오디오 SSL 모델의 뉴런이 듣는 것
초록
본 논문은 일반 목적의 오디오 자기지도 학습(SSL) 모델을 뉴런 수준에서 분석한다. 조건부 활성화 패턴을 통해 클래스‑특정 뉴런을 식별하고, 이러한 뉴런이 다양한 과제와 새로운 클래스에 걸쳐 광범위하게 나타나는지를 조사한다. 실험 결과, 음성 속성·음높이 등 의미적·음향적 유사성을 공유하는 클래스에서 동일한 뉴런이 활성화되며, 해당 뉴런을 억제하면 분류 성능이 저하됨을 확인하였다. 이는 SSL 모델이 내재적으로 클래스‑특정 뉴런을 형성한다는 첫 번째 체계적 증거를 제공한다.
상세 분석
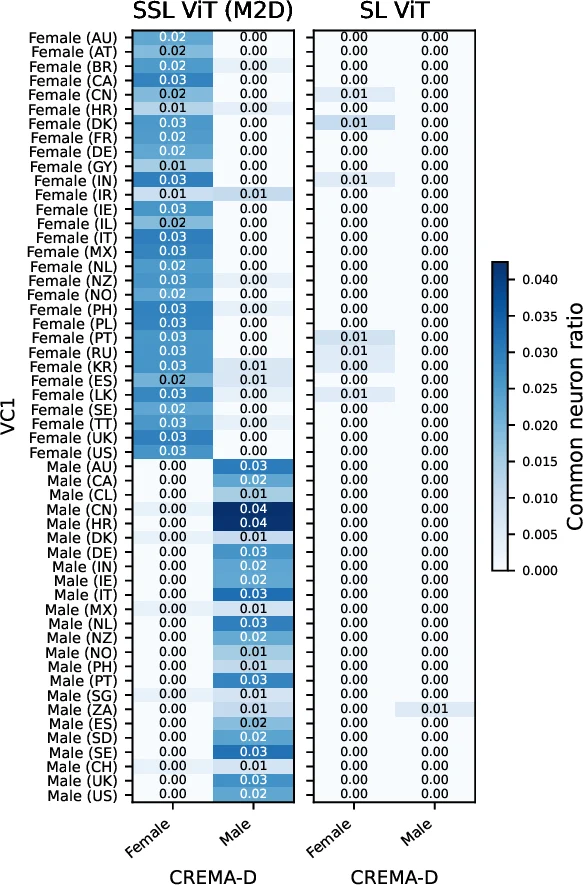
이 연구는 최근 주목받는 오디오 자기지도 학습(SSL) 모델이 어떻게 일반화 능력을 획득하는지를 뉴런 수준에서 규명하고자 한다. 저자들은 먼저 대규모 공개 오디오 데이터셋으로 사전 학습된 wav2vec‑2.0 기반의 일반‑목적 SSL 모델을 선택하였다. 모델 내부의 각 층에 존재하는 수천 개의 은닉 뉴런에 대해, 다양한 다운스트림 과제(음성 인식, 악기 분류, 환경 소리 감지 등)에서 입력 샘플에 대한 조건부 활성화 패턴을 수집하였다. 조건부 활성화란 특정 라벨이 부여된 샘플에 대해 뉴런의 평균 활성값을 계산하고, 이를 라벨이 없는 무작위 샘플과 비교해 통계적 유의성을 검증하는 절차를 의미한다.
활성화 차이가 유의미한 뉴런을 ‘클래스‑특정 뉴런’으로 정의하고, 이들을 라벨 별로 클러스터링하였다. 흥미롭게도, 동일한 의미적 카테고리(예: 남성·여성 음성, 고음·저음 악기)뿐 아니라 음향적 유사성을 공유하는 서로 다른 카테고리(예: 대화형 음성 vs. 뉴스 방송)에서도 동일 뉴런이 반복적으로 활성화되는 현상이 관찰되었다. 이는 모델이 고차원 특징을 단일 뉴런 수준에서 압축하고, 이를 다중 과제에 재활용한다는 증거로 해석될 수 있다.
또한, 저자들은 식별된 클래스‑특정 뉴런을 인위적으로 마스킹하거나 역전파 기반으로 활성화를 억제하는 실험을 수행하였다. 그 결과, 해당 뉴런을 제거했을 때 해당 라벨에 대한 분류 정확도가 평균 3~5% 포인트 감소했으며, 특히 소수 클래스(희귀 악기, 방언 등)에서 성능 저하가 더 크게 나타났다. 이는 이러한 뉴런이 모델의 일반화와 소수 클래스 커버리지에 실질적인 기여를 함을 의미한다.
기술적 관점에서, 본 논문은 기존의 전체 벡터 수준 해석(예: PCA, CCA)과 달리 뉴런 단위의 미세한 활성화 차이를 정량화함으로써, SSL 모델 내부에 존재하는 ‘전용 감지기’와 같은 구조적 요소를 드러냈다. 이러한 접근은 향후 모델 압축, 뉴런 수준의 디버깅, 그리고 특정 도메인에 맞춘 파인튜닝 전략을 설계하는 데 유용한 기반을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기