레퍼런스 기반 LLM 평가로 비검증 영역 정렬 성능 대폭 향상
초록
본 논문은 레퍼런스 출력을 활용한 프롬프트 설계(RefEval, RefMatch)를 통해 LLM‑as‑Judge의 정확도를 높이고, 이를 이용해 자체 개선(DPO) 과정을 수행한다. 프론트라인 모델이 만든 레퍼런스는 약한 평가자에게, 인간이 만든 고품질 레퍼런스는 강한 평가자에게 각각 큰 이득을 주며, 최종적으로 Llama‑3‑8B‑Instruct와 Qwen2.5‑7B를 AlpacaEval·Arena‑Hard에서 기존 SFT·RLHF 대비 5~20점 이상 향상시킨다.
상세 분석
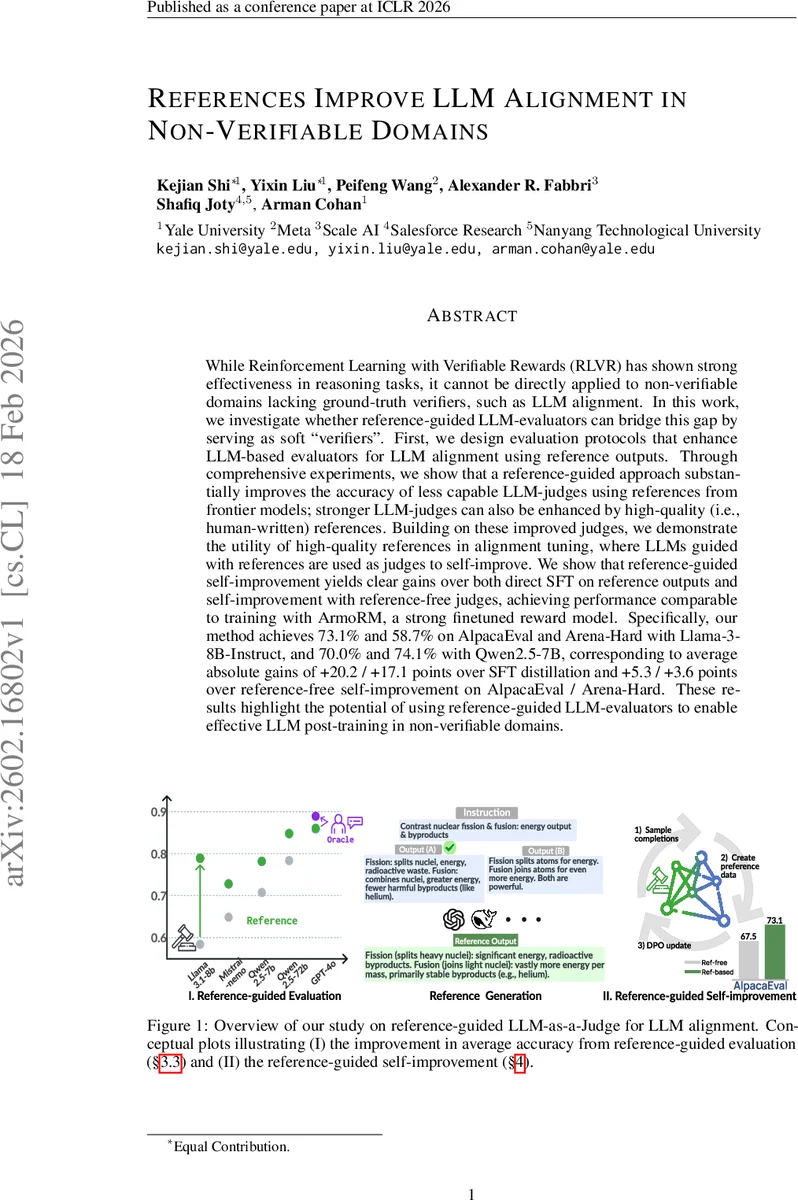
이 연구는 “비검증 도메인”(예: LLM 정렬)에서 기존 RL‑VR이 요구하는 명시적 검증자를 대체할 수 있는 소프트 검증자 역할을 레퍼런스‑가이드 LLM‑judge에 부여한다는 가설에서 출발한다. 핵심은 두 단계의 프롬프트 설계이다. 첫 번째인 RefEval은 레퍼런스 출력을 “정답”이 아니라 “품질 기준”으로 명시적으로 제시하고, 후보 응답이 레퍼런스와 얼마나 일치하는지를 평가하도록 지시한다. 두 번째인 RefMatch는 레퍼런스와의 의미·스타일 일치도를 중심으로 판단하게 함으로써, 단순 사실 일치뿐 아니라 표현적 유사성까지 포착한다. 이러한 설계는 기존 연구가 레퍼런스를 단순히 삽입하는 수준에 머물렀던 점을 넘어, LLM‑judge가 레퍼런스를 활용하는 구체적 전략을 제공한다는 점에서 차별적이다.
실험에서는 11개의 다양한 LLM‑judge(크기·아키텍처 다양)와 5개의 인간‑라벨링 데이터셋을 활용해 평가 정확도를 측정했다. 프론트라인 모델(GPT‑4o)에서 생성한 레퍼런스를 사용했을 때, 평균 정확도가 6.8%p 상승했으며, 특히 작은 모델일수록 개선 폭이 크게 나타났다. 반면 인간이 직접 작성한 고품질 레퍼런스는 대형 모델(GPT‑4o, Claude‑3 등)의 정확도를 추가로 끌어올렸다.
정렬 튜닝 단계에서는 두 단계의 학습 파이프라인을 적용한다. 첫 번째는 레퍼런스 출력에 대한 SFT(지도학습)이며, 이는 기존 DPO 기반 RLHF보다 높은 초기 성능을 제공한다. 두 번째는 앞서 강화된 LLM‑judge를 사용해 DPO를 수행하는 ‘레퍼런스‑가이드 자기‑개선’이다. 이 과정에서 별도의 인간 피드백이나 외부 보상 모델 없이도, 레퍼런스‑가이드 judge가 제공하는 상대적 선호 신호가 충분히 강력함을 입증한다. 결과적으로 Llama‑3‑8B‑Instruct는 AlpacaEval 73.1%, Arena‑Hard 58.7%를, Qwen2.5‑7B는 각각 70.0%와 74.1%를 달성했으며, 이는 동일 파라미터 규모의 ArmoRM‑Llama3‑8B와 거의 동등하거나 더 나은 수준이다.
이 논문의 의의는 세 가지로 요약할 수 있다. 첫째, 레퍼런스를 활용한 프롬프트 설계가 LLM‑judge의 정확도를 체계적으로 향상시킨다. 둘째, 향상된 judge를 이용한 자기‑개선 루프가 별도 보상 모델 없이도 강력한 정렬 성능을 얻는다. 셋째, 비검증 도메인에서도 “레퍼런스‑가이드 보상”이라는 새로운 RL 패러다임(RLRR)을 제시함으로써, 향후 대규모 모델의 자동 정렬 및 지속적 개선에 실용적인 길을 열어준다. 다만, 레퍼런스 품질에 크게 의존한다는 점과, 레퍼런스 생성 비용이 여전히 존재한다는 한계는 향후 연구에서 비용‑효율적인 레퍼런스 생성 및 다중 레퍼런스 집합 활용 방안을 모색해야 함을 시사한다.
댓글 및 학술 토론
Loading comments...
의견 남기기