디지털 트윈과 확률 시뮬레이션에서 서브모델 불확실성 정량화와 기여도 분석
초록
본 논문은 복합 시스템 시뮬레이션에서 실제 프로세스 대신 추정·학습된 서브모델을 사용할 때 발생하는 인식적(에피스테믹) 불확실성을 ‘서브모델 불확실성’이라 정의하고, 이를 정량화·귀속하는 통계적 프레임워크를 제시한다. 부트스트랩과 베이지안 모델 평균화를 활용해 성능 지표의 신뢰·신뢰구간을 구축하고, 트리 기반 분해 기법으로 각 서브모델이 전체 변동에 미치는 기여도를 중요도 점수 형태로 제공한다. 합성 실험과 콜센터 디지털 트윈 사례를 통해 방법론의 실효성을 검증한다.
상세 분석
이 연구는 복잡계 시뮬레이션이 ‘입력 프로세스·라우팅·제어·최적화·데이터‑드리븐 의사결정 모듈’ 등 다수의 하위 서브시스템으로 구성된다는 점에 주목한다. 실제 시스템에서 이러한 서브시스템을 직접 모델링하기 어려운 경우, 통계적 추정치나 머신러닝 모델을 대체재로 삽입한다. 이러한 대체 과정에서 발생하는 불확실성은 전통적인 입력 불확실성(input uncertainty)과는 달리, 모델 자체의 구조·파라미터 추정에 기인하는 에피스테믹 불확실성이다. 논문은 이를 ‘서브모델 불확실성’이라 명명하고, 두 가지 주요 질문을 제기한다. 첫째, 서브모델 불확실성이 최종 성능 지표(예: 평균 대기시간, 시스템 수용능력)의 추정값에 어떤 정량적 영향을 미치는가? 둘째, 전체 변동성 중 어느 정도가 개별 서브모델에 기인하는가?
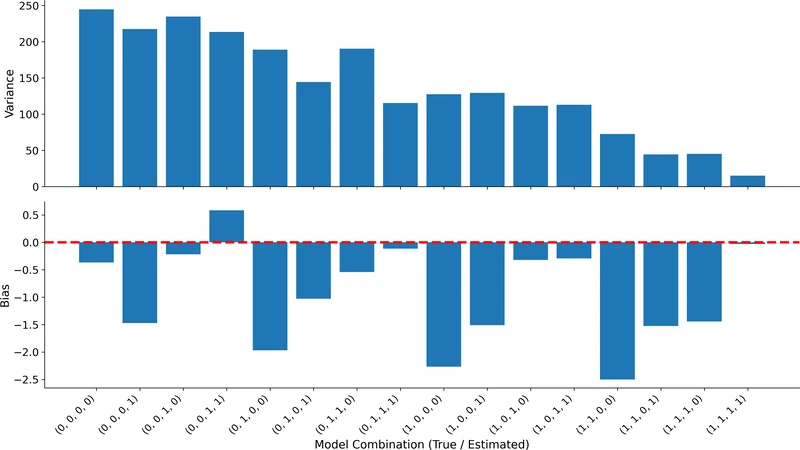
방법론은 크게 세 단계로 구성된다. (1) 부트스트랩 기반의 재표본화 절차를 통해 서브모델 파라미터 혹은 학습된 함수의 변동성을 재현한다. 이때 각 서브모델을 독립적으로 재표본화함으로써 상호 의존성을 보존한다. (2) 베이지안 모델 평균화(BMA)를 도입해 다수의 후보 서브모델(예: 서로 다른 회귀식, 신경망 구조) 사이의 모델 불확실성을 통합한다. BMA는 사후 확률 가중치를 이용해 각 모델의 기여도를 자동으로 조정하므로, 모델 선택 오류를 최소화한다. (3) 전체 출력 변동을 트리 기반 분해(variance decomposition tree)로 전개한다. 이 트리는 루트 노드에 전체 출력 분산을 두고, 각 서브모델을 분기점으로 하여 조건부 분산을 순차적으로 계산한다. 결과적으로 각 서브모델에 할당된 ‘중요도 점수’는 해당 서브모델이 전체 변동에 기여한 비율을 직관적으로 보여준다.
프레임워크는 모델‑에그노스틱(model‑agnostic)하게 설계돼, 파라메트릭(예: 가우시안 프로세스)과 논파라메트릭(예: 커널 밀도 추정) 서브모델 모두 적용 가능하다. 또한 빈도주의와 베이지안 양쪽 패러다임을 동시에 지원함으로써, 실무자는 기존 통계 파이프라인을 크게 변경하지 않고도 서브모델 불확실성을 계량화할 수 있다. 실험에서는 (i) 인공적으로 설계된 5‑서브모델 시스템에서 각 서브모델의 불확실성을 단계별로 삽입·제거하며 프레임워크의 정확성을 검증했고, (ii) 실제 콜센터 디지털 트윈에서 고객 도착 프로세스, 상담원 스케줄링 로직, 대화 내용 기반 예측 모델 등 3개의 핵심 서브모델을 대상으로 적용했다. 결과는 서브모델 불확실성이 전체 성능 추정치의 95 % 신뢰구간을 평균 30 % 확대했으며, 특히 도착 프로세스 모델이 전체 변동의 45 %를 차지한다는 점을 밝혀냈다.
이러한 결과는 서브모델 불확실성을 무시할 경우, 시스템 설계·운영 의사결정이 과도하게 낙관적이거나 보수적으로 치우칠 위험이 있음을 시사한다. 또한 중요도 점수를 활용하면, 모델링 자원이 제한된 상황에서 가장 영향력 큰 서브모델에 우선적으로 고품질 데이터 수집·모델 개선을 투자할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기