다중 인덱스 병합을 위한 역이웃 슬라이딩 기법과 최적 병합 순서 선택
초록
본 논문은 고차원 벡터 데이터베이스에서 근사 k-최근접이웃(AKNN) 검색을 위한 그래프 인덱스의 효율적인 병합 방법을 제안한다. 역이웃 슬라이딩 병합(RNSM)과 병합 순서 선택(MOS) 기법을 통해 기존 방법 대비 5.48배, 전체 재구축 대비 9.92배의 속도 향상을 달성하면서도 검색 정확도는 유지한다. 1억 개 데이터와 50개의 파티션에서도 안정적인 확장성을 보인다.
상세 분석
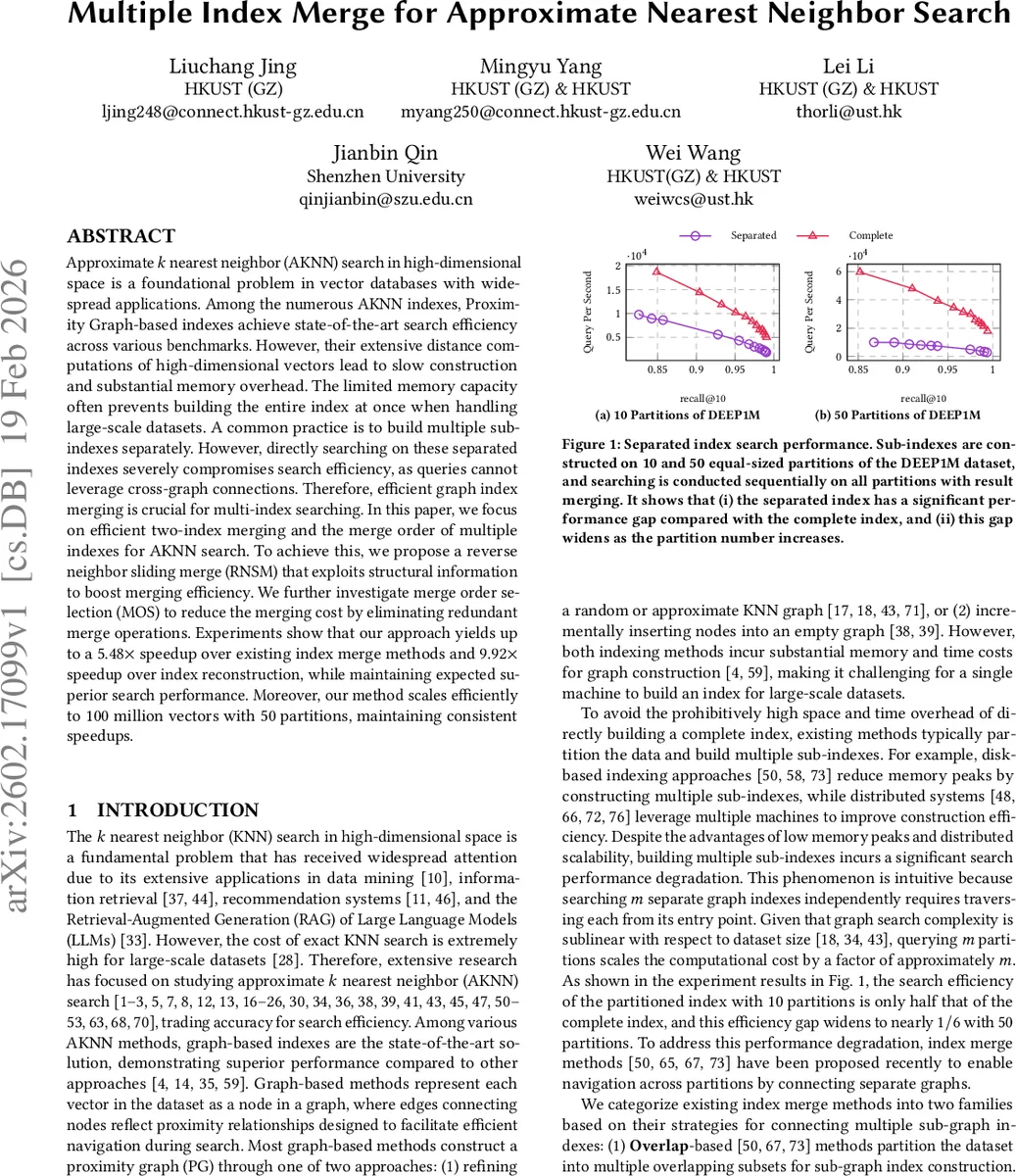
본 연구는 대규모 고차원 데이터셋을 메모리 제한 하에 처리하기 위해 여러 서브 인덱스를 별도로 구축한 뒤, 이를 하나의 통합 그래프 인덱스로 병합하는 문제에 초점을 맞춘다. 기존의 오버랩 기반 방법은 데이터 중복을 통해 교차 연결을 만들지만, 메모리 사용량이 급증하고 파티션 수가 늘어날수록 검색 효율이 급격히 저하된다. 검색 기반 방법은 소스 인덱스의 모든 노드를 타깃 인덱스에 질의해 이웃을 업데이트하는 방식인데, 이는 쿼리 수가 파티션 수에 비례해 증가함에 따라 병합 비용이 선형적으로 늘어나는 단점이 있다.
논문은 이러한 한계를 극복하기 위해 두 가지 핵심 아이디어를 도입한다. 첫 번째인 역이웃 슬라이딩 병합(RNSM)은 “역이웃(Reverse Nearest Neighbor, RNN)” 관계를 활용한다. RNN을 통해 소스 인덱스 내에서 피벗(pivot) 후보를 선정하고, 각 피벗의 이웃 집합을 확장(expand)함으로써 후보 검색 범위를 제한한다. 이후 피벗과 그 이웃 사이에 슬라이딩 윈도우를 적용해 기존 검색 결과를 재사용한다. 이 과정은 피벗 별로 독립적으로 수행될 수 있어 다중 코어 환경에서 높은 병렬성을 확보한다.
