아르시 트리니티 대형 모델 기술 보고서: 스파스 MoE와 혁신적 로드밸런싱
초록
아르시 트리니티 시리즈는 400 B 파라미터(활성 13 B) 대형 모델과 6 B·26 B 파라미터의 소형 모델을 제시한다. 핵심은 인터리브된 로컬·글로벌 어텐션, 게이트 어텐션, 깊이‑스케일 샌드위치 정규화, 시그모이드 라우팅을 결합한 스파스 Mixture‑of‑Experts(MoE) 구조이며, 대형 모델에 새롭게 도입된 Soft‑clamped Momentum Expert Bias Updates(SMEBU) 로드밸런싱과 Muon 옵티마이저를 사용해 17 T 토큰을 무손실 학습한다.
상세 분석
아르시 트리니티 시리즈는 현재 LLM 분야에서 가장 활발히 연구되는 스파스 MoE 접근법을 실용적인 수준으로 끌어올렸다. 먼저 토크나이저 설계는 200 k BPE 사전과 다단계 숫자 분리, 스크립트‑인식, 바이트‑레벨 백업을 결합해 다국어 특히 CJK와 프랑스어에서 압축 효율을 크게 개선하였다. 기존 SuperBPE와 비교해 압축률은 향상됐지만, downstream 성능 향상이 미미하다는 실험 결과는 토크나이저 압축과 모델 성능 사이의 비선형 관계를 다시 생각하게 만든다.
어텐션 설계는 그룹드‑쿼리 어텐션(GQA)과 QK‑노멀라이제이션을 도입해 KV‑캐시 메모리를 절감하고, 로컬‑글로벌 3:1 레이어 패턴에 RoPE와 슬라이딩 윈도우 어텐션을 적용해 긴 컨텍스트에서의 효율성을 확보한다. 특히 글로벌 레이어에 NoPE를 사용함으로써 위치 정보가 과도하게 누적되는 현상을 방지하고, 게이트 어텐션을 통해 어텐션 출력에 시그모이드 게이트를 곱해 과도한 활성화를 억제한다. 이러한 설계는 Muon 옵티마이저와 결합될 때 학습 안정성을 크게 높이며, 기존 AdamW 기반 MoE에서 흔히 관찰되는 loss spike를 최소화한다.
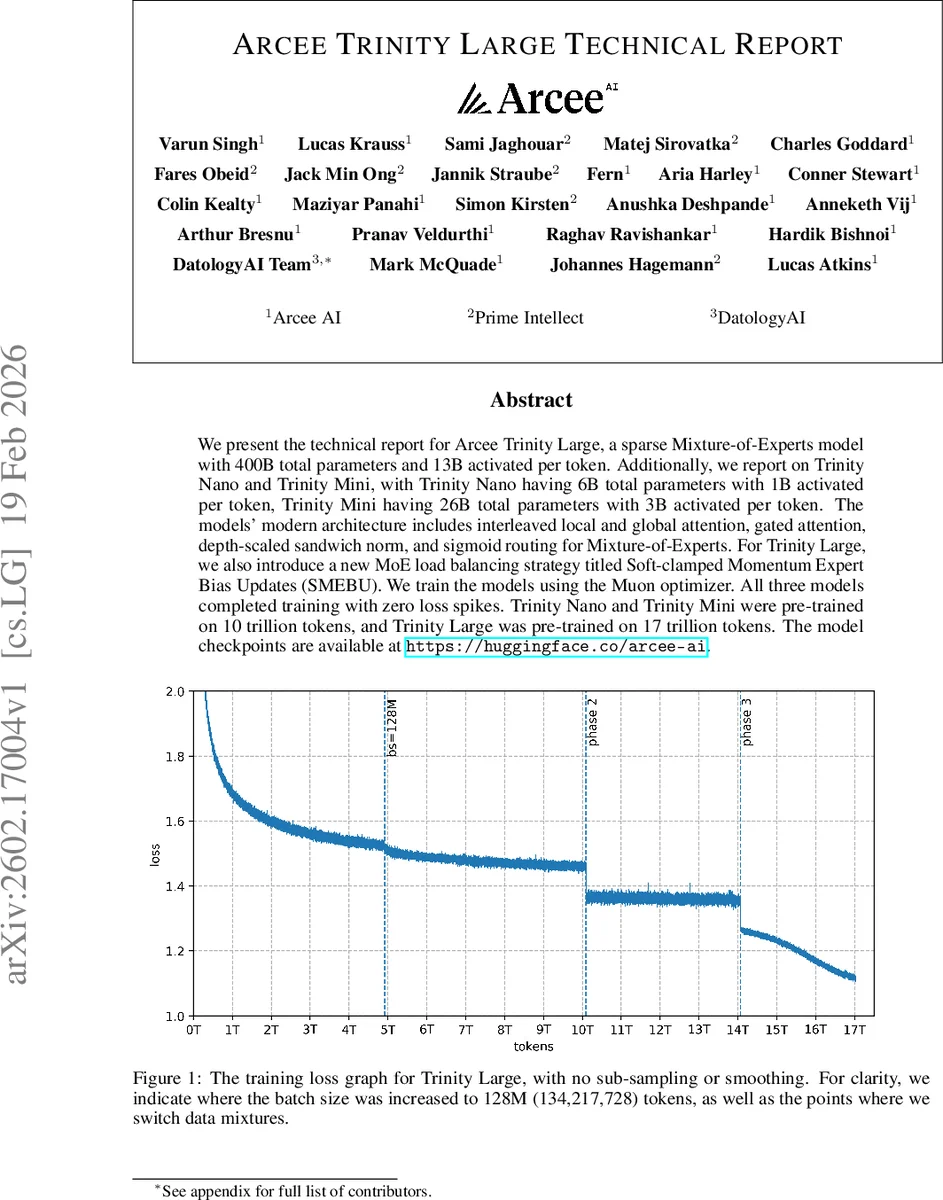
