델 데이터만으로 범용 단백질‑리간드 결합 예측 모델을 만든 헤르메스
초록
헤르메스는 수백 개 단백질을 대상으로 한 DNA‑인코딩 화학 라이브러리(DEL) 스크리닝 데이터를 전적으로 학습한 경량 트랜스포머이다. 전통적인 친화도 값 없이도 바이너리 결합 여부를 예측하며, 보지 않은 단백질, 새로운 화학 스캐폴드, 그리고 공개된 결합 데이터베이스와 고처리량 스크리닝(HTS) 결과에서도 좋은 일반화 성능을 보인다. 모델은 단순한 시퀀스‑기반 구조와 교차‑어텐션을 사용해 초고속 추론이 가능하고, 기존 구조 기반 딥러닝 모델에 비해 연산 비용이 크게 낮다.
상세 분석
헤르메스는 두 개의 사전학습 임베딩(ESM2‑protein, ChemBER‑ligand)을 입력으로 받아, 각각의 토큰 시퀀스에 자체 어텐션을 적용한 뒤 교차‑어텐션 모듈을 통해 단백질과 리간드 사이의 상호작용 정보를 교환한다. 이후 두 개의 어텐션 풀링 레이어가 토큰들을 고정 길이 벡터로 압축하고, 이 벡터들을 연결(concatenate)한 뒤 다층 퍼셉트론(MLP)으로 결합 확률을 출력한다. 핵심 설계는 “경량화”와 “다중 체크포인트 앙상블”에 있다. 모델 자체는 파라미터 수가 수백만 수준에 불과해 GPU 하나에서도 수천 개의 단백질‑리간드 쌍을 초당 처리할 수 있다. 학습 데이터는 6.5 M 규모의 Kin0 라이브러리를 사용한 239개의 단백질(약 2/3이 키나제) DEL 스크리닝 결과이며, 히트‑콜링 절차를 통해 이진 라벨(히트/노히트)로 변환한다. 데이터 불균형을 해결하기 위해 각 단백질당 양성 샘플 수를 상한선으로 제한하고, 양성 대비 일정 비율의 난이도 높은 음성 샘플을 추가로 샘플링한다. 이러한 샘플링 전략은 9개의 서로 다른 하이퍼파라미터 조합과 샘플링 비율을 적용해 다양한 체크포인트를 생성하고, 최종 예측에서는 이들을 평균화한다.
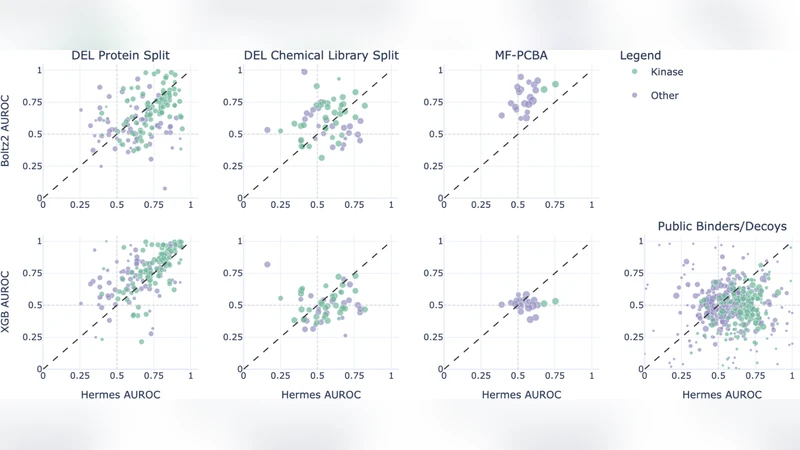
평가에서는 네 가지 벤치마크를 사용하였다. 첫 번째는 훈련에 포함되지 않은 단백질을 대상으로 한 DEL Protein Split(164 target), 두 번째는 동일 단백질이지만 다른 화학 라이브러리(AMA020)를 사용한 DEL Chemical Library Split(59 target), 세 번째는 Papyrus++에서 추출한 고친밀도 바인더와 GuacaMol 디코이의 합성 디코이(403 target), 마지막은 MF‑PCBA의 HTS 기반 데이터(다양한 비키나제 타깃)이다. 각 벤치마크에 대해 단백질별 AUROC와 평균 정밀도(AP)를 보고했으며, 키나제와 비키나제 그룹으로 별도 분석했다. 결과는 헤르메스가 모든 벤치마크에서 일관된 AUROC ≈ 0.80‑0.85 수준을 기록했으며, 특히 DEL 기반 테스트에서는 0.90에 육박하는 성능을 보였다. 공개된 구조 기반 모델인 Boltz‑2와 비교했을 때, Boltz‑2는 높은 정확도를 보였지만 추론 비용이 수백 배 더 컸다. XGBoost 베이스라인은 DEL 데이터에 대한 메모리화 경향이 강했으며, 헤르메스와 비교해 전반적으로 낮은 AUROC를 기록했다.
핵심 인사이트는 다음과 같다. (1) DEL 스크리닝은 실험 프로토콜이 일관되므로, 대규모 이진 라벨 데이터만으로도 단백질‑리간드 상호작용의 일반화 가능한 표현을 학습할 수 있다. (2) 사전학습된 시퀀스 임베딩과 교차‑어텐션 구조는 복잡한 3D 구조 정보를 명시적으로 사용하지 않아도 충분히 강력한 결합 신호를 포착한다. (3) 데이터 샘플링 전략—특히 양성 샘플 상한 제한과 하드 네거티브 포함—이 모델의 과적합을 방지하고 다양한 타깃에 대한 전이 학습을 가능하게 한다. (4) 경량 트랜스포머는 대규모 가상 스크리닝(수억~수십억 화합물)에서 실시간 추론이 가능하므로, 실제 약물 발견 파이프라인에 바로 적용할 수 있다. (5) 한계점으로는 키나제 중심의 훈련 데이터가 비키나제 타깃에 대한 일반화에 약간의 편향을 남기며, 이진 라벨 자체가 실제 친화도 정량값을 대체하지 못한다는 점이다. 향후 연구에서는 다양한 단백질 패밀리를 균등하게 포함한 DEL 구축, 멀티태스크(이진+회귀) 학습, 그리고 구조 기반 정보와의 하이브리드 모델링이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기