긴 컨텍스트 로봇 학습을 위한 핵심 프레임 집중 정책
초록
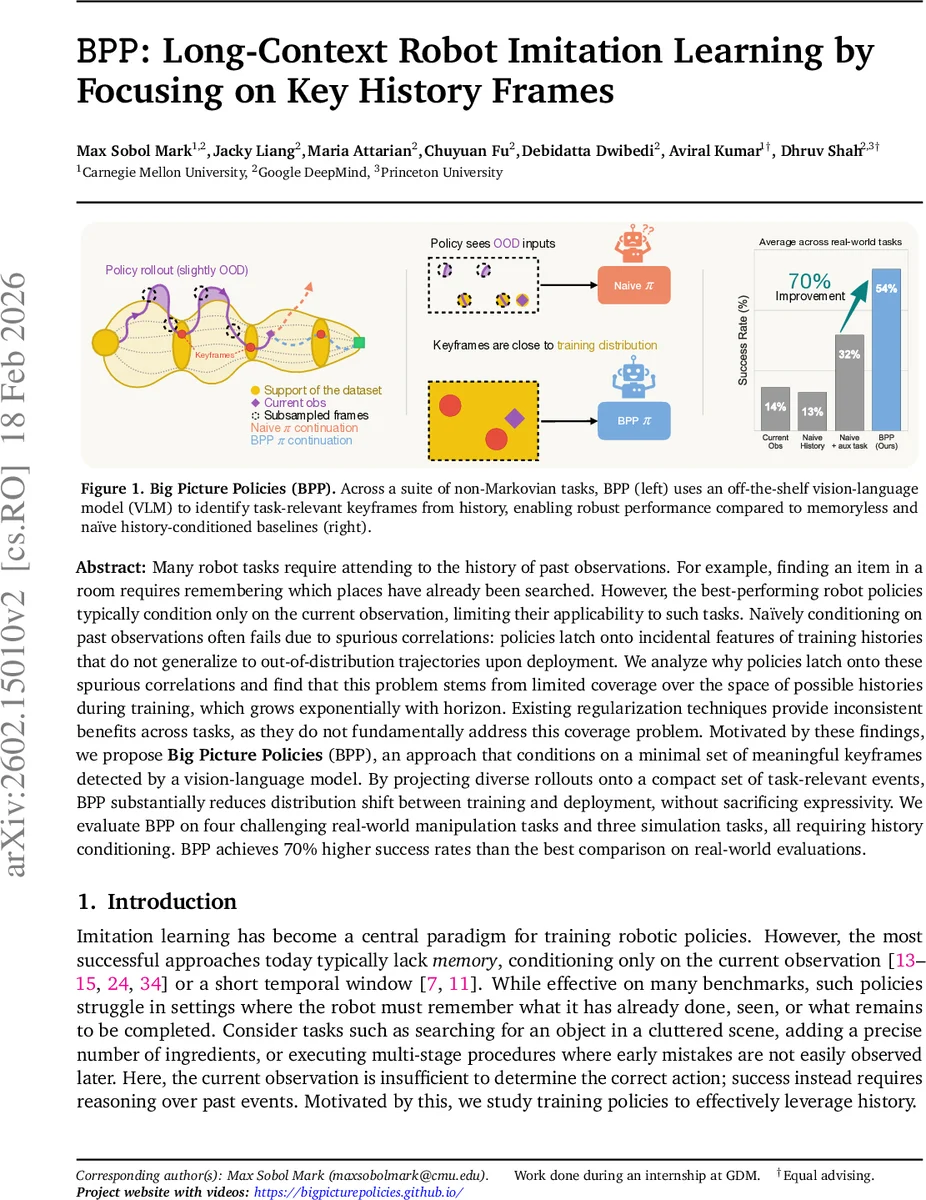
BPP는 비전‑언어 모델을 이용해 과거 관찰 중 작업에 의미 있는 핵심 프레임만을 추출하고, 이를 정책 입력으로 사용함으로써 긴 히스토리 조건의 모방 학습에서 발생하는 스퓨리어스 상관관계를 크게 감소시킨다. 실제 로봇 조작 4개와 시뮬레이션 3개 과제에서 기존 방법 대비 성공률을 평균 70% 이상 향상시켰다.
