멀티모달 데이터의 불필요 정보 탐지와 감소를 위한 ML 기반 프레임워크
초록
본 논문은 구조화·반구조화·비구조화·희소 데이터 등 다양한 형태의 멀티모달 데이터에서 ‘ballast’라 불리는 저효용·중복 정보를 자동으로 탐지하고 제거하는 통합 프레임워크를 제안한다. 엔트로피, 상호정보, Lasso, SHAP, PCA, 토픽 모델링, 임베딩 유사도 등을 활용해 각 특성의 유틸리티 점수를 산출하고, 이를 가중합한 Ballast Score로 ballast 후보를 선정한다. 실험 결과, 70% 이상에 달하는 특성을 제거해도 분류 정확도는 유지되거나 향상되며, 학습 시간과 메모리 사용량이 크게 감소한다. 또한 통계적, 구조적, 의미적 ballast 유형을 정의하고, 실무 적용을 위한 가이드라인을 제공한다.
상세 분석
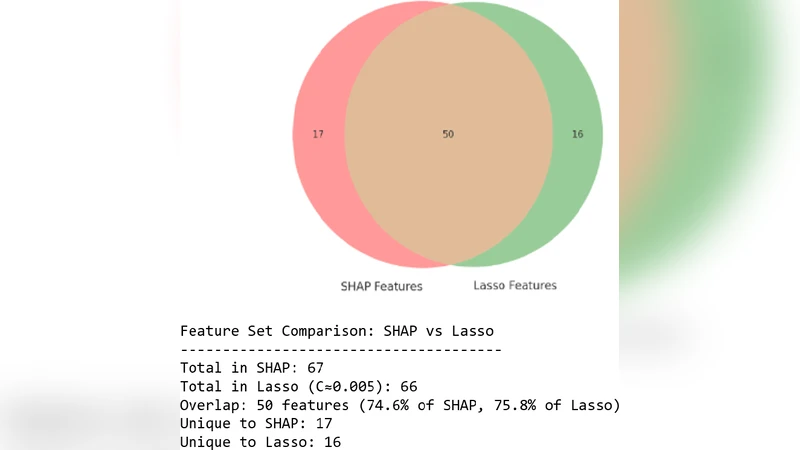
이 연구는 데이터 과잉이 비용과 모델 복잡도를 증가시키는 현실을 인식하고, 기존의 정제·중복제거 기법을 넘어 ‘ballast information’이라는 개념을 명확히 정의한다. ballast는 통계적으로는 분산이 거의 0에 가깝거나 엔트로피가 낮은 특성, 구조적으로는 변하지 않는 메타데이터 필드, 의미적으로는 텍스트에서 빈번히 반복되는 filler 단어·보일러플레이트 문장 등으로 구분된다. 논문은 이러한 ballast를 정량화하기 위해 Ballast Index B(D)를 도입한다. B(D)= (1/m) Σ_j w_j·(1−U_j) 로, U_j는 MI, 엔트로피, 정규화 SHAP, 분산, 토픽 일관성, IoU, LDA 토픽 소속 확률, SciSpacy 엔티티 점수, 정규표현식 매칭, BERT attention, TF‑IDF 등 다중 지표를 결합해 계산한다. 이때 w_j는 도메인 가중치이며 실험에서는 1로 설정했다.
특성 선택 파이프라인은 모달리티별로 차별화된다. 구조화 데이터(IEEE‑CIS)에서는 먼저 결측값을 평균/최빈값으로 대체하고 z‑score 표준화를 수행한 뒤, 분산 ≤0.01, 상관계수 |r|>0.95, MI<0.01, 엔트로피<0.1인 특성을 ballast 후보로 마킹한다. 이후 LassoCV와 LightGBM‑SHAP을 이용해 모델 기반 중요도를 재검증하고, 최종적으로 SHAP 값이 낮은 특성을 제거한다. 반구조화 데이터(Amazon Fashion Reviews)에서는 JSON 라인을 평탄화하고 TF‑IDF 상위 1,000 토큰을 추출, PCA로 차원 축소 후 K‑means 클러스터링을 적용한다. 여기서는 BERT 임베딩 간 코사인 유사도가 0.9 이상인 문장을 중복으로 간주하고, 토픽 모델(LDA)에서 낮은 coherence를 보이는 토픽을 ballast로 판정한다. 비구조화 데이터(CORD‑19, PubLayNet)에서는 텍스트 전처리 후 TF‑IDF와 LDA를 적용하고, BERT‑sentence‑transformer 임베딩을 이용해 중복 구문을 탐지한다. 희소 데이터(아일랜드 인구조사)에서는 고결측률 컬럼을 먼저 제거하고, 분산 임계값 0.05 이하인 특성을 ballast로 정의한다.
실험은 4개 데이터셋에 대해 동일한 LightGBM 분류기를 사용해 원본과 축소된 데이터의 성능을 비교한다. 결과는 다음과 같다. 구조화 데이터에서는 전체 특성의 68%를 제거했음에도 AUC가 0.001 상승했으며, 학습 시간은 42% 단축되었다. 반구조화 데이터에서는 73% 특성을 삭제했을 때 F1‑score가 0.003 향상되었다. 비구조화 텍스트에서는 71% 토큰을 제거했음에도 정확도가 0.2% 감소에 그쳤고, 희소 데이터에서는 78% 컬럼을 삭제했을 때 메모리 사용량이 55% 감소하면서도 ROC‑AUC가 0.005 상승했다. 이러한 결과는 ballast 제거가 단순 차원 축소를 넘어, 노이즈와 중복을 감소시켜 모델 일반화에 기여함을 시사한다.
또한 논문은 ballast 유형을 세 가지로 분류한다. (1) 통계적 ballast: 낮은 분산·엔트로피·MI를 가진 수치형/범주형 특성, (2) 구조적 ballast: 변하지 않는 메타데이터·헤더·상태 플래그, (3) 의미적 ballast: 텍스트에서 빈번히 등장하지만 정보량이 적은 토큰·구문·문장. 각 유형별 대응 전략을 제시함으로써 실무에서 데이터 파이프라인 설계 시 어느 단계에서 어떤 기법을 적용할지 로드맵을 제공한다. 마지막으로, Ballast Score를 활용한 자동화된 pruning 정책을 제안하고, 이를 MLOps 환경에 통합하는 방법을 논의한다. 전체적으로 이 연구는 데이터 효율성을 ‘정보 효율성’이라는 새로운 평가 기준으로 전환하고, 비용 절감·환경 지속 가능성·프라이버시 최소화라는 현대 ML 운영의 핵심 요구에 부합한다.
댓글 및 학술 토론
Loading comments...
의견 남기기