경계점 기반 블랙박스 LLM 탈옥: 자동화된 BPJ 공격
초록
BPJ는 단일 플래그 신호만을 이용해 대규모 언어 모델의 안전 분류기를 우회하는 완전 블랙박스 자동 탈옥 기법이다. 목표 문자열을 난이도별 중간 목표(커리큘럼)로 변환하고, “경계점”(플래그가 일부만 발생하는 평가 샘플)을 찾아 공격 문자열을 진화시킨다. 실험에서 Constitutional Classifier와 GPT‑5 입력 감시자를 성공적으로 뚫으며, 수십만~수백만 쿼리를 소모하지만 개별 쿼리에서는 탐지 회피가 가능함을 보여준다. 방어 측면에서는 배치‑레벨 모니터링이 필요함을 제시한다.
상세 분석
BPJ(Boundary Point Jailbreaking)는 기존의 화이트/그레이박스 탈옥 기법과 달리, 오직 “플래그 여부”라는 1비트 피드백만을 활용한다는 점에서 실용적인 위협 모델을 제시한다. 핵심 아이디어는 두 단계로 나뉜다. 첫째, 목표 악성 텍스트를 “노이즈 인터폴레이션”이라는 함수로 변형해 난이도 파라미터 q(또는 n)로 조절된 중간 목표 집합을 만든다. 높은 노이즈 수준에서는 대부분의 입력이 안전 판정을 받아 쉽게 통과하지만, 노이즈를 점차 감소시키면 분류기의 결정 경계에 점점 가까워진다. 둘째, 각 난이도 레벨에서 “경계점”(boundary point, BP)을 선별한다. BP는 현재 공격 프리픽스 집합에 대해 일부는 플래그되고 일부는 플래그되지 않는 입력으로, 이는 공격 강도의 미세 변화를 감지할 수 있는 고신호 샘플이다.
BPJ는 진화적 알고리즘을 사용한다. 공격 프리픽스는 토큰 수준에서 무작위 삽입·삭제·대체 변이를 겪으며, 각 변이는 현재 확보된 BP 집합에 대해 평가된다. 변이가 기존 최선 공격보다 더 많은 BP를 “통과”하면 새로운 후보로 채택된다. 이렇게 반복하면서 BP가 모두 해결되면(모든 프리픽스가 해당 BP를 통과) 해당 난이도 레벨의 BP를 교체하고, 노이즈 레벨을 낮춰 더 어려운 목표로 이동한다. 이 과정은 노이즈 q가 0이 될 때까지 진행되며, 최종적으로 원본 악성 텍스트에 대해 플래그 없이 응답을 얻는 프리픽스를 획득한다.
