FireRed 이미지 편집 모델의 혁신적 데이터와 학습 전략
초록
FireRed‑Image‑Edit 1.0은 1.6 B개의 텍스트‑이미지·이미지‑편집 쌍을 기반으로, 100 M 이상의 고품질 샘플을 선별해 구축한 대규모 데이터셋과 다단계 학습 파이프라인을 제안한다. 변수 해상도 배치를 위한 Multi‑Condition Aware Bucket Sampler, 프롬프트 재인덱싱을 포함한 Stochastic Instruction Alignment, DPO에 적용한 Asymmetric Gradient Optimization, 텍스트 편집을 위한 DiffusionNFT와 OCR 기반 보상, 그리고 정체성 보존을 위한 Consistency Loss 등을 도입해 효율성과 제어성을 동시에 향상시켰다. 새롭게 설계한 REDEdit‑Bench(15개 편집 카테고리)에서 기존 오픈소스·상용 모델을 능가하는 성능을 기록했으며, 코드·모델·벤치마크를 공개한다.
상세 분석
본 논문은 이미지 편집용 diffusion transformer의 전반적인 파이프라인을 체계적으로 재설계한 점에서 의미가 크다. 첫 번째 핵심은 데이터 구축이다. 1.6 B개의 원시 샘플을 수집한 뒤, 중복 제거, 포토메트릭·통계 필터링, 아티팩트 제거, AIGC 검출 등 5단계의 정교한 전처리를 거쳐 100 M 이상의 고품질 데이터셋을 만든다. 특히 텍스트‑이미지와 이미지‑편집 데이터를 1:1 비율로 균형 맞춘 점은 텍스트 의미 이해와 편집 능력 사이의 시너지를 극대화한다.
두 번째로 제시된 Multi‑Condition Aware Bucket Sampler는 입력 이미지 수와 해상도가 작업마다 크게 달라지는 편집 시나리오에 맞춰 배치 내 패딩을 최소화한다. 이는 GPU 메모리 효율을 크게 높이며, 학습 속도와 비용을 절감한다. Stochastic Instruction Alignment은 데이터 콜레이션 단계에서 이미지‑프롬프트 매핑을 무작위로 재배열하고 동적 재인덱싱을 수행해, 모델이 특정 이미지 순서에 과도하게 의존하지 않도록 만든다. 결과적으로 다중 레퍼런스 편집에서 공간‑내용 디코플링이 강화된다.
학습 최적화 측면에서는 Asymmetric Gradient Optimization for DPO를 도입해, 직접 선호 최적화(Direct Preference Optimization) 과정에서 정규화된 그라디언트와 비대칭 학습률을 적용한다. 이는 인간 피드백 기반 강화학습 시 발생하기 쉬운 불안정성을 완화하고, 편집 의도와 일치하는 미세 조정을 가능하게 한다. 또한 DiffusionNFT는 레이아웃‑인식 OCR 보상을 통해 텍스트 삽입·수정 작업에서 문자 정렬과 가독성을 정량화한다. Consistency Loss는 원본 이미지와 편집 결과 사이의 고차원 특징 일치를 강제해, 인물·얼굴 등 정체성 유지가 중요한 작업에서 눈에 띄는 품질 향상을 보인다.
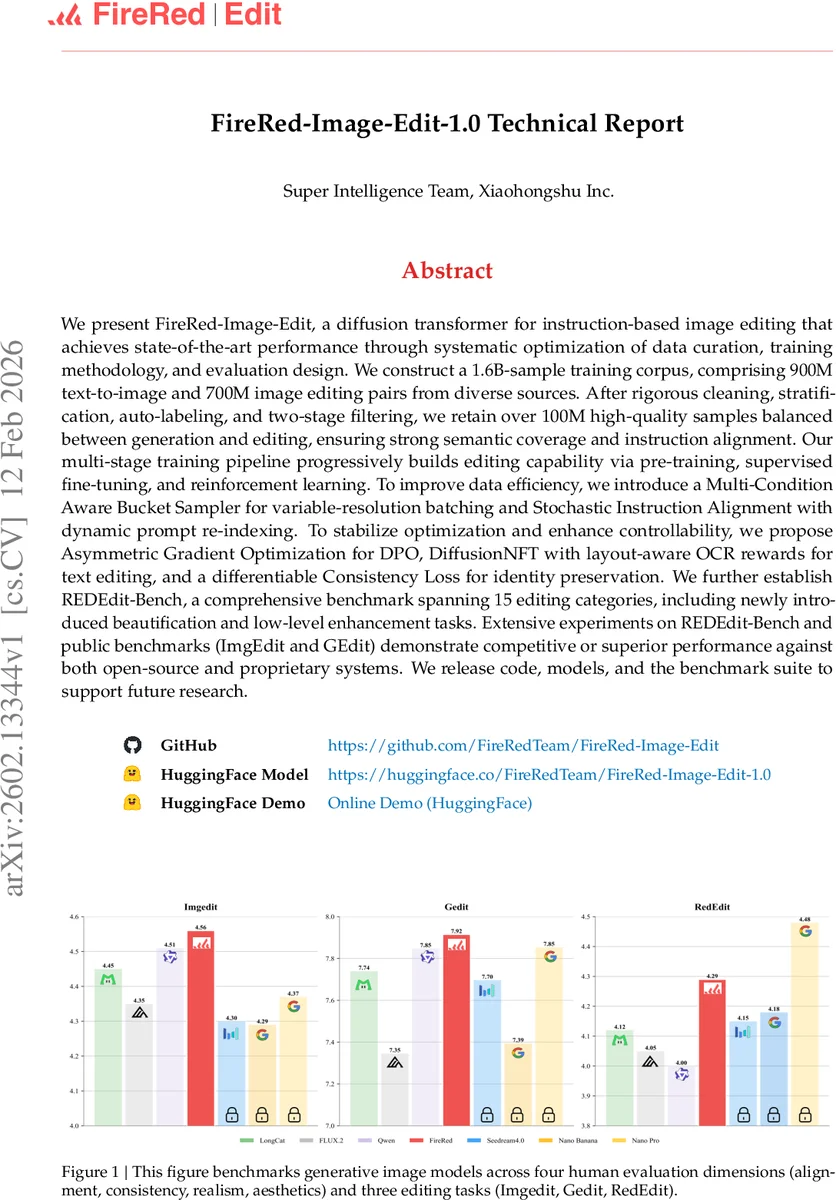
벤치마크인 REDEdit‑Bench은 기존 ImgEdit·GEdit에 더해 미용·저수준 강화 등 15개 카테고리를 포함한다. 인간 평가(정렬, 일관성, 사실성, 미학)와 자동 메트릭을 복합적으로 사용해 모델의 전반적 유용성을 측정한다. 실험 결과 FireRed‑Image‑Edit 1.0은 대부분의 카테고리에서 최신 오픈소스 모델과 상용 프로프라이어터리 시스템을 앞선 점수를 획득했으며, 특히 텍스트‑중심 편집과 구조적 변형에서 두드러진 성능을 보였다.
전반적으로 데이터 품질, 배치 효율, 학습 안정성, 그리고 평가 체계까지 전 과정을 일관되게 최적화함으로써, 대규모 파라미터 스케일링에 의존하지 않고도 경쟁력 있는 이미지 편집 모델을 구현한 점이 가장 큰 공헌이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기