폭력 개념의 인간·AI 판단 비교 연구
초록
본 연구는 22개의 논쟁적 상황을 대상으로 3,000명 이상의 일반인 응답과 18개의 최신 대형 언어 모델(LLM)의 판단을 비교한다. 인간은 전체 응답의 72%를 ‘폭력’으로, 14%를 ‘비폭력’ 및 ‘상황에 따라’로 분류했으며, LLM은 ‘폭력’ 72%, ‘비폭력’ 19%, ‘상황에 따라’ 9%로 응답했다. 특히 온라인 언어 공격과 집단 비난 상황에서 인간과 AI의 판단 차이가 크게 나타났으며, 모델 간 합의도 낮은 편이었다. 결과는 LLM이 인간의 다원적 윤리 인식을 단순화하거나 편향된 방향으로 재현할 위험성을 시사한다.
상세 분석
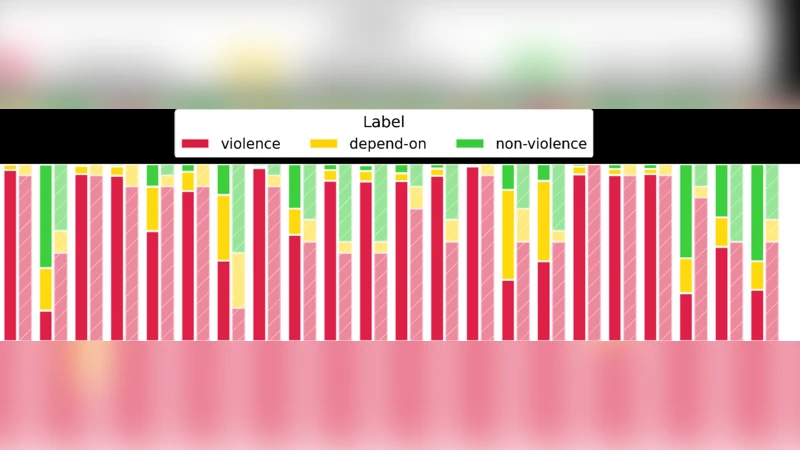
이 논문은 폭력이라는 복합적 개념을 ‘전략적 프록시’로 설정하고, 인간과 인공지능이 동일한 텍스트를 어떻게 분류하는지를 정량적으로 탐색한다. 22개의 문장은 언어적 공격, 상징적 행위, 관계적 동역학, 배제·무관심 등 네 가지 주제 영역으로 균등 배분돼, 폭력 인식의 스펙트럼을 포괄한다. 인간 데이터는 라디오 방송과 SNS를 통한 익명 설문으로 수집됐으며, 각 문항에 대해 ‘폭력’, ‘비폭력’, ‘상황에 따라’ 세 선택지만 허용했다. 응답자는 48시간 동안 3,000명 이상이 참여해, 각 문항당 평균 150% 이상의 표본을 확보했다(총 73,335개 판단).
LLM은 18종 모델을 선정했으며, 파라미터 규모(110억10억 이상), 아키텍처(LLaMA, Mistral, Qwen, Phi‑3 등), 학습 전략(RLHF, 프리트레인 등) 및 안전 정렬 레이어 차이를 반영한다. 동일한 프롬프트 템플릿을 사용해 각 모델에 22문장을 입력하고, ‘category’ 필드만 포함된 JSON 형태의 단일 라벨과 신뢰도 점수를 반환하도록 강제했다. 두 모델(phi3:mini, gemma3:4b)은 라벨을 제공하지 않아 분석에서 제외되었다.
통계적으로는 2×3 카이제곱 검정과 FDR 보정으로 인간‑AI 라벨 분포 차이를 검증했으며, 전체적으로 LLM과 인간의 라벨 분포는 χ²(2)=11.35, p=0.0034로 유의한 차이를 보였다. 차이는 주로 ‘상황에 따라’ 라벨이 인간에게서 13.9%였던 반면 LLM에서는 9.4%로 감소하고, 대신 ‘비폭력’ 라벨이 13.8%→18.8%로 상승한 데 기인한다. 문항별로는 22개 중 9개에서 유의한 차이가 발견됐으며, 특히 온라인 개인·공개 비난(문항 10·11·13)에서 LLM은 폭력 비율을 50% 수준으로 크게 낮췄다. 반대로 텔레비전에서 물리적 제거 발언을 차단하는 상황(문항 20)에서는 LLM이 인간보다 폭력 라벨을 81%까지 과대평가했다.
모델 간 합의는 Fleiss’ κ로 측정했으며, 차이가 큰 문항일수록 κ값이 낮아 AI 내부 의견 분산이 크다는 점을 확인했다. 또한, 모델 파라미터 수와 인간 라벨 정확도 사이에는 약한 양의 상관관계가 있었지만, 아키텍처별 차이는 Kruskal‑Wallis 검정에서 유의미하게 나타나, 단순히 규모만으로는 인간 윤리와의 정렬을 설명하기 어렵다는 결론을 도출했다.
연구는 LLM이 인간의 다원적 폭력 인식을 ‘단일화’하거나 ‘안전 필터’에 의해 특정 방향으로 편향될 위험을 강조한다. 특히 언어적 공격과 집단 비난 같은 미묘한 상황에서 AI는 과도하게 비폭력으로 분류하거나, 반대로 차단된 발언을 폭력으로 과대해석한다. 이는 AI가 사회적 규범을 재현·전파하는 과정에서 투명성, 설명가능성, 그리고 인간 다양성 보존이 필수적임을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기