MoE 코어는 DeepSeekMoE를 기반으로 라우팅에 시그모이드 스코어를 사용하고, 라우팅 스코어와 전문가 바이어스를 분리해 Top‑K 전문가를 선택한다. 여기서 가장 눈에 띄는 기여는 Soft‑clamped Momentum Expert Bias Updates(SMEBU)이다. 기존 sign‑기반 바이어스 업데이트는 매 스텝마다 고정된 크기의 변동을 일으켜 전문가 로드가 진동하고, 대규모 MoE에서 라우터 불안정을 초래한다. SMEBU는 로드 편차를 정규화하고 tanh‑클램프를 적용해 변동 폭을 부드럽게 제한하며, 모멘텀 버퍼를 도입해 시간적 평활화를 제공한다. 실험적으로 대형 모델(400 B)에서 라우터 로그잇의 스파이크가 현저히 감소하고, 학습 초반의 불안정성이 크게 완화된 것으로 보고된다.
학습 측면에서는 Muon 옵티마이저가 큰 배치(128 M 토큰)와 높은 학습 효율을 가능하게 한다. Muon은 AdamW 대비 더 큰 임계 배치 사이즈를 허용하면서도 샘플 효율성을 유지한다는 점에서 대규모 토큰(17 T) 학습에 적합하다. 또한 모델은 0 loss spike를 기록했으며, 이는 토크나이저, 어텐션, MoE 라우팅, 옵티마이저가 모두 조화롭게 설계된 결과라 할 수 있다.
한계점으로는 대형 모델의 토크나이저가 CJK 커버리지가 다소 부족하고, 실제 벤치마크 결과가 논문에 상세히 제시되지 않아 성능 비교가 어려운 점이 있다. 또한 SMEBU의 하이퍼파라미터(κ, λ, β 등)가 모델 규모에 따라 어떻게 스케일링되는지에 대한 정량적 분석이 부족하다. 향후 연구에서는 다양한 토큰 길이와 도메인에서의 일반화 성능, 그리고 SMEBU와 기존 aux‑loss 기반 로드밸런싱 간의 정량적 trade‑off를 명확히 할 필요가 있다. 전반적으로 아르시 트리니티는 스파스 MoE와 효율적인 어텐션 설계, 새로운 로드밸런싱 기법을 결합해 대규모 언어 모델의 학습·추론 효율성을 크게 향상시킨 중요한 시도이다.
댓글 및 학술 토론
Loading comments...
의견 남기기