분포 격차를 메우는 대규모 언어 모델 적대적 훈련
초록
본 논문은 기존 적대적 훈련이 훈련 데이터셋에 국한돼 실제 언어 분포를 충분히 커버하지 못한다는 문제를 지적한다. 이를 해결하기 위해 확산 기반 LLM을 활용해 유해 응답을 조건으로 다양한 프롬프트를 생성하고, 이 샘플에 연속적 적대적 훈련을 병행하는 “Distributional Adversarial Training (DAT)”을 제안한다. 이 방법은 데이터‑특정 취약점을 포괄적으로 탐색해 기존 방법보다 강인성을 크게 향상시킨다.
상세 분석
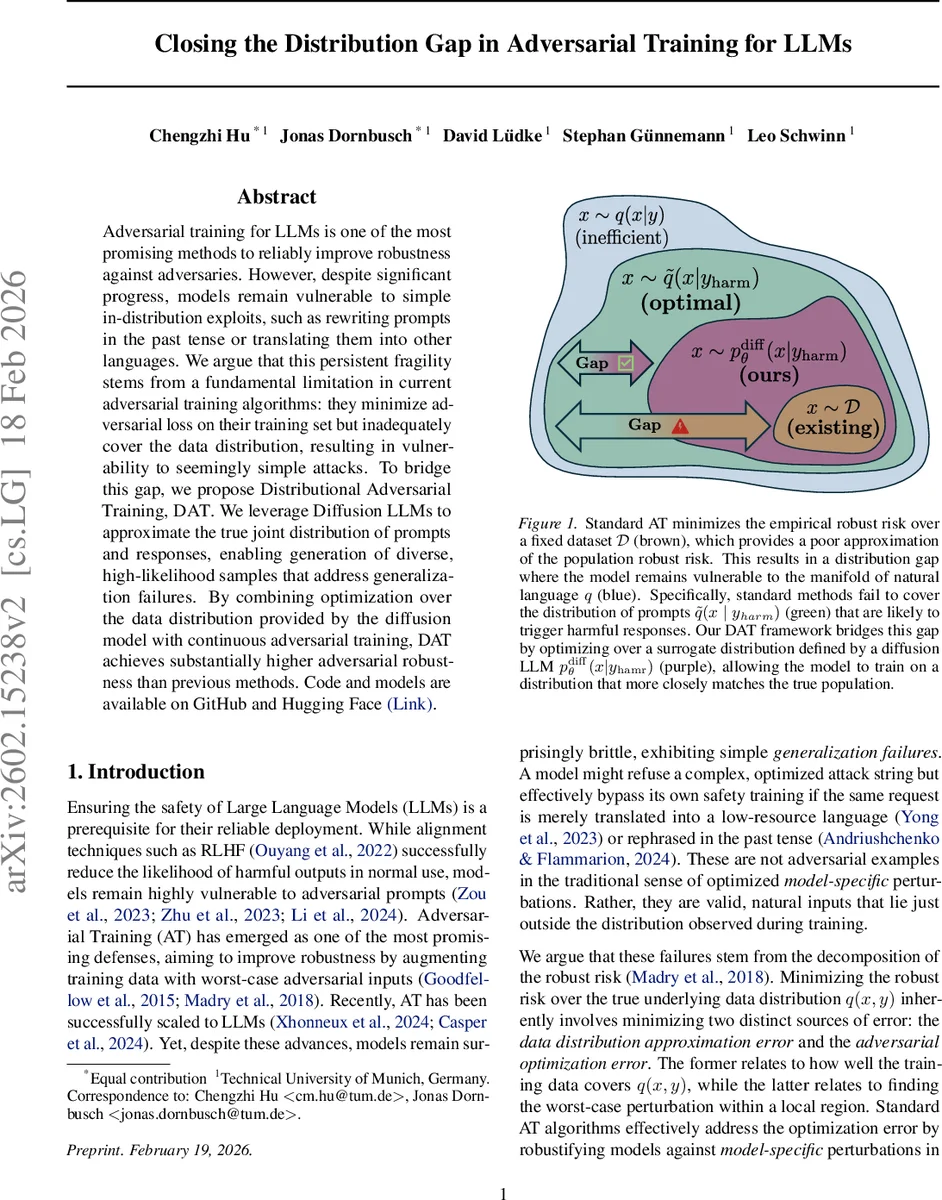
논문은 적대적 훈련(AT)의 두 가지 오류원을 명확히 구분한다. 첫 번째는 데이터 분포 근사 오류로, 제한된 훈련셋 D가 전체 데이터 분포 q(x, y)를 충분히 대표하지 못해 자연어 변형(시제 변경, 번역 등)에서 취약성을 남긴다. 두 번째는 적대적 최적화 오류로, 주어진 입력 주변의 ε-볼 안에서 최악의 손실을 찾는 과정이다. 기존 AT는 주로 두 번째 오류를 줄이는 데 집중했으며, 첫 번째 오류는 무시한다.
이를 보완하기 위해 저자들은 Diffusion LLM을 활용한다. 확산 모델은 조건부 샘플링 p_diffθ(x|y)를 지원해, 유해 응답 y를 고정하고 그에 맞는 다양한 프롬프트 x를 효율적으로 생성한다. 이렇게 얻은 프롬프트는 실제 데이터 분포에서 높은 확률을 갖는 데이터‑특정 샘플이며, 실험에서 모델 간 전이성이 높아 기존 모델‑특정 공격보다 일반화가 뛰어나다는 것이 입증된다.
DAT의 학습 목표는 두 단계로 구성된다. (1) Monte‑Carlo 방식으로 y∼D_harm에서 추출한 유해 응답에 대해 p_diffθ(x|y)로 다채로운 x를 샘플링하고, (2) 연속적 적대적 훈련(CAT)으로 토큰 임베딩에 작은 연속 교란 δ를 가해 최악의 손실을 계산한다. 외부 루프에서는 이 손실을 최소화하고, 원본 모델과의 KL 발산을 정규화 항으로 추가해 성능 붕괴를 방지한다.
이론적으로는 “Surrogate Fidelity Bound” 정리를 제시해, 확산 모델이 원본 조건부 분포와 TV 거리 ε 이하로 가깝다면, DAT가 최소화하는 위험 R_diff와 실제 인구 위험 R_pop 사이의 차이가 2Mε 이하임을 증명한다. 따라서 확산 모델의 품질이 높을수록 인구 위험에 대한 근사도가 향상된다. 실험에서는 Llama‑3‑8B와 Qwen‑2.5‑14B 두 모델에 DAT를 적용해, 기존 AT 기반 방어에 비해 다양한 jailbreak, 번역, 시제 변형 공격에서 성공률을 크게 낮추었으며, 일반 언어 이해 성능도 유지함을 확인한다.
댓글 및 학술 토론
Loading comments...
의견 남기기