뇌졸중 CT 영상 분류를 위한 듀얼 인코더 StrokeNeXt 모델
StrokeNeXt는 두 개의 ConvNeXt 인코더를 병렬로 사용하고, 1차원 합성곱 기반 경량 디코더로 특징을 융합해 뇌 CT 영상에서 정상·뇌졸중 여부와 허혈·출혈 아형을 고정밀·고속으로 구분한다. 6,774장의 실제 데이터셋에서 정확도 0.988, F1 0.98 이상을 달성했으며, 기존 CNN·Transformer 모델 대비 통계적으로 유의미한 성능 향상과 우수한 캘리브레이션을 보였다.
저자: ** *제공된 원문에 저자 정보가 명시되지 않았습니다.* (논문 본문이나 메타데이터에서 확인 필요) **
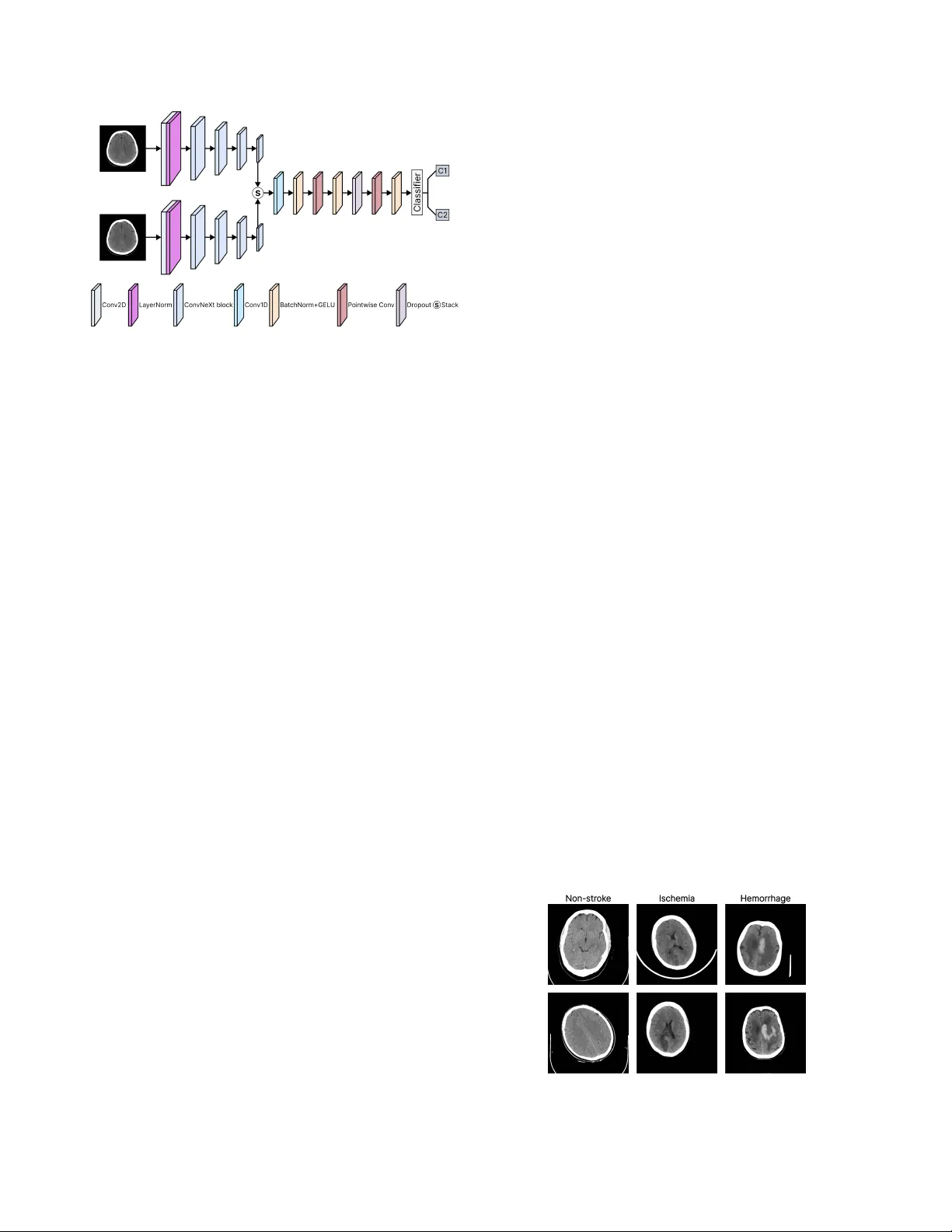
본 논문은 뇌졸중 진단에 필수적인 CT 영상의 자동 분류를 목표로, 새로운 딥러닝 아키텍처인 StrokeNeXt를 제안한다. StrokeNeXt는 두 개의 ConvNeXt 인코더를 병렬로 배치한 듀얼‑브랜치 구조를 채택한다. 각 인코더는 파라미터를 공유하지 않으며 동일한 입력 이미지를 독립적으로 처리함으로써 서로 다른 시각적 특징을 학습한다. 이러한 설계는 단일 인코더 기반 CNN이 놓치기 쉬운 미세 병변을 보완적으로 포착하도록 유도한다. ConvNeXt는 ResNet‑50을 기반으로 커다란 7×7 커널, GELU 활성화, 레이어 정규화 등을 도입해 순수 합성곱 모델임에도 Transformer 수준의 표현력을 제공한다. 따라서 StrokeNeXt는 강력한 백본을 유지하면서도 연산 효율성을 확보한다.
