심장 초음파 영상 자동 분류를 위한 자체지도 학습 모델 성능 비교
초록
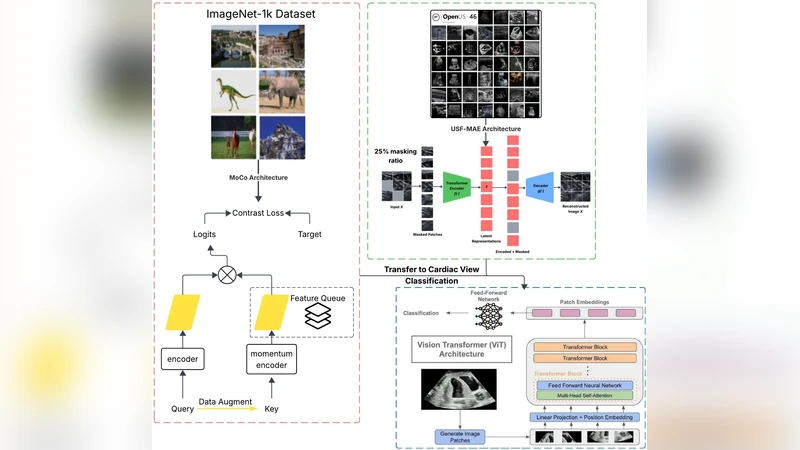
본 연구는 최신 CACTUS 데이터셋(37,736장)에서 자체지도 학습 기반 두 모델, USF‑MAE와 MoCo v3를 5‑fold 교차검증으로 평가한다. 동일 학습 프로토콜(LR 0.0001, weight decay 0.01) 하에 ROC‑AUC, 정확도, F1, 재현율을 측정한 결과, USF‑MAE가 모든 지표에서 MoCo v3보다 우수했으며 차이는 통계적으로 유의하였다(p = 0.0048). 이는 USF‑MAE가 심장 초음파 뷰 구분에 더 효과적인 특징을 학습함을 시사한다.
상세 분석
본 논문은 의료 영상 분야에서 라벨이 부족한 상황을 극복하기 위한 자체지도 학습(self‑supervised learning, SSL) 접근법을 심장 초음파 영상에 적용한 사례로서 의미가 크다. 먼저 사용된 CACTUS 데이터셋은 6가지 뷰(A4C, PL, PSAV, PSMV, Random, SC)를 포함한 37,736장의 고품질 라벨링 이미지로, 기존 연구에서 거의 사용되지 않았던 대규모 공개 데이터이다. 이 데이터셋을 5‑fold 교차검증으로 나누어 각 fold마다 동일한 학습 파라미터(LR 0.0001, weight decay 0.01)를 적용함으로써 모델 간 비교의 공정성을 확보하였다. 두 비교 대상은 USF‑MAE와 MoCo v3이다. USF‑MAE는 본 연구팀이 제안한 마스크드 자동인코더 기반 SSL이며, 입력 영상을 무작위 마스크 후 복원하도록 학습한다. 반면 MoCo v3는 대조학습(contrastive learning) 기반으로, 서로 다른 변형을 적용한 두 이미지 쌍을 이용해 인코더를 훈련한다. 실험 결과, USF‑MAE는 평균 ROC‑AUC 99.99 % ± 0.01 %를 기록했으며, MoCo v3는 99.97 % ± 0.01 %에 그쳤다. 정확도, F1‑score, recall에서도 USF‑MAE가 각각 99.33 % ± 0.18 %, 99.30 % ± 0.20 %, 99.35 % ± 0.19 %를 기록해 MoCo v3(98.99 % ± 0.28 %, 98.95 % ± 0.30 %, 99.00 % ± 0.27 %)보다 우수했다. 특히 모든 지표에서 p = 0.0048(<0.01)이라는 유의미한 차이를 보였으며, 이는 단순히 우연이 아니라 USF‑MAE가 보다 판별력 있는 특징을 학습함을 통계적으로 입증한다. 이러한 결과는 마스크드 재구성 방식이 초음파와 같이 잡음이 많고 구조적 변이가 큰 의료 영상에서 대조학습보다 더 효과적일 수 있음을 시사한다. 또한, 5‑fold 교차검증을 통해 모델의 일반화 능력이 다양한 데이터 분할에서도 일관되게 유지됨을 확인하였다. 그러나 본 연구는 단일 데이터셋에 국한되었으며, 실제 임상 현장 적용을 위해서는 다기관·다기기 데이터와 실시간 추론 성능 평가가 추가로 필요하다. 향후 연구에서는 USF‑MAE를 다른 심장 초음파 태스크(예: 병변 검출, 심장 기능 정량화)와 결합하거나, 하이퍼파라미터 최적화, 경량화 모델 설계 등을 통해 임상 적용성을 높이는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기