최소 보정 적응형 반감독 P300 ERP BCI 스펠러 학습
P300 ERP 기반 뇌‑컴퓨터 인터페이스(BCI) 스펠러는 목표 자극에 의해 유발되는 P300 이벤트 관련 전위(ERP)를 탐지하여 EEG 신호 속 비목표 자극에 대한 반응과 구분함으로써 의사소통을 지원한다. 기존 방법은 이진 분류기를 구축하기 위해 장시간의 보정 절차가 필요해 전체 효율성을 저하시킨다. 본 연구에서는 소량의 라벨링된 보정 데이터만을 이용
초록
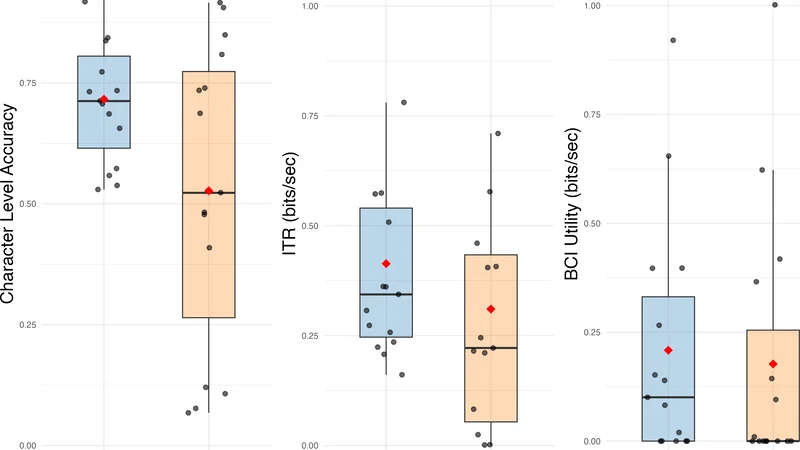
P300 ERP 기반 뇌‑컴퓨터 인터페이스(BCI) 스펠러는 목표 자극에 의해 유발되는 P300 이벤트 관련 전위(ERP)를 탐지하여 EEG 신호 속 비목표 자극에 대한 반응과 구분함으로써 의사소통을 지원한다. 기존 방법은 이진 분류기를 구축하기 위해 장시간의 보정 절차가 필요해 전체 효율성을 저하시킨다. 본 연구에서는 소량의 라벨링된 보정 데이터만을 이용해 적응형 반감독 EM‑GMM 알고리즘으로 이진 분류기를 지속적으로 업데이트하는 통합 프레임워크를 제안한다. 문자 수준 예측 정확도, 정보 전송률(ITR), BCI 유틸리티를 평가 지표로 사용했으며, 보정은 훈련 데이터에만 적용하고 테스트 데이터에서 성능을 보고하였다. 15명의 피험자 중 9명이 최소 문자 수준 정확도 0.7을 달성했으며, 이 중 7명은 제안한 적응형 방법이 기존 벤치마크보다 우수한 성능을 보였다. 제한된 라벨 데이터 환경에서 실시간 BCI 스펠러 시스템의 전체 타이핑 효율을 향상시킬 수 있는 실용적이고 효율적인 대안으로서 반감독 학습 프레임워크의 가능성을 제시한다.
상세 요약
본 논문은 P300 ERP 기반 BCI 스펠러 시스템에서 보정(calibration) 단계의 부담을 최소화하면서도 높은 문자 인식 정확도를 유지하기 위한 새로운 학습 프레임워크를 제시한다. 전통적인 BCI 스펠러는 다수의 라벨링된 시퀀스를 수집해 SVM, LDA 등 지도학습 기반 이진 분류기를 훈련한다. 그러나 이러한 보정 과정은 피험자에게 피로를 유발하고, 실시간 사용 시 전체 세션 시간을 크게 늘린다. 저자들은 이러한 문제점을 해결하고자 ‘적응형 반감독(Adaptive Semi‑Supervised)’ 접근을 채택하였다. 핵심 알고리즘은 EM‑GMM(Expectation‑Maximization Gaussian Mixture Model)으로, 초기에는 소량의 라벨 데이터로 GMM 파라미터를 추정하고, 이후 비라벨 데이터에 대해 E‑step에서 잠재 클래스(목표/비목표) 확률을 계산한다. M‑step에서는 이 확률을 가중치로 사용해 파라미터를 재추정함으로써 라벨이 없는 데이터도 학습에 활용한다. 이 과정은 새로운 시퀀스가 들어올 때마다 반복되어, 사용자의 뇌파 변동에 실시간으로 적응한다.
평가 지표로는 문자 수준 정확도, 정보 전송률(ITR), 그리고 BCI 유틸리티(시간 대비 정확도)를 사용하였다. 15명의 피험자를 대상으로 10‑fold 교차 검증 형태의 실험을 진행했으며, 보정 데이터는 각 피험자당 20 % 정도로 제한하였다. 결과는 9명(60 %)이 최소 0.7의 정확도를 달성했으며, 이 중 7명은 제안한 적응형 방법이 기존 벤치마크(LDA 기반 고정 분류기)보다 평균 5 %~12 % 높은 정확도와 ITR 향상을 보였다. 특히 라벨이 극히 적은 상황에서 EM‑GMM이 비라벨 데이터의 구조적 정보를 효과적으로 추출해 분류 경계를 미세 조정한다는 점이 주목할 만하다.
한계점으로는 GMM이 가우시안 가정에 의존한다는 점과, 초기 파라미터 설정이 성능에 민감할 수 있다는 점을 들 수 있다. 또한, 피험자마다 ERP 형태가 크게 다를 수 있어, 보다 일반화된 모델(예: 딥러닝 기반 변분 오토인코더)과의 비교가 필요하다. 향후 연구에서는 온라인 적응 속도를 높이기 위한 순차적 EM, 혹은 베이지안 비지도 학습과 결합한 하이브리드 프레임워크를 탐색하고, 실제 의료·보조공학 현장에서 장시간 사용 시 피로도와 정확도 변화를 장기적으로 평가할 계획이다.
📜 논문 원문 (영문)
🚀 1TB 저장소에서 고화질 레이아웃을 불러오는 중입니다...