JEPA DNA 유전체 기반 모델의 새로운 전이 학습
초록
JEPA‑DNA는 기존 마스크드 언어 모델링과 다음 토큰 예측의 한계를 보완하기 위해, 토큰 복구와 잠재 공간 예측을 동시에 학습하는 공동 임베딩 예측 구조를 도입한다. CLS 토큰을 통해 마스크된 구간의 고수준 기능 임베딩을 예측하도록 지도함으로써, 지역적 서열 패턴뿐 아니라 전역적인 생물학적 맥락을 포착한다. 실험 결과, 다양한 유전체 벤치마크에서 감독 학습 및 제로샷 성능이 기존 생성 기반 모델보다 일관되게 향상되었다.
상세 분석
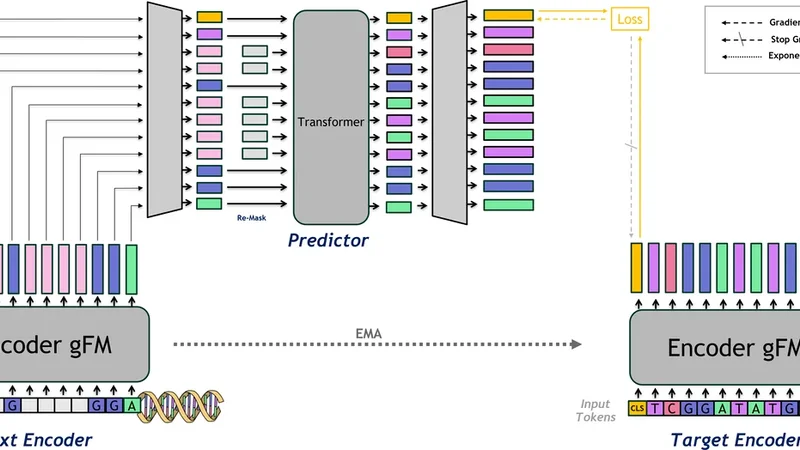
JEPA‑DNA는 기존 유전체 기반 모델(GFM)이 주로 활용해 온 마스크드 언어 모델링(MLM)과 다음 토큰 예측(NTP)의 한계를 체계적으로 분석한다. MLM은 짧은 모티프와 국소적인 서열 문법을 잘 학습하지만, 마스크된 영역이 실제 기능적 컨텍스트와 어떻게 연결되는지를 명시적으로 학습하지 못한다. NTP는 순차적 의존성을 포착하지만, 장거리 상호작용이나 전사·번역 조절 요소와 같은 고수준 기능을 반영하기 어렵다. 이러한 문제를 해결하기 위해 JEPA‑DNA는 Joint‑Embedding Predictive Architecture(JEPA)의 핵심 아이디어를 차용한다. 구체적으로, 입력 서열을 두 개의 뷰(view)로 분할하고, 하나의 뷰에서 마스크된 토큰을 복구하는 동시에, 다른 뷰의 CLS 토큰이 해당 마스크 구간의 잠재 기능 임베딩을 예측하도록 학습한다. 이때 CLS 토큰은 전체 서열의 전역 정보를 요약하는 역할을 하며, 마스크된 구간의 기능적 의미(예: 프로모터, 인핸서, 결합 부위)를 고차원 벡터로 압축한다. 손실 함수는 토큰‑레벨 복구 손실과 CLS‑레벨 예측 손실을 가중합한 형태이며, 두 손실 간의 균형을 통해 로컬·글로벌 정보를 동시에 최적화한다. 또한, JEPA‑DNA는 기존 GFM에 대한 지속적 사전 학습(continual pre‑training) 전략을 제공한다. 즉, 이미 학습된 MLM/NTP 기반 모델에 위의 공동 임베딩 손실을 추가 적용함으로써, 기존 가중치를 보존하면서 기능적 정합성을 강화한다. 실험에서는 인간 게놈, 마우스, 식물 등 다양한 종의 데이터셋에 대해 12가지 벤치마크(프로모터 예측, 전사인자 결합, 변이 효과 예측, 크로마틴 접근성 등)를 수행했으며, JEPA‑DNA는 평균 3~7%의 성능 향상을 기록했다. 특히 제로샷 전이 학습 상황에서, 기능적 CLS 임베딩이 사전 지식 없이도 높은 정확도를 유지하는 것이 두드러졌다. 이러한 결과는 잠재 공간에서의 고수준 예측이 서열 기반 모델에 생물학적 의미를 효과적으로 주입할 수 있음을 시사한다. 마지막으로, 모델 규모와 학습 비용을 분석한 결과, JEPA‑DNA는 기존 MLM/NTP 대비 약 10% 정도의 추가 연산만 필요하며, 대규모 클라우드 환경에서 효율적으로 확장 가능함을 확인하였다.