사용자 히스토리 기반 개인화 웹 에이전트 벤치마크 Persona2Web
초록
Persona2Web은 실제 오픈 웹 환경에서 사용자 히스토리를 활용해 모호한 질의를 해석하고 개인화된 행동을 수행하도록 설계된 최초의 벤치마크이다. 사용자 행동 로그를 장기간에 걸쳐 암시적으로 구성하고, 웹 에이전트가 이를 기반으로 웹사이트 선택·상품·서비스를 맞춤 제공하도록 요구한다. 평가 프레임워크는 ‘개인화 점수’, ‘의도 만족도’, ‘성공률’이라는 세 가지 메트릭을 통해 탐색 오류와 개인화 오류를 구분한다. 실험 결과, 현재의 웹 에이전트는 히스토리 접근만으로는 13% 수준의 성공률에 머물며, 개인화 능력 향상이 시급함을 보여준다.
상세 분석
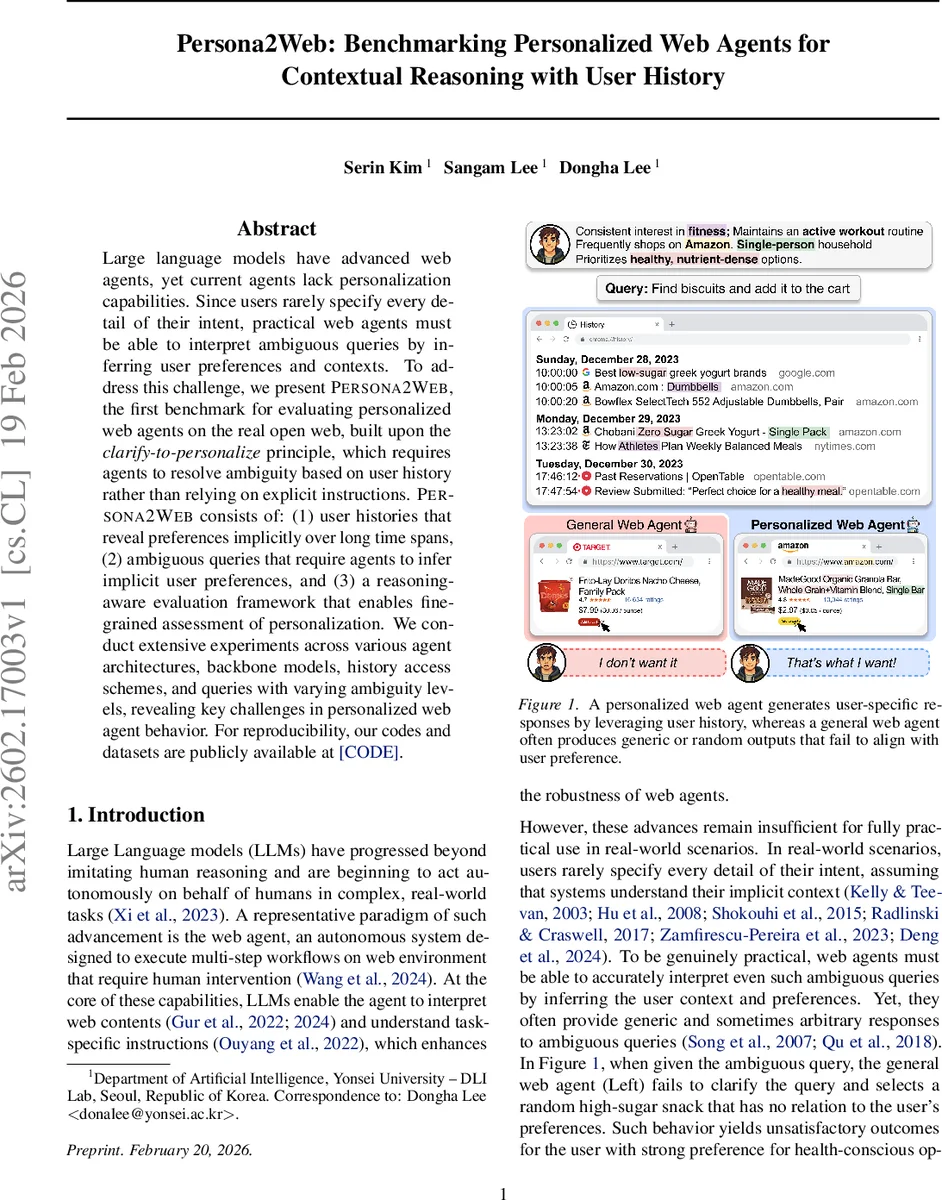
본 논문은 기존 웹 에이전트 벤치마크가 ‘명시적 지시’에만 초점을 맞추고 사용자 맥락을 무시한다는 근본적인 한계를 지적한다. 이를 극복하기 위해 저자들은 ‘clarify‑to‑personalize’ 원칙을 도입했으며, 이는 에이전트가 모호한 질의를 받았을 때 사용자 히스토리를 통해 누락된 정보를 스스로 추론하도록 강제한다. 사용자 히스토리는 단순 클릭 로그를 넘어 연령·성별·거주지와 같은 인구통계와 21개 도메인에 걸친 선호도를 포함한다. 특히, 선호도는 ‘도메인 선택 → 합리적 근거 제공 → 세부 속성 생성’이라는 3단계 LLM 파이프라인을 통해 암시적으로 분산 배치된다. 이렇게 구성된 히스토리는 연간에 걸친 고빈도·저빈도 이벤트 시퀀스로 나뉘어, 에이전트가 시간적 간격이 큰 행동 패턴을 통합해 추론해야 함을 의미한다.
질의 설계는 3단계 모호성 레벨로 구성된다. 레벨 0은 웹사이트와 선호도가 모두 명시된 완전 명확 질의, 레벨 1은 선호도는 명시되지만 웹사이트가 가려진 형태, 레벨 2는 웹사이트와 선호도 모두가 가려진 최종 목표 질의다. 레벨 2에서 에이전트는 히스토리에서 반복적으로 방문한 사이트와 사용자가 선호하는 속성을 식별해, 적절한 사이트를 선택하고 맞춤형 결과를 도출해야 한다.
