가이아2 비동기 환경에서 LLM 에이전트 평가 벤치마크
초록
**
가이아2는 스마트폰 앱 기반의 비동기 시뮬레이션을 제공하여, 시간 제약·노이즈·모호성·다중 에이전트 협업 등 현실적인 상황에서 LLM 에이전트의 행동을 정밀하게 검증한다. 각 시나리오는 쓰기‑액션 검증기로 검증되며, 이를 통해 강화학습 기반 보상 설계가 가능하다. 실험 결과 GPT‑5‑high가 42 % pass@1 로 최고 점수를 기록했지만 시간 민감 작업에서 약점이 드러났으며, 오픈소스 모델은 전반적으로 20 % 수준에 머물렀다.
**
상세 분석
**
가이아2는 기존 정적·동기식 벤치마크가 놓친 ‘환경 자체가 에이전트와 무관하게 진행되는’ 비동기성을 핵심 설계 목표로 삼았다. 이를 위해 저자들은 ARE(Agents Research Environments)라는 범용 시뮬레이션 프레임워크를 구축했으며, 모바일 스마트폰 환경을 모델링한 12개의 앱(메일, 메시지, 캘린더 등)과 101개의 도구를 제공한다. 각 앱은 상태ful API 형태로 정의돼 읽기·쓰기 호출을 구분하고, 쓰기 행동마다 오라클 어노테이션과 비교하는 ‘write‑action verifier’를 통해 즉시 정밀 검증이 이루어진다.
시나리오는 1,120개(핵심 800개 + 확장 320개)로 구성되며, 실행·검색·모호성·적응·시간·다중‑에이전트·노이즈 등 7가지 핵심 능력을 별도 스플릿으로 평가한다. 특히 ‘시간’ 스플릿은 일정 예약·리마인더와 같이 외부 이벤트가 에이전트의 사고 시간 동안 발생하도록 설계돼, 모델이 응답 지연에 따라 환경이 변하는 상황을 테스트한다. ‘노이즈’ 스플릿은 도구 호출 실패, 스팸 메일 등 의도적 방해 요소를 삽입해 견고성을 측정한다.
평가 파이프라인은 ReAct 기반의 순차적 도구 호출 루프를 기본으로 하며, 사전·사후 훅을 통해 환경 알림을 에이전트 컨텍스트에 주입한다. 병렬 도구 호출(Parallel Tool Calling)과 비교했을 때 실행 효율은 향상되지만 최종 성공률에는 차이가 없으며, 이는 모델 자체의 인지·계획 능력이 병목임을 시사한다.
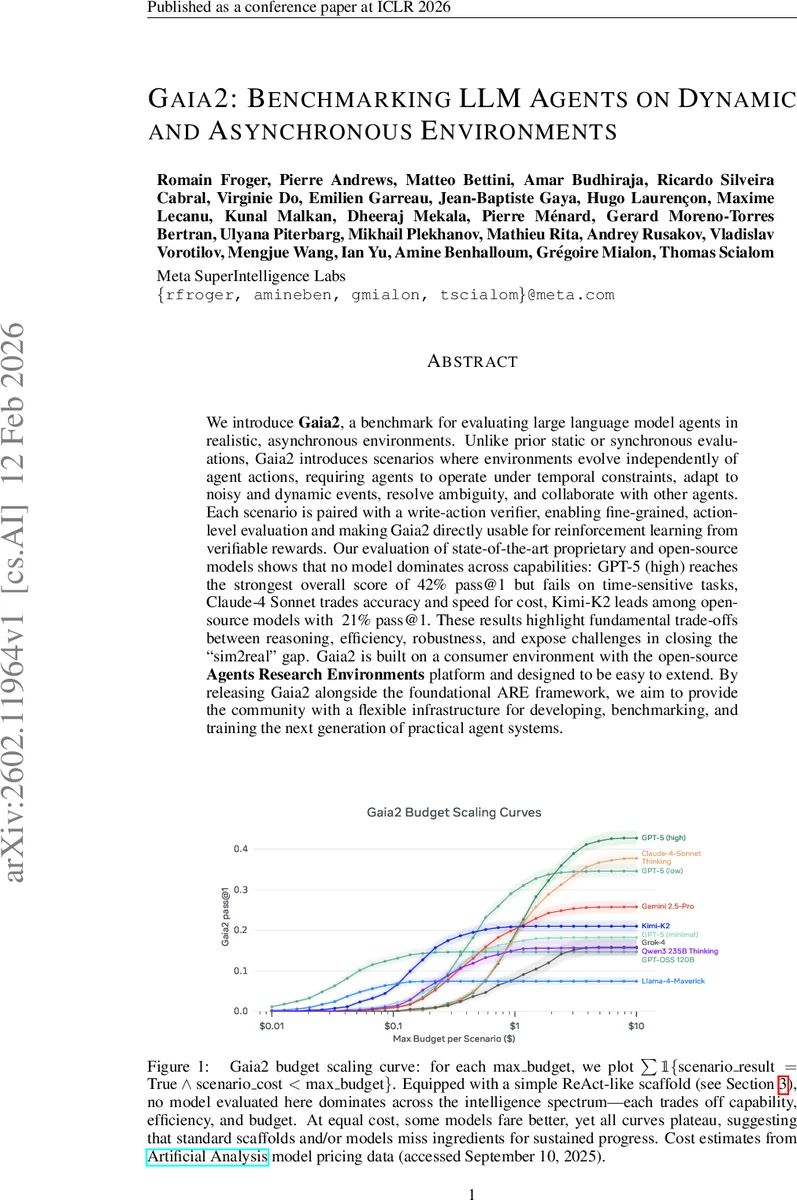
성능 결과는 GPT‑5‑high이 전체 42 % pass@1 로 최고이지만, 시간‑민감 작업에서는 18 %에 불과해 ‘시간 인식’ 능력이 제한적임을 보여준다. Claude‑4‑Sonnet은 비용 대비 정확도·속도 균형을 잡으며, 오픈소스 Kimi‑K2는 21 %로 가장 높은 점수를 기록한다. 전반적으로 어느 모델도 모든 스플릿을 지배하지 못하고, 추론·속도·견고성·비용 사이의 트레이드오프가 명확히 드러난다.
가이아2는 검증 가능한 액션 레벨 피드백을 제공함으로써 RL‑VR(강화학습‑검증 보상) 연구에 바로 활용 가능하도록 설계되었다. 또한 ARE가 기존 τ‑bench, VendingBench 등 다양한 벤치마크를 재현할 수 있음을 보이며, 향후 도메인‑특화 시뮬레이션(데스크톱 자동화, 고객 지원 등)으로 확장 가능성을 입증한다. 현재 한계는 시나리오가 여전히 인간 주석에 의존한다는 점과, 비동기성에 따른 평가 메트릭 설계가 복잡해진다는 점이다. 향후 연구에서는 자동 시나리오 생성, 메타‑리워드 학습, 그리고 다중 에이전트 협업 프로토콜의 표준화가 필요하다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기