두 인코더의 출력은 1차원 합성곱(k=2)으로 스택된 시퀀스 차원을 압축한다. 이 단계는 단순한 채널별 합산이 아니라 두 벡터 간의 교차 채널 상호작용을 학습하도록 설계돼, 각 브랜치가 강조하는 특징을 가중치 조절해 융합한다. 이후 bottleneck 변환 블록이 두 개의 1×1 합성곱과 GELU, BatchNorm, Dropout으로 구성돼, 차원을 C→H→C 형태로 압축‑확장하면서 비선형성을 부여한다. H는 모델 용량을 미세 조정할 수 있는 하이퍼파라미터로, 인코더 크기에 비례하지 않아 전체 FLOPs를 크게 늘리지 않는다. 이러한 설계는 파라미터 효율성을 극대화하면서도 학습 안정성과 예측 캘리브레이션을 향상시킨다.
실험 데이터는 TEKNOFEST 2021 대회에서 공개된 6,774장의 뇌 CT 이미지이며, 비뇌졸중(4,551), 출혈성(1,093), 허혈성(1,130)으로 라벨링되어 있다. 데이터는 80‑10‑10 비율로 학습·검증·테스트 셋으로 분할했고, 랜덤 수평 뒤집기, ±10° 회전, 밝기·대비·채도 변동을 포함한 데이터 증강을 적용했다. 이미지는 224×224 크기의 3채널 형태로 변환하고, ImageNet 평균·표준편차로 정규화하였다.
학습은 PyTorch 기반으로 Automatic Mixed Precision을 활용했으며, AdamW(learning rate = 1e‑4, weight decay = 1e‑5)와 ReduceLROnPlateau 스케줄러를 사용했다. 배치 크기는 80, epoch 수는 20이며, CrossEntropy 손실에 라벨 스무딩(0.1)을 적용했다. 모든 모델은 동일한 학습 프로토콜을 따랐으며, ConvNeXt 백본은 torchvision 기본 하이퍼파라미터를 그대로 사용했다.
성능 평가는 정확도, 정밀도, 재현율, F1, AUROC, AUPRC, Balanced Accuracy, MCC, Brier Score, Expected Calibration Error(ECE) 등 다차원 지표와 함께, 클래스별 민감도·특이도, McNemar 검정을 통한 통계적 유의성 검증을 포함한다.
결과적으로 StrokeNeXt‑tiny(ConvNeXt‑tiny 백본) 모델은 정상·뇌졸중 구분에서 97.8% 정확도, 0.95 MCC, 0.053 ECE를 기록했으며, inference latency는 2 ms, 초당 570 이미지 처리량을 달성했다. 모델 크기를 ConvNeXt‑large까지 확장하면 정확도 98.7%, MCC 0.97에 도달하지만 FLOPs가 69 G, 파라미터 400 M으로 증가해 latency 9 ms, throughput 113 img/s로 감소한다.
비교 대상인 MobileNetV2, VGG16, ResNet50/152, Swin‑Transformer 등은 모두 86‑90% 수준의 정확도와 0.65‑0.75 MCC에 머물렀으며, 캘리브레이션 지표(Brier, ECE)에서도 StrokeNeXt에 비해 열등했다. 경량 CNN은 높은 처리량을 보였지만 정확도와 신뢰도에서 크게 뒤처졌다. 따라서 StrokeNeXt는 정확도·신뢰도·연산 효율성 사이에서 최적의 균형을 제공한다는 점에서 임상 현장 적용 가능성이 높다.
추가 분석에서는 두 인코더가 서로 다른 특성을 학습한다는 가설이 실험적으로 검증되었으며, 이는 멀티모달(CT + MRI)이나 다중 라벨 문제에 확장 가능성을 시사한다. 또한 모델은 20 epoch 내에 15분 이하의 학습 시간으로 수렴했으며, 파라미터 공유 없이도 효과적인 특성 융합이 가능함을 보여준다.
결론적으로, StrokeNeXt는 시암쌍둥이 ConvNeXt 인코더와 1D 합성곱 기반 경량 디코더를 결합해 뇌졸중 CT 영상 분류에서 기존 최첨단 모델을 능가하는 성능을 달성했으며, 높은 캘리브레이션 품질과 실시간 추론 속도를 동시에 만족한다. 이는 제한된 의료 인프라에서도 AI 기반 진단 보조 도구로 활용될 수 있는 실용적인 솔루션이라 할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기