대규모 A/B 테스트를 위한 대체 지표 기반 노출 빈도 측정
초록
본 논문은 비용이 많이 드는 라벨링 작업을 실험마다 반복하지 않고도, 인상 로그만으로 콘텐츠 속성의 노출 빈도를 빠르게 추정할 수 있는 “대체 지표 기반(prevalence) 측정” 프레임워크를 제안한다. 오프라인에서 모델 점수를 버킷화하고, 각 버킷의 실제 라벨 비율을 보정한 뒤, 실험군·대조군의 인상 로그에서 버킷 분포를 곱해 추정값을 얻는다. 대규모 A/B 테스트에서 실험별 라벨링 없이도 정확한 노출 빈도와 처리 효과 차이를 측정한다는 점이 핵심이다.
상세 분석
이 연구는 온라인 미디어 플랫폼이 새로운 기능이나 정책을 A/B 테스트할 때, 특정 콘텐츠 속성(예: 부적절성, 클릭 유도성 등)의 노출 빈도를 정확히 파악해야 하는 실무적 필요에서 출발한다. 전통적인 접근법은 무작위 샘플을 추출해 고품질 라벨(전문가 검토 LLM 프롬프트 등)로 태깅하고, 인상 가중치를 적용해 전체 사용자 베이스에 대한 prevalence를 추정하는 것이지만, 라벨링 비용과 시간 지연이 실험 규모가 커질수록 비현실적이다.
논문은 이를 해결하기 위해 “대체 지표(surrogate) 기반 측정”이라는 두 단계 프로세스를 설계한다. 첫 번째 단계는 오프라인에서 라벨링된 샘플을 이용해 모델 점수와 실제 라벨 간의 관계를 학습한다. 구체적으로, 사전 훈련된 예측 모델이 출력하는 연속 점수를 사전에 정의된 버킷(예: 0‑0.1, 0.1‑0.2 … 0.9‑1.0)으로 discretize한다. 각 버킷에 대해 라벨링된 샘플에서 관측된 ‘참된’ prevalence(버킷 내 라벨 양성 비율)를 계산하고, 이를 “보정된 버킷 prevalence”로 저장한다. 이 과정은 라벨링 비용을 한 번만 지불하면 되므로, 라벨링 비용을 실험 수에 비례해 증가시키지 않는다.
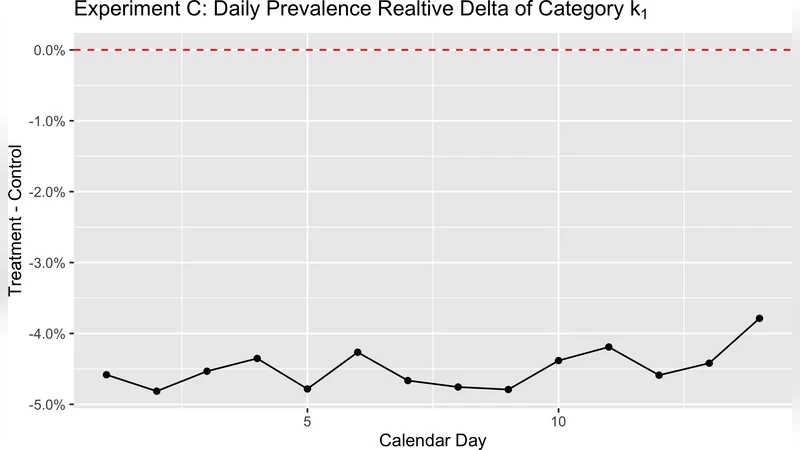
두 번째 단계는 실험 실행 중에 수집되는 인상 로그만을 사용한다. 각 실험 arm와 세그먼트별로 로그에 기록된 모델 점수 분포를 동일한 버킷 기준으로 집계한다. 이렇게 얻은 “버킷 인상 비중”에 앞서 구한 보정된 버킷 prevalence를 가중 평균하면, 해당 arm·세그먼트에 대한 전체 prevalence 추정값을 즉시 산출할 수 있다. 수식적으로는
\
댓글 및 학술 토론
Loading comments...
의견 남기기