 고정(pinning)한다. 이후 뒤쪽은 점진적으로 잘라내어 모델의 최대 컨텍스트 길이(L_max) 안에 맞춘다. 겹침(overlap) 구간을 두어 서브‑궤적 간 연속성을 유지함으로써, 모델이 장기 의존성을 학습하면서도 메모리 제한을 피한다. 실험에서는 이 방식이 어시스턴트 턴 수를 114.90 → 732.70으로 크게 늘려, 초장기 행동을 효과적으로 모방하게 함을 보여준다.
두 번째는 “progressive RL”이다. 초장기 작업은 타임아웃이 짧으면 대부분의 롤아웃이 중간에 종료돼 보상이 희박하고, 긴 타임아웃을 그대로 적용하면 동기화된 평가 단계에서 병목이 발생한다. 저자들은 단계별로 타임아웃 T^(m)을 점진적으로 증가시키는 스케줄을 도입한다. 각 단계에서는 제한된 시간 내에 수집된 부분 궤적을 trajectory‑splitting 기법으로 다시 나누어, PPO 기반 정책 업데이트를 수행한다. 또한, 부분 롤아웃을 병렬로 진행하고, 평가 큐를 우선순위 기반으로 관리해 평가 단계의 병목을 완화한다. 이러한 설계는 샘플 효율성을 높이고, 정책이 점진적으로 더 긴 시나리오를 다룰 수 있게 만든다.
데이터 측면에서 논문은 “Research‑Factory” 파이프라인을 구축한다. 검색 에이전트가 ICML, NeurIPS, ICLR 등 주요 학회에서 최신 논문 메타데이터를 수집하고, 품질·영향도 기반 필터링 후 PDF를 마크다운으로 변환한다. 평가 에이전트는 논문 내용과 공식 코드 저장소를 분석해 루브릭 트리를 자동 생성한다. 이렇게 만든 루브릭은 논문 재현 과제의 평가 기준으로 사용되며, Claude 4.5 Sonnet(Thinking)으로부터 증류된 수천 개의 초장기 궤적을 검증·필터링한다.
인프라 최적화도 상세히 다룬다. 쿠버네티스 기반 하이브리드 클라우드 샌드박스를 구축해 10 000+ 동시 인스턴스를 지원하고, 25 000+ Docker 이미지와 80 개 이상의 연구용 파이썬 패키지를 사전 설치한다. 롤아웃·학습 파이프라인에서는 부분 롤아웃과 평가 노드의 비동기 처리를 통해 자원 활용률을 극대화한다.
실험 결과는 설득력 있다. PaperBench에서 KLong(106 B)은 62.34 % 점수로 Kimi K2 (1 T)보다 11.28 % 앞서며, 전체 5개 에이전트 벤치마크에서 평균 62.59 %를 기록한다. SWE‑bench Verified와 MLE‑bench에서도 기존 오픈소스 모델 대비 유의미한 개선을 보였다. 이는 초장기 작업에 특화된 학습 전략과 고품질 데이터 파이프라인이 모델 규모에 크게 의존하지 않고도 경쟁력을 확보할 수 있음을 증명한다.
종합적으로, KLong은 초장기 LLM 에이전트 훈련에 필요한 핵심 문제—컨텍스트 제한, 희소 보상, 데이터 스케일링—를 체계적으로 해결한다. trajectory‑splitting SFT와 progressive RL이라는 두 축의 접근법은 서로 보완하며, Research‑Factory는 지속 가능한 데이터 공급원을 제공한다. 앞으로 더 큰 컨텍스트 윈도우와 멀티모달 도구 연계가 결합된다면, 초장기 과제(예: 전체 논문 재현, 복합 실험 파이프라인 자동화)에서 인간 수준의 성능을 달성할 가능성이 높아 보인다.
댓글 및 학술 토론
Loading comments...
의견 남기기