로그잇 거리와 표현 유사성의 새로운 연결
초록
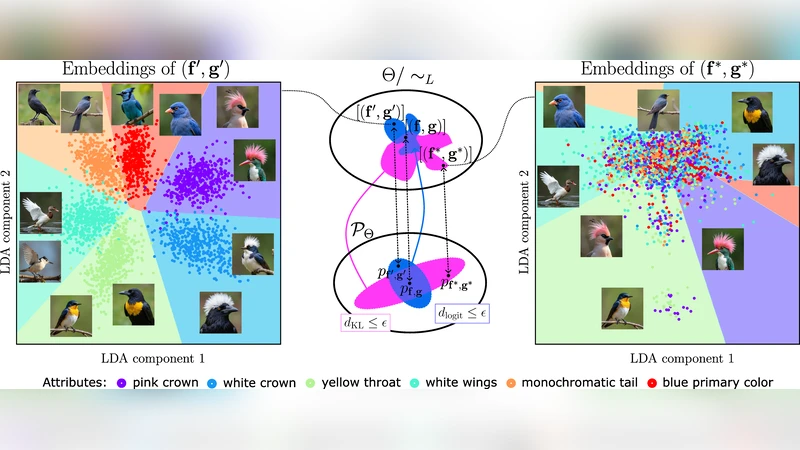
조건부 분포가 거의 동일할 때, 동일 식별 클래스에 속하는 모델들의 내부 표현은 가역적인 선형 변환으로 일치한다는 기존 식별성 결과를 확장한다. 저자는 로그잇 차이에 기반한 새로운 거리 측정을 도입해, 이 거리가 작을 경우 모델 간 선형 표현 유사성이 보장된다는 정리를 증명한다. KL 발산이 로그잇 거리를 상한으로 제공하지만, 실제 상황에서는 너무 느슨해 선형 구조 보존을 설명하지 못한다. 실험에서는 로그잇 거리 기반 증류가 교사의 선형 프로브 가능 개념을 더 잘 유지한다는 결과를 보여준다.
상세 분석
이 논문은 식별 가능성(identifiability) 이론을 활용해, 두 모델이 동일한 조건부 확률분포를 생성하면 그들의 내부 표현이 가역적인 선형 변환(invertible linear transformation)으로 연결된다는 기존 결과를 출발점으로 삼는다. 여기서 저자들은 “근사” 상황, 즉 두 모델의 조건부 분포가 완전히 동일하지 않고 KL 발산 등으로 가깝지만 차이가 있을 때에도 비슷한 선형 관계가 유지될 수 있는지를 탐구한다. Nielsen et al. (2025)의 결과를 인용해 KL 발산이 작아도 로그잇(logit) 차이는 크게 남을 수 있음을 지적하고, 이를 보완하기 위해 로그잇 차이에 기반한 새로운 거리(metric)를 정의한다.
핵심 기여는 다음과 같다. 첫째, 모델의 식별 클래스(identifiability class)를 이용해 정의한 ‘표현 비유사도(representational dissimilarity)’를 제시하고, 이 비유사도가 로그잇 거리의 상한임을 정리(정리 1)로 증명한다. 즉, 두 모델의 로그잇 차이가 작을수록 그들의 내부 표현은 가역적인 선형 변환을 통해 서로 근접한다는 강력한 보장을 제공한다. 둘째, 모델 확률이 0에 가까이 떨어지지 않는다는 가정 하에 KL 발산이 로그잇 거리의 상한이 될 수 있음을 보이지만, 실제 데이터에서는 이 상한이 너무 크게 잡혀 실용적인 제어를 제공하지 못한다는 한계를 명시한다. 셋째, 이러한 이론적 결과를 검증하기 위해 합성 데이터와 이미지 데이터(CIFAR‑10, ImageNet‑subset 등)에서 교사 모델과 학생 모델을 각각 KL 기반 증류와 로그잇 거리 기반 증류로 학습시킨다. 실험 결과, 로그잇 거리 기반 증류는 선형 프로브(linear probe)를 이용한 인간 해석 가능 개념(예: 색, 형태, 텍스처)의 회복률이 KL 기반 증류보다 현저히 높으며, 또한 표준화된 선형 표현 유사성 지표(CCA, SVCCA)에서도 우수한 점수를 기록한다.
이 논문은 두 가지 중요한 메시지를 전달한다. 첫째, 단순히 출력 확률 분포의 KL 발산을 최소화하는 것이 내부 표현 구조를 보존한다는 보장을 제공하지 않으며, 특히 선형 탐색 가능성(linear probeability) 같은 해석 가능성 측면에서 한계가 있다. 둘째, 로그잇 차이에 기반한 거리 측정은 이러한 한계를 극복하고, 모델 압축·증류 과정에서 교사의 표현적 특성을 보다 충실히 전달할 수 있는 실용적인 대안이 된다. 향후 연구에서는 로그잇 거리와 다른 정규화 기법을 결합하거나, 비선형 변환(예: 뉴럴 토폴로지 정렬)과의 관계를 탐구함으로써 더 일반적인 표현 보존 이론을 확장할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기