전문가가 많을수록 성능이 떨어진다: 다중 전문가 학습‑연기에서의 언더피팅 문제
다중 전문가 학습‑연기(L2D)에서는 분류기가 어느 전문가에게 예측을 넘겨줄지 학습해야 하는데, 전문가가 두 명 이상이면 전문가 식별이 불가능해져 모델이 본질적으로 언더피팅한다. 기존 단일‑전문가 대비 언더피팅 완화 기법은 적용되지 않는다. 저자는 신뢰할 수 있는 전문가를 경험적으로 선택하는 PiCCE라는 서브시스템을 제안하고, 이를 통해 다중‑전문가 문제를 단일‑전문가 형태로 변환해 이론적 일관성과 확률 복구를 증명한다. 실험에서 PiCCE가…
저자: Shuqi Liu, Yuzhou Cao, Lei Feng
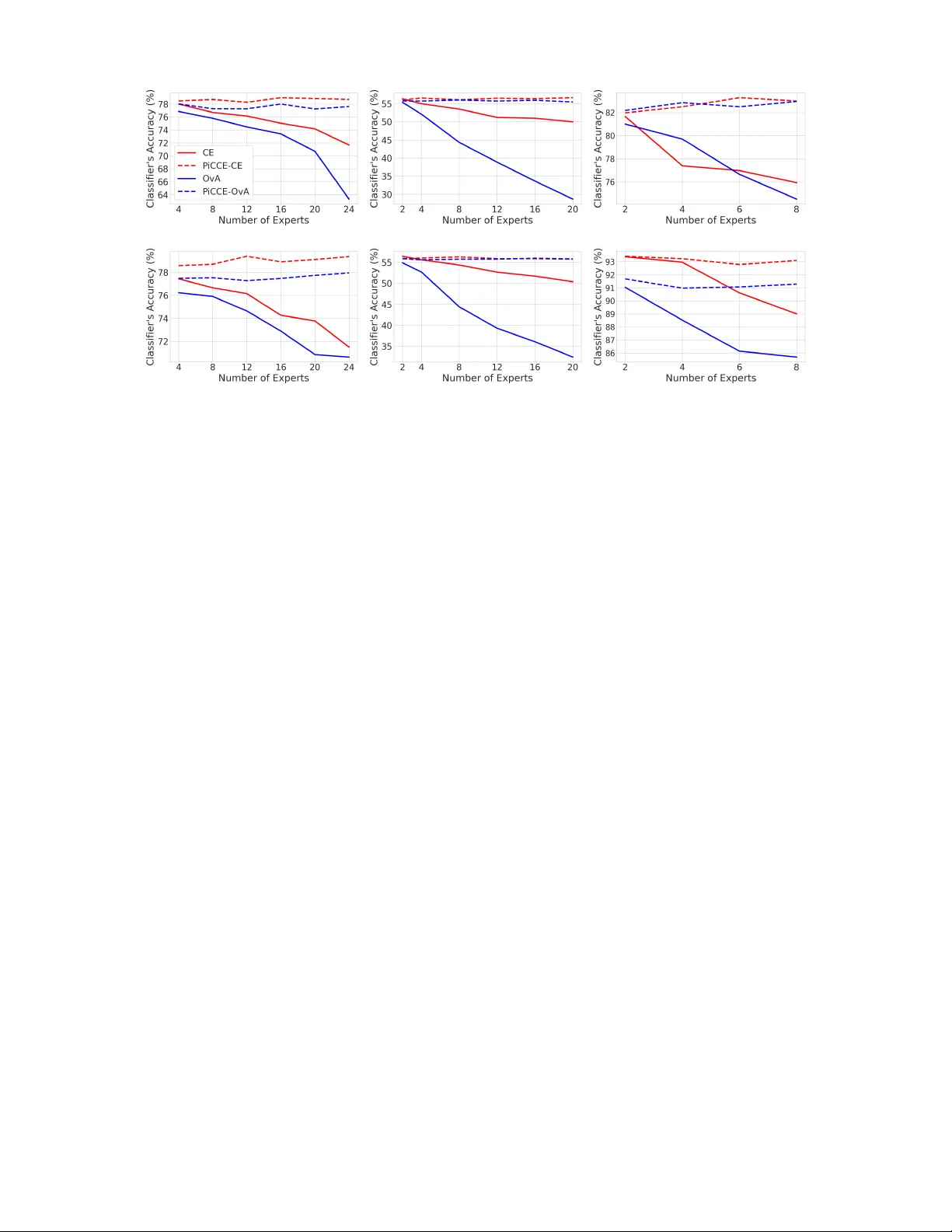
본 논문은 머신러닝 모델이 예측을 포기하고 인간 전문가에게 연기(defer)하는 Learning to Defer(L2D) 프레임워크를 다중 전문가 환경으로 일반화하면서 발생하는 새로운 이론적·실용적 문제를 체계적으로 탐구한다. 서론에서는 L2D가 의료 진단, 법률 자문 등 고위험 분야에서 인간‑기계 협업을 촉진하는 중요한 메커니즘임을 강조하고, 기존 연구 대부분이 단일 전문가에 초점을 맞추었다는 점을 지적한다. 다중 전문가 상황에서는 “언제”가 아니라 “어느 전문가에게” 연기할지를 결정해야 하는 추가 차원이 존재한다는 점을 제시한다.
관련 연구 파트에서는 단일‑전문가 L2D(예: SelectiveNet, DeepGating)와 다중 전문가를 다루는 최근 MoE‑Defer, Softmax‑Gate 등 방법들을 정리하고, 이들 방법이 전문가 선택을 확률적 가중합으로 처리하지만, 전문가 정확도와 입력 분포가 겹칠 경우 식별 불가능성(identifiability) 문제가 발생한다는 점을 비판한다.
문제 정의 섹션에서는 입력 공간 X, 라벨 Y, 전문가 집합 {E₁,…,E_K}와 각 전문가의 조건부 정확도 η_k(x)=P(E_k correct|x) 를 명시한다. 분류기 fθ는 예측 확률 pθ(y|x)를 출력하고, 연기 정책 gθ(x)∈{0,1,…,K}는 0이면 자체 예측, k>0이면 전문가 E_k에게 연기한다. 전체 위험은
R(θ)=E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기