상세 분석
본 논문은 로봇 조작에서 “과거를 기억해야 하는” 비마르코프 환경을 대상으로, 기존의 히스토리 조건 모방 학습이 왜 쉽게 실패하는지를 체계적으로 분석한다. 저자들은 실패 원인을 두 가지로 귀결한다. 첫째, 훈련 데이터가 가능한 히스토리 공간을 충분히 커버하지 못한다는 ‘커버리지 문제’이다. 히스토리의 조합 수는 시간 지평이 늘어날수록 지수적으로 증가하므로, 인간 테레옵레이터가 제공하는 근접 전문가 시연만으로는 전체 분포를 탐색하기 어렵다. 둘째, 정책이 훈련 시에만 존재하는 특수한 히스토리 패턴에 과도하게 의존하게 되면서, 배포 시에 마주하는 미지의 히스토리에서는 스퓨리어스 상관관계를 학습하게 된다. 기존 연구들은 정규화, 보조 목표, 아키텍처 제한 등으로 스퓨리어스를 완화하려 했지만, 이는 근본적인 히스토리 커버리지 결핍을 해결하지 못한다는 점을 실험적으로 입증한다.
핵심 아이디어는 “전체 히스토리를 그대로 입력”하는 대신, 작업에 실제로 의미 있는 순간, 즉 키프레임만을 추출해 입력 차원을 크게 축소하는 것이다. 이를 위해 저자들은 사전 학습된 오프‑더‑쉘프 비전‑언어 모델(VLM)을 활용한다. VLM에 “이 물체가 잡혔는가?”, “서브골이 완료되었는가?”와 같은 질문을 던짐으로써, 현재 관찰 시퀀스에서 의미 있는 프레임을 자동으로 식별한다. 이렇게 얻어진 키프레임 집합은 히스토리 공간을 압축하면서도 작업 수행에 필요한 모든 정보를 보존한다. 결과적으로 훈련과 배포 시 정책이 마주하는 입력 분포 간 차이가 크게 줄어들어, 스퓨리어스 상관관계에 대한 의존도가 감소한다.
실험에서는 4개의 실제 로봇 조작 과제(두 손 협동 잡기, 마시멜로 정렬, 서랍 탐색, 스택 퍼즐)와 3개의 시뮬레이션 과제(레몬 삽입, 고정/가변 비밀번호 입력, 재료 삽입)를 사용했다. 모든 과제는 히스토리 의존성이 강해 현재 관찰만으로는 올바른 행동을 결정할 수 없다. BPP는 동일한 정책 아키텍처와 동일한 데이터 양을 사용하면서, 기존 메모리 기반 정책이나 naïve 히스토리 조건 정책보다 평균 70% 높은 성공률을 기록했다. 또한, 키프레임 추출 과정이 비교적 가벼워 훈련 시간과 메모리 요구량이 크게 감소했으며, VLM을 고정된 파라미터로 사용함으로써 추가적인 파인튜닝 비용이 들지 않는다.
추가 분석에서는 액션 청킹(action chunking)과 정책 인코더의 역할도 검증한다. 긴 청킹(예: 50스텝)으로 예측하도록 하면 히스토리 정보를 더 견고하게 학습하게 되어, 스퓨리어스 상관관계가 감소한다는 것이 확인되었다. 그러나 청킹만으로는 커버리지 문제를 완전히 해결하지 못한다. 따라서 BPP는 청킹과 키프레임 선택이라는 두 축을 결합해, 히스토리 정보를 압축하면서도 표현력을 유지한다는 점에서 차별화된다.
결론적으로, BPP는 “히스토리 전체를 기억하려는” 접근법이 아니라 “작업에 핵심적인 순간만을 기억하는” 접근법을 제시함으로써, 로봇 모방 학습에서 긴 컨텍스트 문제를 실용적으로 해결한다. 이는 향후 복잡한 장기 의존성을 가진 로봇 작업에 대한 데이터 효율적 학습 및 일반화에 중요한 방향성을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기