연령별 결핵 사망률 지역별 매핑 및 병원 배치 최적화 데이터셋
초록
본 논문은 2014‑2022년 기간 동안 한국 228개 시·군·구를 대상으로 연령별 결핵 사망자를 추정한 고해상도 데이터셋을 구축하고, 연령 가중 사망 최소화를 목표로 병원 배치 최적화 모델을 확장·적용하였다. 연령 구조를 반영한 최적화 결과는 전체 사망자 수는 유사하지만 병원 배치 패턴이 크게 달라짐을 보여, 효율성 vs. 인구구조 타깃팅 간의 정책적 트레이드오프를 제시한다.
상세 분석
이 연구는 한국 보건당국이 제공하는 연령별 결핵 통계가 도(省) 수준에만 공개되는 제약을 극복하기 위해 ‘업스케일링’ 방법을 도입하였다. 구체적으로, 각 도의 연령별 환자·사망 비율(n_i,t, d_i,t)을 구하고, 이를 해당 도에 속한 모든 시·군·구에 동일하게 적용해 구별 연령별 사례(N_s,t)와 사망(D_s,t)을 추정한다. 이 과정은 원시 데이터의 총합을 보존하면서도 개인식별 위험을 증가시키지 않는다는 점에서 개인정보 보호와 데이터 활용 사이의 균형을 잘 맞춘다.
재구성된 데이터는 2014‑2022년 9년간 228개 행정구역, 10년 단위 연령군(40세 이상)으로 구성되며, 연도별 신규 결핵 환자(N)와 사망(D) 추세가 감소하는 동시에 병원(H) 수는 크게 변동하지 않는다. 특히, 70세 이상 연령군에서 사망 비율이 현저히 높아 연령 구조가 사망 위험에 미치는 영향을 정량화할 수 있다.
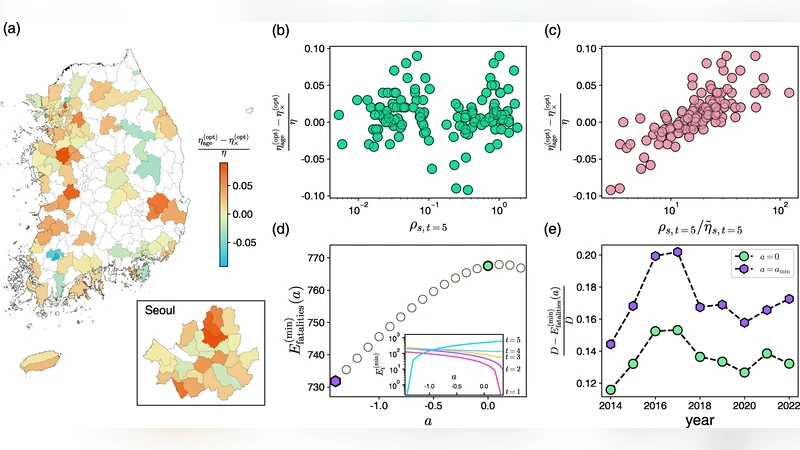
기존 최적화 모델은 병원 밀도 η_s와 사망률 φ_s 사이의 지수 관계 E(η)=∑_s N_s φ_s(η_s)=∑_s N_s exp(−η_s/˜η_s)를 기반으로 하였으며, ˜η_s는 관측된 φ_s와 η_s를 이용해 역산한다. 이 연구는 위 모델에 연령 가중치를 도입해 목표 함수를
min ∑_s ∑_t w_t D_s,t exp(−η_s/˜η_s)
형태로 변형한다. 여기서 w_t는 연령군 t의 사망 위험을 반영하는 가중치이며, w_t=1(연령 무시)와 w_t=φ_t/φ̄(연령 가중) 두 가지 시나리오를 비교하였다.
연령 가중 최적화 결과는 전체 사망자 수 감소량이 연령 무시 모델과 비슷함에도 불구하고, 고령 인구가 집중된 비도시 지역에 병원을 재배치하는 경향을 보였다. 이는 고령층이 상대적으로 병원 접근성이 낮은 지역에 더 큰 사망 위험을 가지고 있음을 시사한다. 반면, 연령 무시 모델은 환자 밀도가 높은 대도시 중심부에 병원을 집중시키는 전통적 효율성 중심 배치를 제시한다.
이러한 차이는 정책 입안자가 ‘총 사망자 수 최소화’와 ‘고위험군(고령) 보호’ 사이에서 선택해야 할 명확한 트레이드오프를 제공한다. 또한, 데이터셋 자체가 연령·공간·시간 차원을 모두 포함하고 있어, 향후 동적 최적화, 시뮬레이션 기반 정책 평가, 그리고 다른 감염병(예: 코로나19)과의 비교 연구에 활용 가능하다.
한계점으로는 연령 비율을 도 수준에서 구 수준으로 동일하게 전이한다는 가정이 있다. 실제 구별 연령 구조 차이가 클 경우 추정 오차가 발생할 수 있다. 또한, 병원 수를 고정하고 재배치만 고려했으며, 병원 규모·전문성·운영 비용 등을 포함한 다중 목표 최적화는 향후 연구 과제로 남는다.
전반적으로, 이 논문은 개인정보 보호와 데이터 활용 사이의 딜레마를 해결하면서, 연령 구조를 명시적으로 반영한 보건 인프라 최적화 프레임워크를 제시한 점에서 학술적·실무적 의의가 크다.
댓글 및 학술 토론
Loading comments...
의견 남기기