평가 프레임워크는 ‘개인화 점수(P_web, P_pref)’, ‘의도 만족도(Intent Satisfaction)’, ‘성공률(Success Rate)’ 세 축으로 구성된다. 각 메트릭은 0, 5, 10점의 이산형 루브릭을 적용하며, GPT‑5‑mini를 LLM 심판으로 활용해 에이전트의 전체 행동 트레이스와 추론 로그를 자동 채점한다. 특히, 개인화 점수는 ‘검색·접근 정확도’와 ‘활용 정확도’ 두 하위 루브릭으로 세분화돼, 히스토리 검색 단계와 실제 탐색 단계에서의 오류를 명확히 구분한다.
실험에서는 AgentOccam과 Browser‑Use 2 두 가지 최신 웹 에이전트 아키텍처를 GPT‑4o 기반 백본 모델과 결합해 평가했다. 히스토리 접근 방식(전부 제공 vs. 부분 제공)과 질의 모호성 레벨을 교차 실험한 결과, 히스토리를 전부 제공해도 레벨 2 질의에서 평균 성공률은 13%에 불과했다. 이는 현재 모델이 히스토리에서 의미 있는 선호를 추출하고 이를 탐색 전략에 반영하는 능력이 제한적임을 보여준다. 또한, 동일한 성공률을 보이면서도 개인화 점수와 의도 만족도에서 큰 편차가 나타나, 일부 에이전트는 탐색은 성공하지만 개인화가 미흡하고, 반대로 개인화는 잘하지만 탐색 단계에서 오류가 발생한다는 점을 드러냈다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, 히스토리 자체를 제공하는 것만으로는 충분하지 않으며, LLM이 장기적·분산된 사용자 행동을 효과적으로 요약·인덱싱하는 메커니즘이 필요하다. 둘째, 현재의 평가 방식이 ‘작업 성공’에만 초점을 맞추는 한계가 명확히 드러났으며, ‘개인화 추론 과정’과 ‘탐색 실행 과정’을 별도로 측정할 수 있는 정교한 평가 체계가 필수적이다. 향후 연구는 (1) 기억‑증강 아키텍처와 외부 지식베이스를 결합한 하이브리드 접근, (2) 히스토리 검색을 위한 구조화된 인덱스 및 프롬프트 엔지니어링, (3) 동적 웹 환경에서의 실시간 피드백 루프 등을 통해 개인화 웹 에이전트의 성능을 크게 향상시킬 수 있을 것으로 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기