두 번째인 병합 순서 선택(MOS)은 다중 파티션 간의 병합 순서를 최적화한다. MOS는 (1) 불필요한 병합 연산을 최소화하기 위해 병합 그래프를 희소(sparse)하게 구성하고, (2) 최종 통합 그래프의 직경(diameter)을 제한해 검색 경로 길이를 억제한다는 두 목표를 동시에 고려한다. 파티션이 무작위로 분포된 경우와 클러스터링된 경우에 각각 맞춤형 전략을 제시함으로써, 전체 병합 비용을 크게 절감하면서도 검색 품질을 유지하거나 오히려 향상시킨다.
실험에서는 HNSW, NSG, SSG, τ‑MNG 등 대표적인 근접 그래프 인덱스에 RNSM·MOS를 적용하였다. 10~50개의 파티션으로 나눈 DEEP1M, SIFT1M, GIST1M 등 실제 데이터셋에서 기존 검색 기반 병합 대비 평균 5.48배, 전체 재구축 대비 9.92배의 속도 향상을 기록했다. 특히 파티션 수가 50개, 데이터 규모가 1억 개에 달하는 상황에서도 속도 향상이 2배 이상 유지되었으며, Recall@10이 0.99 이상으로 거의 손실이 없었다. 이러한 결과는 RNSM이 구조적 정보를 효과적으로 활용해 후보 탐색을 크게 축소하고, MOS가 병합 순서에 따른 중복 연산을 최소화함을 입증한다.
요약하면, 본 논문은 그래프 기반 AKNN 인덱스 병합에서 가장 비용이 많이 드는 “이웃 후보 생성” 단계에 구조적 재사용 메커니즘을 도입하고, 병합 순서를 전략적으로 설계함으로써 메모리·시간 효율성을 동시에 개선한다. 이는 대규모 벡터 검색 시스템, 특히 디스크 기반 또는 LSM‑tree형 데이터베이스에서 실시간 검색 성능을 유지하면서도 인덱스 구축 비용을 크게 낮출 수 있는 실용적인 솔루션으로 평가된다.
댓글 및 학술 토론
Loading comments...
의견 남기기