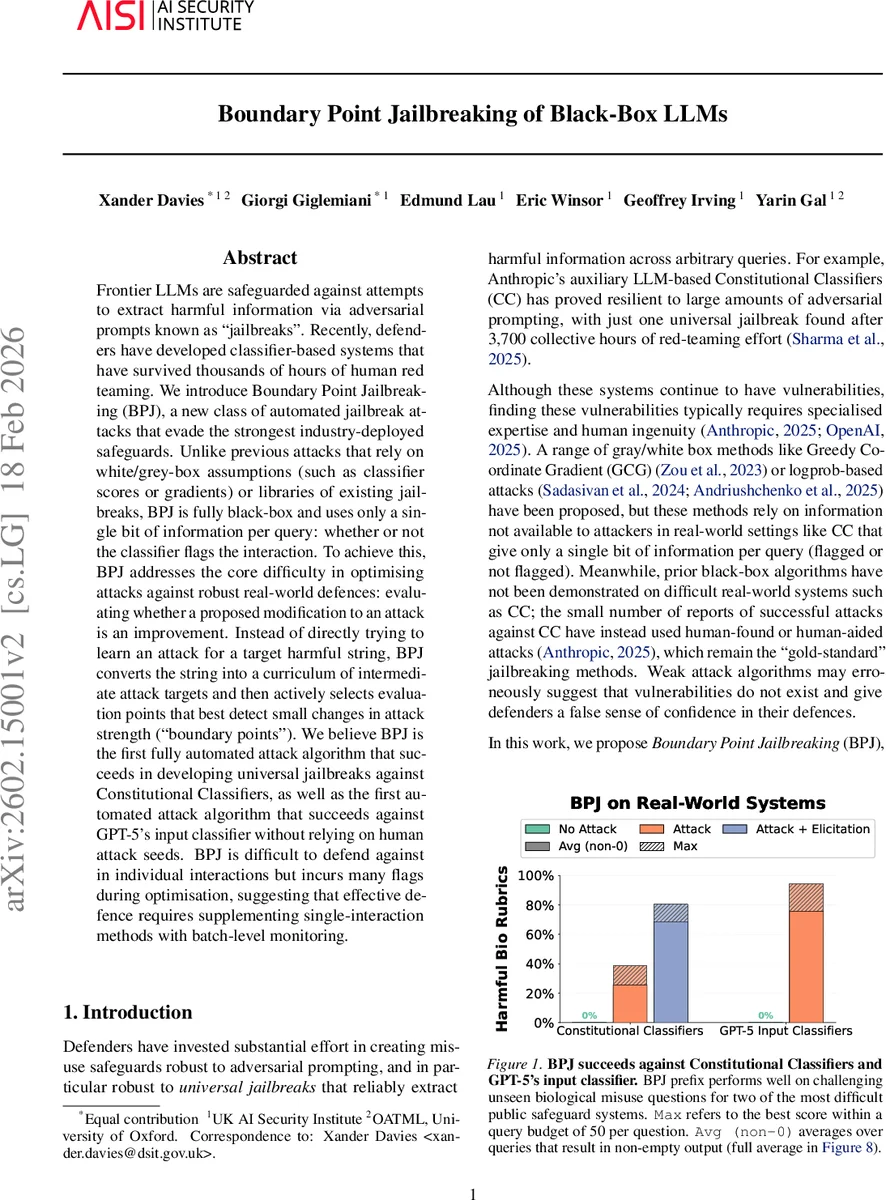
실험 결과는 두 가지 주요 방어체계에 적용되었다. 첫째, Anthropic의 Constitutional Classifier(CC)는 3,700시간의 인간 레드팀에도 불구하고 단일 프리픽스로 다수의 악성 질의를 회피했다. 둘째, OpenAI의 GPT‑5 입력 감시자는 기존 인간‑시드 공격이 필요했으나, BPJ는 전혀 인간 개입 없이 성공했다. 그러나 BPJ는 최적화 단계에서 수백만 쿼리를 발생시키며, 이때 대부분이 플래그된 상태로 기록된다. 따라서 단일 쿼리 기반 방어(예: 실시간 플래그 차단)만으로는 방어가 어려우며, 연속적인 플래그 패턴을 감시하는 배치‑레벨 모니터링이 필수적이다.
이 논문은 몇 가지 한계도 명시한다. 첫째, BPJ는 deterministic binary classifier를 전제로 하며, 확률적 스코어를 제공하는 시스템에는 직접 적용하기 어려울 수 있다. 둘째, 공격 비용이 매우 높아(수백 달러 수준) 일반 사용자가 대규모 쿼리를 수행하기엔 현실적 제약이 있다. 셋째, 논문에서 일부 구현 세부(예: 변이 확률, BP 선택 임계값 λₙ 등)를 비공개로 유지해 재현성을 완전히 검증하기 어렵다. 그럼에도 불구하고, “단일 비트 피드백만으로도 강력한 자동화 탈옥이 가능하다”는 근본적인 교훈은 AI 안전 연구에 큰 충격을 주며, 방어 설계 시 “시간‑연속적 플래그 패턴”과 “쿼리 집합 전체에 대한 메타‑분석”을 반드시 고려해야 함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기