분포 이동에서 언어 모델의 누락 변수 편향
초록
현대 언어 모델은 훈련 데이터와 다른 분포의 입력에 취약한데, 이는 관측 가능한 요인과 관측 불가능한 요인으로 나뉘는 분포 이동 때문이다. 기존 방법은 관측 가능한 요인만 보정하고, 숨겨진 변수로 인한 편향(omitted variable bias)을 무시한다. 논문은 이 편향을 정량화하고, 최악의 경우 일반화 성능에 대한 상한을 제시하며, 이를 평가·최적화에 활용해 OOD 성능을 향상시킨다.
상세 분석
본 논문은 언어 모델이 직면하는 분포 이동을 “관측 가능(Observable) 요인”과 “관측 불가능(Unobservable) 요인”으로 구분한다. 관측 가능 요인은 데이터 수집 과정, 도메인 레이블, 텍스트 길이 등 명시적으로 측정·통제 가능한 변수이며, 기존의 도메인 적응, 재가중치, 인버스 확률 가중치 등 기법이 주로 이들을 보정한다. 반면 관측 불가능 요인은 데이터 생성 메커니즘에 내재된 숨은 변수(예: 사회문화적 맥락, 저자 의도, 희소한 어휘 사용)로, 학습 단계에서 모델이 직접 접근할 수 없으며, 따라서 전통적인 보정 절차에서는 무시된다.
이러한 숨은 변수는 “누락 변수 편향(omitted variable bias)”을 유발한다. 통계학에서 OVB는 회귀 모델이 중요한 설명 변수를 제외했을 때 추정치가 체계적으로 왜곡되는 현상을 의미한다. 언어 모델의 경우, 손실 함수가 기대 위험을 근사하는데, 목표 위험은 전체(관측 가능+관측 불가능) 변수에 대한 기대값이다. 관측 불가능 변수를 무시하면, 모델이 최소화하는 경험적 위험과 실제 목표 위험 사이에 차이가 발생하고, 이는 OOD 상황에서 급격한 성능 저하로 이어진다.
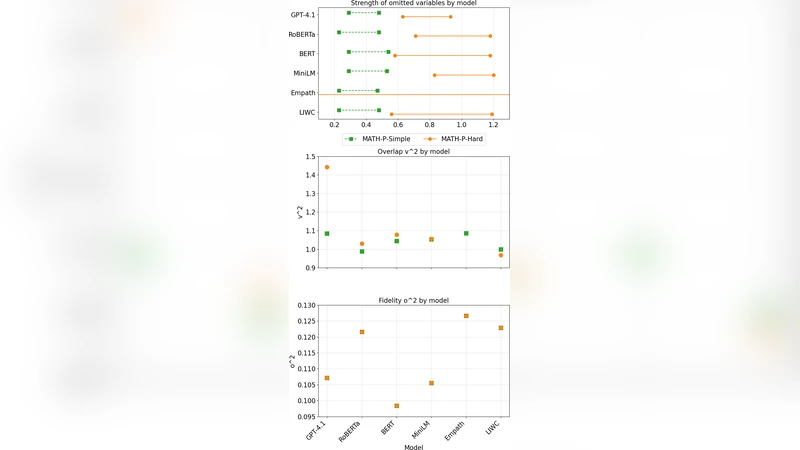
논문은 이 편향을 정량화하기 위해 “누락 변수 강도(omitted variable strength, Ω)”라는 개념을 도입한다. Ω는 관측 불가능 변수와 라벨 사이의 상관관계 및 해당 변수가 입력에 미치는 영향을 결합한 척도로, 베이즈 정리와 정보 이론적 경계를 이용해 상한을 도출한다. 구체적으로, 목표 분포 (P_T)와 소스 분포 (P_S) 사이의 총 변동을 총 변동 거리(TV)와 Kullback‑Leibler 발산(KL)로 분해하고, 관측 불가능 변수에 대한 사전 분포를 가정함으로써 최악의 경우 위험 (R_T^{worst})에 대한 불등식
\
댓글 및 학술 토론
Loading comments...
의견 남기기