모듈러 덧셈 학습 메커니즘과 동역학
초록
본 논문은 2층 신경망이 모듈러 덧셈 문제를 해결하기 위해 어떻게 개별 주파수의 푸리에 특징을 학습하고, 위상 대칭과 주파수 다양성을 통해 전체적인 논리 함수를 근사하는지를 이론적으로 분석한다. 초기 무작위 가중치에서 복권 티켓 메커니즘이 작동해 특정 뉴런이 지배적인 주파수를 선택하고, 학습 과정에서 경쟁적 ODE 분석을 통해 위상 결합이 어떻게 진행되는지를 보인다. 마지막으로 손실 최소화와 가중치 감쇠 사이의 긴장 관계가 “그로킹(grokking)” 현상을 세 단계(암기 → 일반화‑1 → 일반화‑2)로 설명한다.
상세 분석
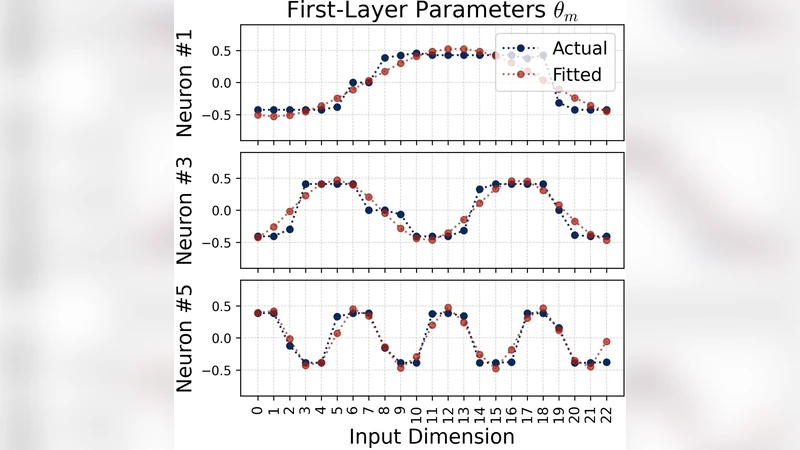
논문은 먼저 2‑layer 완전 연결 네트워크가 입력 (x, y) ∈ ℤₚ²에 대해 출력 ẑ = fθ(x, y) ≈ (x + y) mod p 를 학습하는 과정을 살펴본다. 기존 연구에서 각 뉴런이 단일 주파수의 푸리에 코사인/사인 형태와 특정 위상을 학습한다는 사실을 확장해, 저자는 “다양화 조건(diversification condition)”을 제안한다. 이 조건은 (1) 위상 대칭(phase symmetry): 같은 주파수 쌍을 갖는 뉴런들이 위상이 서로 반대가 되도록 쌍을 이루어 평균을 취하면 잡음이 소거된다. (2) 주파수 다양성(frequency diversification): 전체 네트워크가 p개의 서로 다른 주파수를 고르게 커버하도록 파라미터가 진화한다.
수학적으로 저자는 각 뉴런 i의 출력 hi(t) = a_i cos(ω_i·(x+y)+φ_i) 로 모델링하고, 경사 흐름(gradient flow) 하에서 a_i와 φ_i의 미분 방정식을 ODE 형태로 유도한다. ODE 비교 보조정리(ODE comparison lemma)를 이용해, 초기 스펙트럼 크기 |Â_i(0)| 가 큰 주파수가 “승자”가 되어 다른 주파수를 억제한다는 경쟁 메커니즘을 증명한다. 이 과정에서 위상 φ_i는 초기 무작위 값에 따라 빠르게 0 또는 π 로 수렴하며, 이는 위상 대칭을 자연스럽게 형성한다.
다음으로 저자는 네트워크 전체 출력 ŷ = sign(∑_i hi) 를 고려한다. 개별 hi는 잡음이 섞인 신호이지만, 위상 대칭에 의해 짝을 이룬 뉴런들의 합은 잡음이 상쇄되고, 남은 신호는 정확히 (x + y) mod p 의 지시 함수(indicator)와 일치한다. 이를 “결함이 있는 지시 함수(flawed indicator function)”라 부르며, 완전한 정확도에 도달하기 위해서는 충분한 뉴런 수와 적절한 가중치 감쇠(weight decay)가 필요함을 보인다.
마지막으로 “그로킹” 현상을 세 단계로 해석한다. 초기 단계에서는 모델이 훈련 데이터에 과적합(암기)하여 손실이 급격히 감소하지만 검증 정확도는 낮다. 두 번째 단계에서 가중치 감쇠가 작용해 파라미터가 다양화되고, 위상 대칭이 형성되면서 검증 정확도가 서서히 상승한다(일반화‑1). 세 번째 단계에서는 남은 잡음이 완전히 소거되어 검증 정확도가 훈련 정확도와 일치하게 된다(일반화‑2). 이 과정은 경쟁적 주파수 선택과 위상 결합이 동시에 진행되는 동역학적 시스템으로 설명된다.
요약하면, 논문은 푸리에 기반 특징 학습, 복권 티켓 메커니즘, 그리고 ODE 기반 경쟁 분석을 결합해 모듈러 덧셈 문제의 완전한 메커니즘을 밝히고, 그로킹 현상을 동적 경쟁과 정규화의 상호작용으로 통합적으로 설명한다.
댓글 및 학술 토론
Loading comments...
의견 남기기